




The traditional data catalog helped break down data silos by reaching into murky spaces to ferret out hidden data. But all anyone ever received was a list of assorted assets.
If you were lucky, you might have found tables with a README file from 2007, or a SharePoint page telling you to try using this, but don't EVER use that.
But that was it. No documentation, no definition, and no way to judge whether what you saw was even relevant.
Data scientists spend upwards of 80% of their time cleaning up messy data rather than running analyses or generating insights.
Data catalogs are now being expanded into what many now call metadata catalogs or data intelligence platforms.
What is a Metadata Catalog?
A metadata catalog is a centralized management system that collects, indexes, and governs the context of an organization's data assets using metadata and automation.
It harvests technical metadata (physical structure, usage statistics, and file properties) and enriches it with business context (definitions, ownership, and quality scores). In doing so, metadata catalogs establish a "trust layer" that makes data discoverable, accessible, and easy to evaluate for use.
These modern platforms serve as the discovery tool for every layer of the stack, including the data lake. This makes it the central data lake metadata catalog, organizing and governing assets stored across distributed, schema-flexible environments.
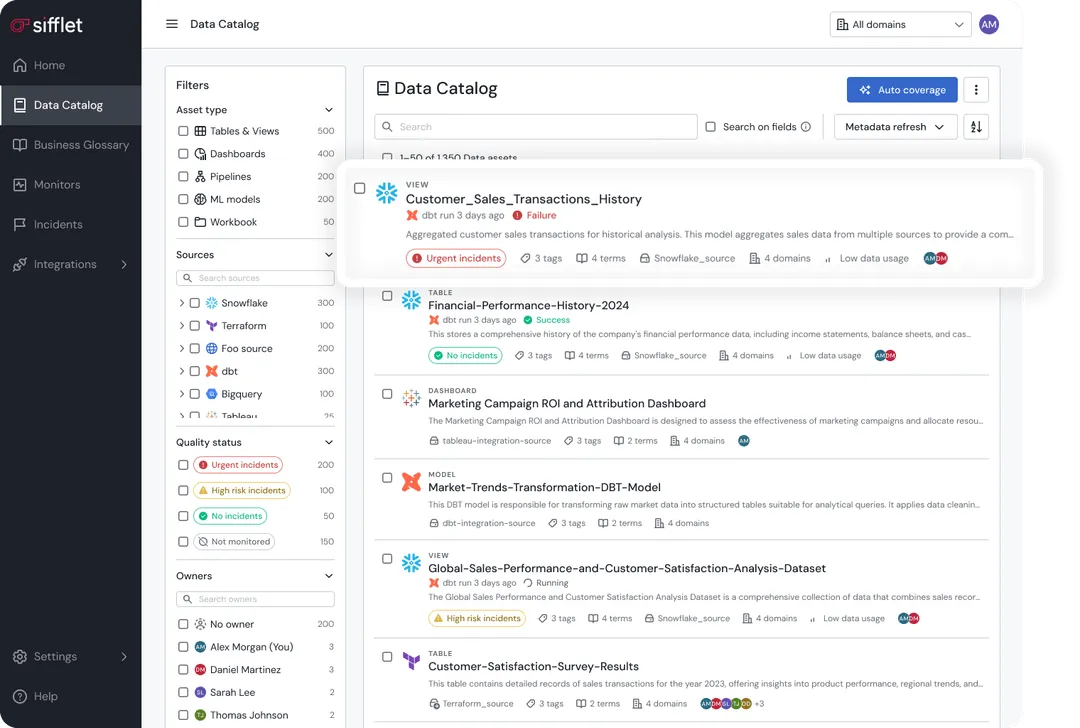
What Do Metadata Catalogs Actually Do?
A modern data catalog allows true data discovery by letting users find tables not only by name but also by business terminology.
It provides clarity on ownership, usage, and suitability for specific use cases before any analysis begins.
Alongside discovery, it supports quality and trust assessment by showing quality scores, certification status, and data freshness so users can quickly determine which tables are appropriate for reporting and which are better suited for exploratory work.
The catalog also offers automated impact analysis, allowing users to see which dashboards and reports depend on a table before they modify or query it.
