



Definition:
Data lineage is the map of where your data comes from, how it moves, and how it changes over time. It helps answer questions like: “Where did this number come from?” or “If I change this table, who will be affected.”
When there is an error or something breaks in your data systems, knowing where it started and where it went is crucial.
The problem?
Data teams can spend hours, days, or weeks tracking every single affected dashboard.
Data lineage is the trace your data leaves as it flows across your data systems.
It will save your data team hours of tedious work, and business teams from faulty reports.
What is Data Lineage?
Data lineage is a complete map that shows how data moves through your organization, from its original source, through every transformation, to its final use in reports, dashboards, or machine learning models.
It's the documentation that answers critical questions like "Where did this number come from?" and "What will break if I change this data source?"
Without data lineage, your data team will struggle with mysterious data quality issues, conflicting metrics across departments, and hours wasted trying to understand how business-critical numbers are calculated.
With proper lineage tracking, data teams can move faster, trust their data, and make changes with confidence.

For example, let’s say you’re the Head of Analytics at a fast-growing SaaS company in 2025.
Every Monday morning, your C-suite reviews a dashboard showing customer churn rates, revenue trends, and product adoption metrics.
Lately, though, something’s off.
The numbers keep shifting and your C-suite is questioning the data, so you’re spending more time explaining discrepancies than delivering insights or finding solutions.
You decide it’s time to implement data lineage across your stack. By using tools like dbt for transformations and a metadata platform for vizualization, you’re able to map out how data flows from Salesforce and Stripe, through your data warehouse, and into the final executive dashboard.
Within a few weeks, the picture becomes crystal clear. Y
ou discover that the churn calculation pulls from three different tables, each of which are updated at different times.
Marketing’s “active user” definition also conflicts with Product’s, and a recent schema change in Salesforce broke the revenue attribution model. Thanks to lineage, you’re able to fix the inconsistencies and document the business logic.
Now, when your CEO asks “How do we calculate MRR?” you don’t just give the number, you know the entire journey from raw subscription data to the polished metric, building confidence in every single decision that follows.
Why Does Data Lineage Matter?
Data lineage isn’t just a technical tool; it’s a foundation for operational excellence, regulatory compliance, and competitive agility.
Here’s how lineage delivers measurable value across the business:
- Faster root cause analysis
When a dashboard breaks or an AI model behaves unpredictably, data teams can’t afford delays, which often mean risk to a company’s revenue or reputation.
Lineage allows you to act quickly by showing exactly where errors originate, reducing time spent on guesswork to restore trust in business-critical reports or data products like recommendation engines.
2. Stronger confidence across departments
Executives don’t act on metrics they don’t trust.
Lineage surfaces the full data journey, making it easier for business stakeholders to validate numbers and understand context. That transparency builds credibility and improves decision-making at every level.
3. Smarter, safer change management
From updating a data transformation to deprecating a source system, every change has ripple effects.
Lineage helps teams anticipate the downstream impact to minimize disruptions, avoid broken reports, and maintain business continuity.
4. Streamlined compliance and audit readiness
Regulatory requirements like GDPR and SOX demand transparency into how data is handled.
With lineage, teams can quickly demonstrate where sensitive data lives, how it's processed, and who has touched it, saving time, reducing risk, and avoiding costly penalties.
5. AI & ML preparedness
Successful AI initiatives depend on trustworthy data.
Lineage provides visibility into feature provenance, transformation logic, and data quality, helping teams build and scale machine learning systems with confidence, without introducing bias or technical debt.
❝ Data lineage illustrates exactly what a model depends on, how those inputs are prepared, and what else could break downstream. ❞
Types of Data Lineage
Not all lineage supports the same workflows or intents.
There are several different types of lineage, so its important to evaluate what your main intent is when evaluating stand-alone data lineage tools, or tools with embedded data lineage capabilities, like Sifflet.
- Technical lineage
Technical lineage captures the raw flow of data between systems, tables, and columns.
It’s main purpose is to show the mechanical relationships between layers, but it doesn’t explain the business logic behind transformations. This looks like: "Table A joins with Table B, filtered by condition C, then outputs to Dashboard D."
Best for: Data engineers debugging pipeline issues, understanding system dependencies, and optimizing performance.
- Business lineage
Business lineage connects data to business concepts, like “Lifetime Value” or “Monthly Recurring Revenue”.
This helps analysts and executives understand what a metric means, not just where it comes from technically.
Best for: Stakeholders who need to understand business logic, compliance documentation, and cross-team alignment on definitions.
3. Cross-system lineage
Cross-system lineage tracks how data flows across different platforms and environments (like from your CRM to your data warehouse to your BI tool).
This end-to-end view is crucial for organizations with complex, multi-vendor data stacks.
Best for: Understanding complete data journeys, impact analysis across systems, and architectural planning.
- Governance lineage
Focuses on ownership, access controls, data classifications, and policy enforcement throughout the data lifecycle.
It focuses on tracking who is responsible for a dataset, who has accessed it or modified it, and whether it complies with internal policies and external regulations. Governance lineage ties data flows to an accountability framework, answering the questions “Who’s responsible?” and “Is it compliant”?
