



You may not know this, but the data catalog covers five distinct tool types.
- A technical metadata catalog
- A governance platform
- A business glossary
- A self-service discovery tool
- An observability-aware catalog with live reliability signals attached o every asset
Enterprises often run more than one.
Below: 10 data catalog use cases mapped to the catalog type they require, the must-have features for each, and the tools best suited to the job.
What Is a Data Catalog?
A data catalog is a searchable inventory of data assets and their metadata.
It helps analysts, data engineers, and business users find trustworthy datasets by surfacing key attributes such as ownership, definitions, lineage, and quality signals so that they can confirm the datasets' fit for a specific use case.
TWDI describes a data catalog as a digital library of a company’s data, yet catalogs can vary widely in which aspects of data discovery they prioritize:
- Technical catalogs focus on tables, schemas, jobs, and system-level metadata for engineers and platform owners.
- Business catalogs (glossaries) capture business terms, definitions, KPIs, and documentation for analysts and business teams.
- Data governance catalogs denote ownership, stewardship, policies, approvals, and audit trails that support governance workflows.
- Self-service discovery catalogs emphasize search capabilities, often including recommendations and usage statistics.
- Observability catalogs pair catalog context with other reliability signals, such as freshness, anomalies, incidents, and lineage, so users can assess data based on operational health.
Although most catalogs comprise some elements of the first four, the real differentiator is how deeply they delve into automation, lineage, and governance workflows.
Why Your Enterprise Needs a Data Catalog
Ask an analyst where the revenue datasets live, and they'll point them out fast. Ask which one to use, and you'll get a few different answers. This is where a data catalog closes the gap between discovery and trust.
That gap shows up in several ways:
The search problem. Analysts hunt across BI tools, documentation, and Slack threads to locate a dataset that should take seconds to find. A catalog surfaces the right asset before the hunt starts.
Definition drift. Customer, active user, and revenue fracture into competing versions across dashboards and models. A catalog makes definitions visible where people encounter data: on the tables, metrics, and reports they actually use.
The trust tax. When analysts can't confirm a dataset is current, correctly defined, or owned by someone accountable, they run their own validation. Multiply that manual check by team size and report count. A catalog reduces it by attaching ownership, refresh cadence, lineage, and quality signals at the point of use.