Lineage visibility further enhances understanding by tracing data from its source through transformations to its final destination, revealing how upstream tables feed critical reports.
Compliance and access control features help identify datasets containing sensitive or regulated information and clarify who can access them.
Behind the scenes, automated metadata management keeps everything up to date by continuously ingesting technical metadata such as refresh schedules, schema changes, and query patterns, therefore eliminating the need for manual upkeep.
How Have Data Catalogs Changed?
If you're in the market for catalogue tools, you might hear the terms "Data Catalog" and "Metadata Catalog" bandied about interchangeably.
Yet, the distinction between the two is as profound as that between a roadmap and a GPS.
Early data catalogs were built purely for discovery. They acted like search engines, scanning databases to list available tables. While they helped users find data, they offered no context as to their contents, origins, or reliability.
The next wave of data catalogs sought to fill the context gap by adding collaboration features such as wikis, user ratings, and manual tagging.
While its intentions were noble, it just didn't scale.
That brings us to the modern metadata catalog.
It solves the scaling problem by moving from manual metadata entry to automated ingestion, tagging, and curation.
Rather than relying on people to update a table's status, Gen 3 catalogs ingest active metadata from lineage parsers, observability tools, and query logs to ensure the catalog reflects the latest state of the data, not its state six months ago.
Some modern catalogs enhance this with AI capabilities such as automatically detecting PII, inferring data lineage relationships, or scoring data quality, but its real value lies in real-time, automated metadata ingestion and updates.
The real hero of the metadata catalogs is the active metadata it now employs.
When a schema changes, quality issues arise, or new sources appear, the catalog automatically updates lineage, quality scores, and governance metadata in real time.
Active catalog metadata and automated metadata harvesting have transformed the data catalog from a rote list of tables and files into a dynamic inventory of curated data assets, ready for discovery.
Metadata Strategy: Why the Tool Alone Isn't Enough
Acquiring a metadata catalog doesn't mean your job is done. It's only as powerful as the metadata strategy that guides it.
But how can a strategy actually influence your metadata catalog?
Take this example:
An analyst is building a revenue forecast for the Board.
Without strategy:
The analyst searches "Revenue," and the catalog returns a long list of tables. They open the first one to inspect the columns. Nothing in the schema confirms whether it includes tax adjustments. They open the second. Same problem.
They flip through lineage diagrams to see where each table came from, but the lineage shows only technical hops.
The result: the data analys can be searching for hours or day with no clear answers.
With Strategy in Place:
The analyst searches "Revenue" and fetches three results:
- Revenue (ERP) [Top Result]
- Owner: Finance Team
- Definition: Official company revenue, tax-adjusted, used for financial reporting
- Last Updated: 2 hours ago
- Quality Score: 99%
- Use Cases: Board reporting, SEC compliance, financial statements
- Lineage: [Click to see full journey]
- Revenue (Analytical)
- [Metadata shown, but dimmed to indicate secondary tier]
- Revenue (Raw Salesforce Feed)
- [Metadata shown, clearly marked as exploratory only]
The ERP table marked as ERP, owned by Finance, and certified for reporting, guides the catalog to place it at the top of the fetched results.
The analyst sees it instantly and knows it's the correct data to use. No emails. No confusion. No delays.
A thoughtful metadata strategy solves the problem that organizations have faced for decades: how to make data both discoverable AND trustworthy at scale.
Skimp or skip on the strategy, and you'll end up with a data junkyard.
If you install a metadata catalog and switch on the automated crawlers, within weeks, you have complete coverage. All 10,000 tables indexed. All 50,000 columns cataloged. Files and objects, galore.
You've achieved 100% Automation, but 0% Differentiation.
The 80/20 Principle
A metadata strategy is instructional for both teams and tools. And with the right strategy, automation and human governance multiply the effectiveness of each.
What Machines Do (The 80%): Handle Scale
Metadata catalogs excel at ingesting technical metadata. Automated metadata harvesting captures:
- Schema
Scanning all databases to identify every table, column, schema, and data type across your entire data estate.
- Usage analysis
Tracking query logs, data access patterns, and which users and tools access which data.
- Operational metadata
Monitoring data refresh schedules, pipeline execution times, error rates, and data volumes.
- Lineage tracing
Tracing SQL code and data transformations that map the journey of data from source to destination.