Best for: Data stewards, legal and compliance teams, and platform owners who need to ensure regulatory alignment, enforce access policies and reduce risk exposure, particularly in highly regulated industries subject to GDPR, HIPAA, and more.
What Tools Do You Need in Your Data Stack?
Building effective data lineage requires the right combination of tools working together. Here's how the pieces fit together:
- Data ingestion tools
These are your entry points, bringing raw data into your platform. Ingestion tools can automatically capture schema information and source metadata that feeds into lineage mapping.
Popular tools: Fivetran, Airbyte, Stitch, custom APIs
- Transformation and modeling
Where raw data becomes usable business information.
This layer is often where lineage provides the most value, as it's where business logic lives and where most data quality issues originate.
Popular tools: dbt, Apache Spark, Dataform, SQL-based transformations
- Metadata management and data catalogs
Data catalogs surface lineage graphs, provide column-level traceability, and offer searchable documentation.
They're the user interface for exploring and understanding your data relationships.
Popular tools: Atlan, Collibra, DataHub, Alation, Apache Atlas
- Observability & monitoring
Data observability platforms offer built-in lineage views to support anomaly detection, root cause analysis, and impact assessment.
They combine lineage with data quality monitoring for a complete operational picture.
Popular tools: Sifflet, Monte Carlo, Anomalo, Great Expectations, custom monitoring solutions
Types of Data Lineage
Data lineage can be captured through several different approaches, each with its own trade-offs:
- Manual documentation
Teams maintain documentation of data flows, transformations, and dependencies.
Although this approach covers everything you need, it is time-consuming, prone to errors, and difficult to keep current as systems evolve.
- Parser-based lineage
Tools automatically scan code (like dbt models, SQL scripts, or ETL configurations) to extract lineage relationships.
This approach scales well but may miss runtime dependencies or complex logic.
- Event-based lineage
Captures lineage from data pipeline execution logs, query history, and system events.
This provides real-time accuracy but requires integration with multiple systems and can generate large volumes of metadata.
- Agent-based lineage
Tools embed lightweight agents throughout your data stack to monitor changes, track data movement, and enrich lineage with operational metadata like execution times and data volumes.
Best-in-class data lineage tools combine multiple approaches to deliver comprehensive, dynamic lineage at both technical and business levels.
How to Implement Data Lineage
You don't have to rebuild your entire system to get started with data lineage, but you do need a thoughtful approach.
Even with powerful automated tools, success depends more on defining scope, selecting the best use cases, and linking lineage to daily workflows than choosing the flashiest platform.
Here are five best practices to guide your data lineage efforts and help you get real value at every step.
Step 1. Start with what hurts
Broken dashboards. Audit pressures. Late or missing KPIs.
These are the real issues your analysts, data governance leads, and executives care about. Once they see data lineage solving complex everyday problems, they'll be far more willing to champion it across the enterprise.
Skip the all-or-nothing approach. Focus on a high-priority use case where lineage solves a painful and recurring problem right now.
Success puts wind in your sails and allies in your corner.
Scale from there.
Step 2. Trace the flow
Once you've identified a high-impact use case, pinpoint the systems and tools that support it.
Focus on the core components: where data enters, how it's transformed, where it's stored, and how it's consumed. Think sources, pipelines, storage layers, and reporting tools.
You don't need a full-blown system map, just a focused inventory of what matters most to the flow you're tracking.
Step 3. Define your metadata
Data lineage runs on metadata. But not all metadata is created equal.
Missing fields. Inconsistent formats. Siloed sources. These are the barriers that break lineage and block visibility.
Define clear standards for formatting metadata across schemas, queries, and transformations, and determine how that metadata is stored. Everyone must agree on what's documented, how it's formatted, and where it's kept.
Consistency and clarity give data lineage the structure it needs to trace data from end to end.
Step 4. Let tech do the heavy lifting
Forget spreadsheets and sticky notes. Manual lineage doesn't scale.
Consider tools that automate discovery to keep data lineage current across every environment. Look for platforms that integrate seamlessly with your pipelines, orchestration layers, and query logs.
For example, Sifflet delivers active, end-to-end lineage by mapping dependencies across modern data stacks.
It automatically traces how data flows and transforms, offering real-time visibility when issues surface and faster impact assessment when things change.