Lineage blindness. When a dashboard breaks, engineers manually trace upstream changes and guess at downstream impact. A catalog that records dependencies turns that guess into a known quantity.
Governance on paper. A data catalog anchors ownership, classification, and change history in metadata rather than a slide deck. That distinction separates a governance program that passes an audit from one that reconstructs evidence for one.
These are the problems the use cases below are built to solve.
The Top 10 Data Catalog Use Cases
The traditional data catalog is arguably now a metadata intelligence platform, but its efficacy can vary widely.
As Gartner’s Peer Review site shows, users have clear favorites based on their stated uses and individual needs.
The 10 use cases that follow demonstrate those stated needs, including how data catalog capabilities support data discovery, trust, governance, and self-service access in day-to-day operations.
#1. Root Cause Analysis
A broken dashboard or drifting model sends engineers on a dependency hunt.
Sifflet's AI agents support the detect-triage-resolve cycle by analyzing incident patterns and lineage context to surface likely root causes, cutting the hunt short before it becomes a morning.
Catalog type: Observability catalog
Must-have features:
- Field-level lineage tracing upstream and downstream
- Asset health and incident status appear on lineage nodes
- AI-driven root cause suggestions based on historical incident patterns
Tool: Sifflet's Data Catalog
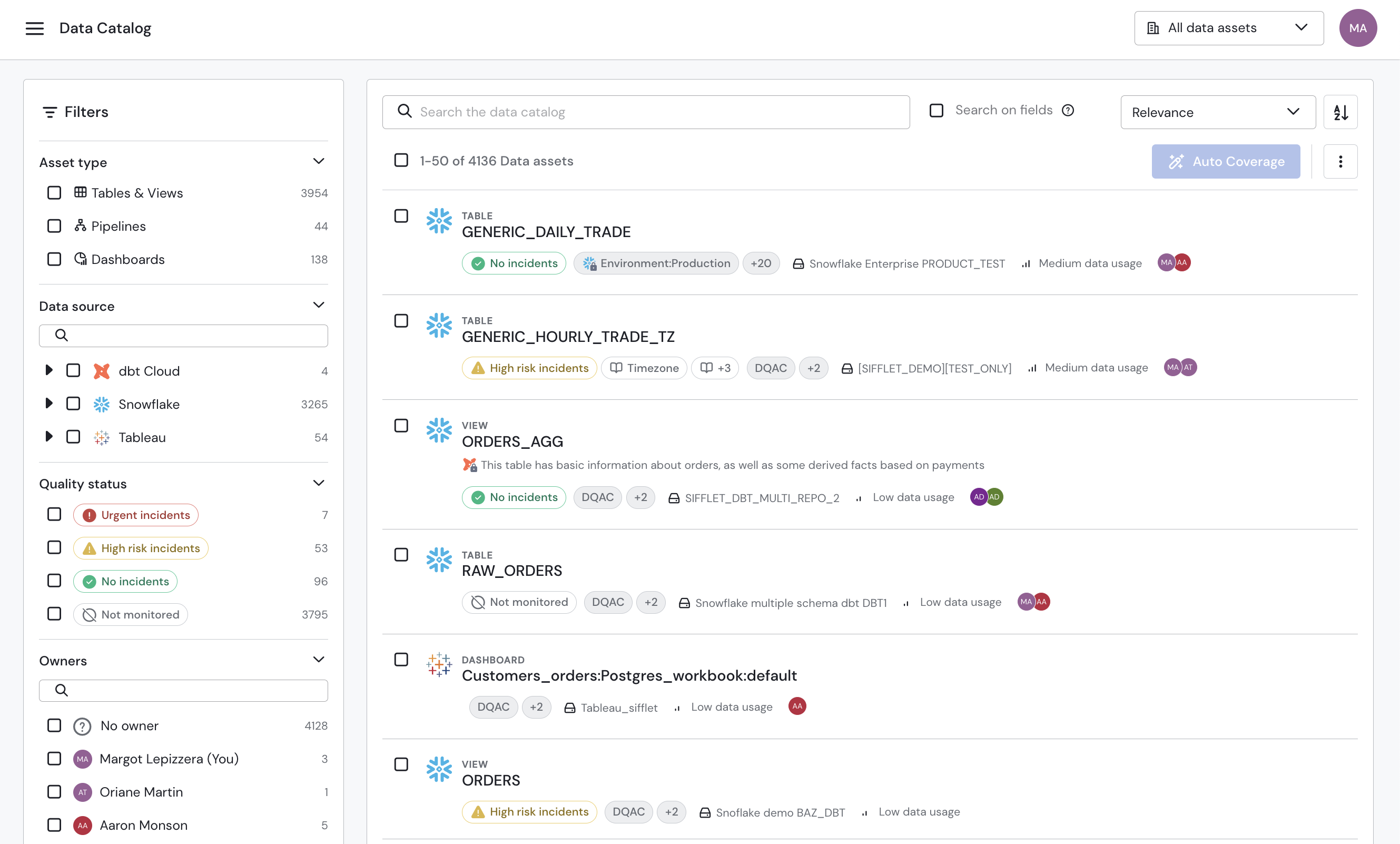
#2. Anomaly Detection
Data degrades quietly.
Sifflet's ML-driven monitors detect anomalies before they reach reporting, then publish incident context and lineage impact directly on the affected asset, so analysts can triage without leaving the catalog.
Catalog type: Observability catalog
Must-have features:
- Monitoring signals on the asset record: freshness, volume, schema, and field-level values
- Health and open-incident status are visible in catalog search results and on asset pages
- Lineage context that shows downstream exposure for the affected asset
Tool: Sifflet's Data Catalog
#3. Data Migration
Migrations are where hidden dependencies surface.
Atlan gives data engineers a complete map of what exists before cutover: asset inventory, dependency mapping, and schema change visibility, so what will break is known before it does.
Catalog type: Technical metadata catalog
Must-have features:
- Comprehensive asset inventory across source and target environments
- Lineage or dependency mapping to assess downstream impact before cutover
- Schema and field change visibility to validate migration fidelity
Tool: Atlan Data Catalog
#4. Data Lineage
Every data engineer has held their breath before hitting the deploy button.
Sifflet computes end-to-end lineage across all connected systems and surfaces field-level connections, so data engineers can trace downstream impact before the change ships rather than after it breaks something.