- Quality metrics
Running data profiling to identify completeness, uniqueness, and consistency automatically.
But machines can't define business context.
What People Do (The 20%): Add Context and Trust
An algorithm can tell you "Column FY23_REV exists," but it doesn't account for:
- Semantics: Does FY24_REV include tax adjustments, or is it gross revenue?
- Quality: Is this the version used for Board-level reporting?
- Suitability: Is this table fit for calculating churn, or just for raw transaction logging?
- Accountability: Who is the human owner responsible if this number is wrong?
- Compliance: Does this dataset contain sensitive PII that restricts it from being exported?
- Lifecycle: Has this table been deprecated in favor of a newer version?
Those questions require human involvement and judgment.
How to Define Your Metdata Strategy With 3 Decisions
Your metadata management strategy consists of three deliberate, intentional decisions that provide the business context most data users need.
Decision 1: Classify Data by Business Criticality
Classify data based on its impact on strategic decisions and governance burden:
- Tier 1 (Critical)
Data that drives external decisions or carries regulatory/revenue impact. Requires full governance investment, detailed definitions, certification, and deep lineage.
- Tier 2 (Important)
Data used for internal decisions and analytics. Requires moderate governance: baseline definitions, ownership assignment, and quality monitoring.
- Tier 3 (Standard)
Data used by individual teams or exploratory analysis. Requires minimal curation of technical metadata only, basic ownership.
These decisions should align with your existing data governance and risk frameworks.
Decision 2: Define Ownership and Accountability
Reliable data requires direct accountability. This can be achieved by assigning explicit ownership over every dataset in its metadata.
The Data Owner is responsible for:
- Data quality
- Updating the dataset
- Maintaining definitions and business context
- Approving or updating certifications
- Ensuring access and usage standards are applied
With ownership embedded directly in the metadata, users who have questions or spot issues know exactly who to contact.
Decision 3: Decide Metadata Terminology and Taxonomy
Before you start cataloging anything, decide on the terms and labels you intend to use, and hold everyone to them.
For example:
- Do we call it "Client," "Customer," or "Account"?
- What tags indicate data quality levels? (Certified, Trusted, Experimental)
- How do we identify the purpose of data? (Reporting, Analytics, Operational)
This step eliminates ambiguity at the source.
Once these decisions are made, automation continuously ingests raw metadata across the entire data estate, ensuring all technical details stay current.
Human curation then adds the strategic layer by classifying assets, applying consistent vocabulary, assigning ownership, and defining business meaning.
This creates a scalable catalog: automation delivers complete coverage, indexing every table, schema, and lineage path, while human input ensures critical data has trustworthy context.
Maintenance becomes sustainable because people focus on strategic stewardship, and automation handles routine updates.
How to Apply Metadata Tagging
Metadata catalogs rely on tagging to organize and interpret metadata.
Metadata tagging is the practice of applying standardized labels to digital data assets. These labels capture key metadata signals that a catalog uses to classify, filter, and interpret each asset.
Without consistent tagging, your strategy (and metadata) remains invisible. With it, governance decisions ripple through your entire data stack automatically.
Tags are applied through a hybrid approach:
Automation applies technical tags.
The metadata catalog automatically captures and applies tags for schema information, usage patterns, data quality metrics, and lineage, thus providing complete coverage across all assets.
Humans apply governance tags.
Data stewards manually assign tags for ownership, certification status, and business context, so they can focus their effort on the assets that matter most.
For a more definitive rundown on how to design, implement, and maintain metadata tags at scale, see our detailed guide on metadata tagging strategy.
Metadata Catalogs Take Inventory to Intelligence
Metadata catalogs bring order and trust to complex data environments, but the tool alone can't get you there.
Metadata catalogs provide the automation.
Human judgment provides context and control.
Metadata catalogs guide users not only to discovery, but to confident, accurate data selection.
Discover how Sifflet Data Observability enriches your metadata catalog with real-time observability signals, automatically keeping quality scores, lineage, and refresh metrics up to date so your metadata always reflects the current state of your data.
Visit our Resource Hub to explore guides, customer stories, and practical frameworks that help you build a more reliable data ecosystem.















-p-500.png)