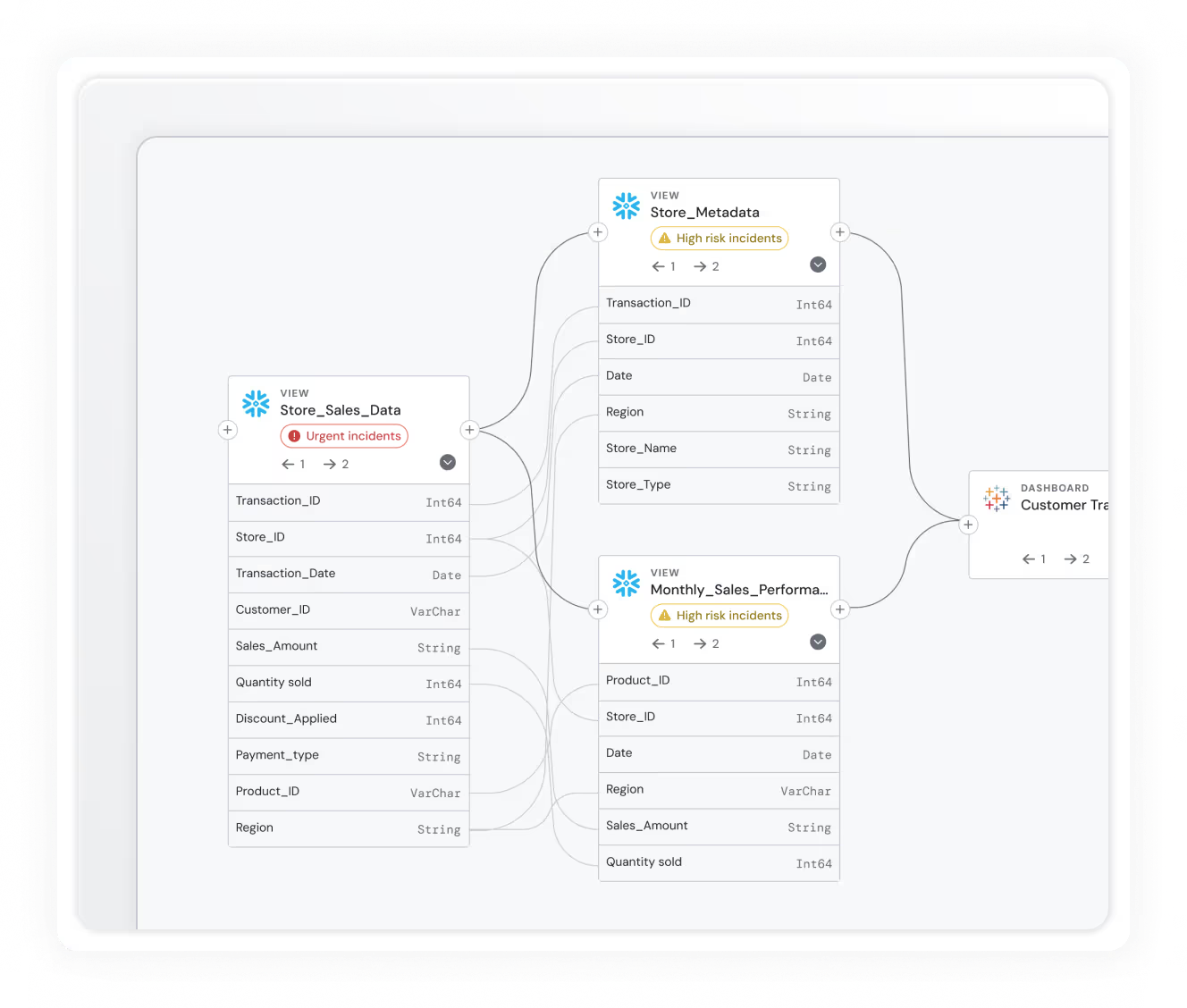
5. Turn data lineage into leverage
Don't treat data lineage like a static diagram or a pretty visual.
Put lineage to work in root cause analysis, impact assessments, and governance workflows. Make it available to the people who need it most: engineers resolving incidents, analysts checking upstream dependencies, and governance leads preparing for audits.
Data lineage is a core component of modern data observability. Combined with real-time monitoring, anomaly detection, and quality alerts, it's a powerful diagnostic tool, spotlighting data issues, tracing their origins, and evaluating their downstream impact with speed and precision.
How Does Data Lineage Power Data Observability?
Data lineage goes beyond documentation tool and supplies context and connection for something far more potent.
Data observability platforms monitor and report on the health of your stack in real-time: freshness delays, schema changes, and volume drops that indicate trouble.
Data lineage links those alerts to their root cause, allowing you to trace the origin and impact of those troubles wherever they go. This turns firefighting to fire prevention.
Most tools stop at the table level, demonstrating how datasets relate.
However, Sifflet goes deeper using automated field-level lineage to map how individual columns connect across tables.
This level of granularity turns signals into insight. With real-time alerts and field-level lineage:
- Engineers can pinpoint the root cause of incidents in seconds, tracing failed jobs across pipelines to identify the exact transformation that broke.
- Analysts can assess data quality in context, quickly determining whether a dropped KPI stems from an upstream schema change or a delayed data source.
- Product teams can catch metric anomalies in real-time, trace them to their source, and pause a feature roll-out before bad data drives the wrong decision.
Data lineage brings clarity, context, and speed to data observability, turning signals into action.
Data Lineage Tells the Story of Your Data
Data lineage connects the dots between your data, tools, people, and decisions by tracing how information is sourced, shaped, shared, and applied.
It turns complexity into clarity, helping you data teams solve issues quickly, offering accurate impact assessments, and adding a layer of transparency into compliance and auditing.
The story of your data is already being written.
Data lineage makes sure it's one you can read, trust, and act on.
Want to cut troubleshooting time, build trust in your reporting, and make auditing a breeze? Find out how Sifflet brings data lineage to life.
















-p-500.png)