Catalog type: Technical metadata catalog
Must-have features:
- End-to-end lineage across pipelines, warehouse assets, and BI tools
- Field-level lineage across transformations to trace column-level changes
- Interactive lineage graph to explore dependencies and impact paths
Tool: Sifflet's Data Catalog
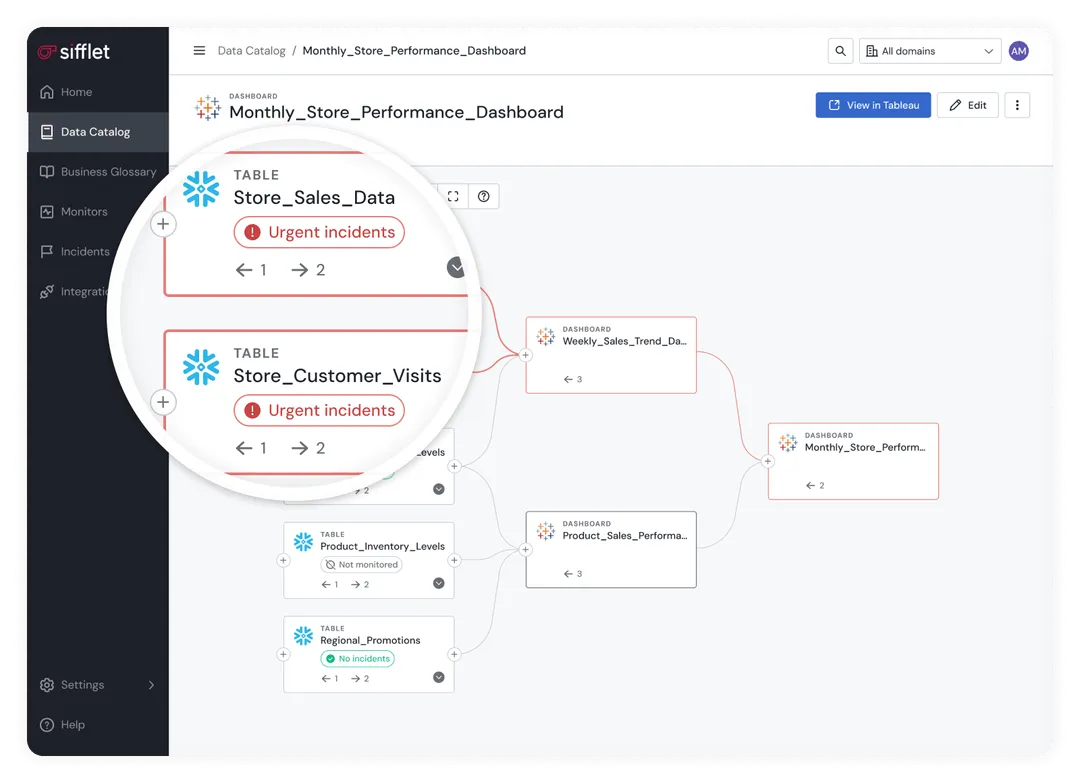
#5. Data Governance
Governance fails when ownership and policy live in slide decks rather than in daily workflow. Collibra brings accountability down to the asset level with governance workflows, stewardship models, and policy management built for enterprise scale.
Catalog type: Governance catalog
Must-have features:
- Ownership and stewardship assignments are tracked on each asset
- Classification and policy tags with an audit trail of changes
- Certification status that signals approved datasets for reuse
Tool: Collibra
#6. Compliance
Regulated data can't rely on memory and manual tagging. Informatica IDMC classifies sensitive fields at the column level, tracks where they flow through lineage, and preserves the audit trail compliance teams need when regulators ask questions.
Catalog type: Governance catalog
Must-have features:
- Automated detection and classification of sensitive data (PII/PHI) at the field level
- Lineage visibility showing where regulated data propagates downstream
- Access and change audit trails tied to regulated assets
Tool: Informatica IDMC
#7. Data Quality Monitoring
Trust gets decided at the moment someone chooses a dataset. Sifflet computes asset health from monitoring coverage and incident severity and surfaces that score on the asset page, so analysts can see whether a table is passing its monitors before the report runs.
Catalog type: Observability catalog
Must-have features:
- Asset health status is visible on the asset page and in search results
- Quality signals tied to monitored fields and tables (freshness, schema, volume, values)
- History of incidents and health changes to track regression over time
Tool: Sifflet's Data Catalog
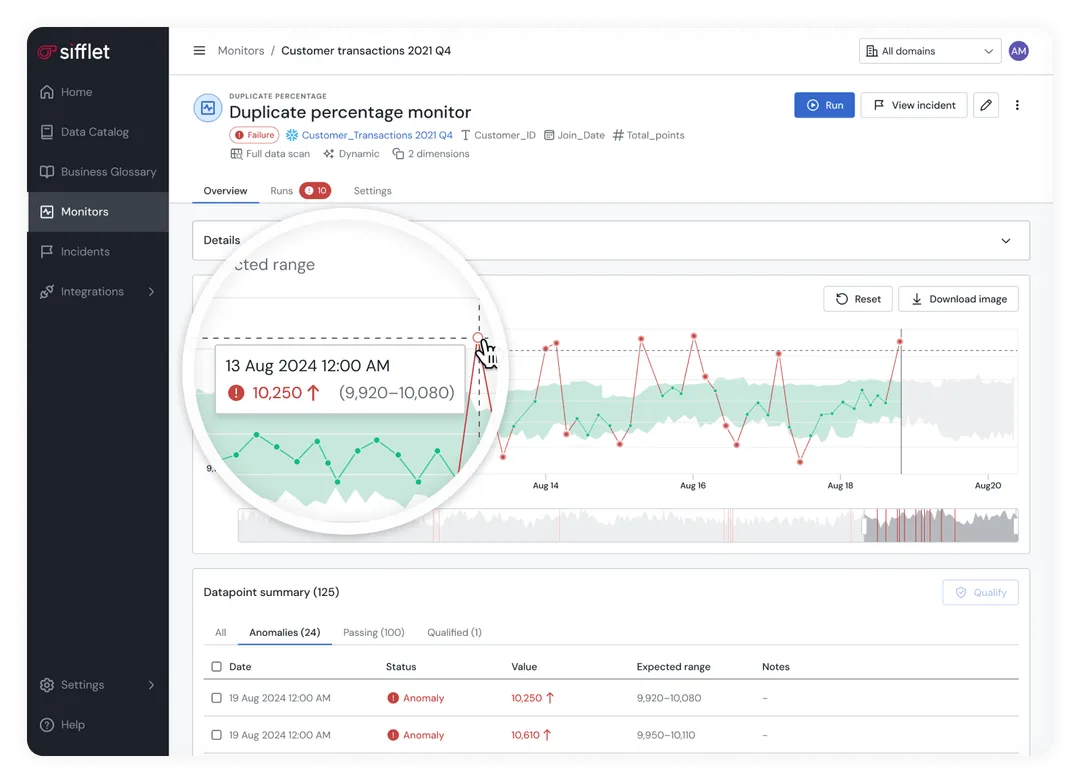
#8. Data Discovery
Search revenue in a catalog without ranked results, and you get a list. Atlan returns the right table first, ranked by certification, ownership, and usage, so analysts spend time analyzing rather than evaluating candidates.
Catalog type: Self-service discovery catalog
Must-have features:
- Relevance-ranked search that weighs usage, certification, and ownership signals
- Clear descriptions and business context on assets to reduce guesswork
- Simple filters for certified, owned, and active assets
Tool: Atlan Data Catalog
#9. Cost Optimization
Somewhere in the warehouse are tables nobody queries, pipelines that process data nobody reads, and jobs that run every night for reports nobody opens. Google Dataplex Universal Catalog surfaces the usage signals that identify them, along with the dependency mapping that confirms they can be retired safely.
Catalog type: Technical metadata catalog
Must-have features:
- Usage signals such as query frequency and last accessed timestamps
- Orphan and duplicate asset identification to target clean-up
- Dependency mapping to confirm deprecation won't break downstream assets
Tool: Google Dataplex Universal Catalog
#10. Self-Service Data
Progress stalls when analysts can't judge the fit or trust the data they’re using. Alation's business catalog puts definitions, certification status, and ownership on the asset itself, so analysts can confirm a dataset's fit without filing a ticket.
Catalog type: Business catalog (glossary)
Must-have features:
- Business terms and definitions mapped to datasets, metrics, and fields
- Certification marking that identifies assets approved for reuse in reporting and analysis
- Ownership is visible, so users know who to contact with questions
Tool: Alation Data Catalog
You'll notice a clear pattern: operational reliability use cases cluster around observability-aware catalogs, while discovery, definitions, and policy management tend to live in catalog-first governance and self-service platforms.
With those use cases in mind, the next step is selecting a catalog that aligns with your priorities, architecture, and how your data is actually used.
Where Sifflet's Data Catalog Fits in Your Stack
Most enterprises don't have one catalog. They have several.
A technical metadata catalog comes baked into the data warehouse: Snowflake's Data Catalog, BigQuery's Data Catalog, or a similar one.
A governance catalog (Collibra, Alation, or Informatica) sits with the compliance team. A business glossary lives with data stewards.
Whatever point solutions the engineering team added to solve specific problems round out the stack.
Each catalog type solves a different problem. The technical metadata catalog knows the schemas. The governance catalog knows the policies. The business glossary holds the definitions.
But none of them knows whether the data is actually trustworthy right now.
That's the gap Sifflet fills.
Rather than replacing existing catalogs, Sifflet feeds real-time reliability signals into whatever catalog the enterprise already uses: freshness metrics, anomaly alerts, incident status, and lineage updates.
Specifically, Sifflet delivers:
- AI-powered RCA agents that handle the detect-triage-resolve cycle, surfacing root cause hypotheses and incident context without requiring engineers to trace dependencies manually
- Field-level lineage from all connected integrations, with health status on every node
- Asset health status in the catalog and lineage views, making quality visible at the moment of data selection
- Active metadata from your full data stack in real time, keeping the catalog current without manual updates
Your data catalog finds the data. Sifflet Data Observability tells you whether you can trust it.
Ready to see how Sifflet connects your catalog to your data quality?

%2520copy%2520(3).avif)















-p-500.png)
