
Enterprise-ready data observability, without the learning curve
Validio brings interesting ideas to the table. But when it comes to fast deployment, scalable AI features, and cross-team usability, Sifflet is the platform that gets chosen, again and again. Here’s why modern data teams make the switch.



















Built for Speed, Clarity, and Collaboration
Sifflet stands out by making data observability not just powerful, but truly usable. While Validio requires technical expertise to unlock its full potential, Sifflet is built for speed, clarity, and collaboration.
Its AI agents proactively surface what matters, its alerts come with context, not confusion, and its interface is designed so both engineers and business users can get value from day one.
No steep learning curve, no wasted time, just fast, scalable observability that fits into how your team already works.






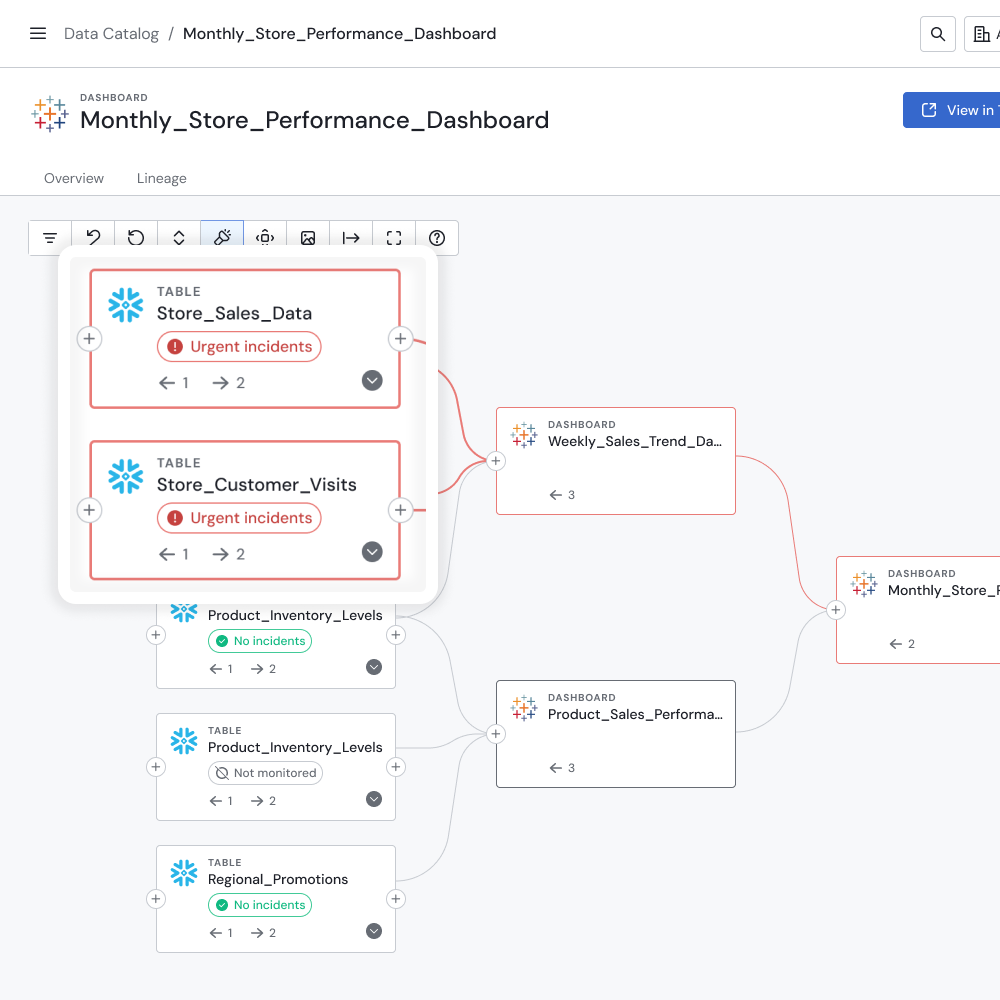
Power is Good. Usability is Better.
If you're looking for a data observability platform that’s intuitive, scalable, and AI-ready from day one, Sifflet is your answer. Validio offers power, but Sifflet delivers clarity, speed, and business alignment.


End-to-end observability from ingestion to BI, including pipelines & metrics
Strong coverage focused on cloud data warehouses

AI-assisted triage with impact mapping and suggested actions
Basic diagnostics, requires manual investigation
Full-column, cross-system lineage enriched with business context
Limited lineage with technical focus
Embedded catalog with contextual metadata, custom tags, and annotations
Foundational metadata capabilities
Contextual, low-noise alerts surfaced in Slack, email, and downstream tools
Highly configurable, but setup can be complex
Designed for scale and simplicity across both tech and business teams
Flexible but technical; not always intuitive at scale
Broad integration set: warehouses, orchestration, BI, ticketing, and more
Covers core warehouse tools (BigQuery, Snowflake, etc.)
There's no one size fits all.
When it comes to data observability platforms, there's no one size fits all.
Chat with one of our experts today to learn more about Sifflet and if it's the right option for you.


What impressed us most about Sifflet’s AI-native approach is how seamlessly it adapts to our data landscape — without needing constant tuning. The system learns patterns across our workflows and flags what matters, not just what’s noisy. It’s made our team faster and more focused, especially as we scale analytics across the business.


"Sifflet has been a game-changer for our organization, providing full visibility of data lineage across multiple repositories and platforms. The ability to connect to various data sources ensures observability regardless of the platform, and the clean, intuitive UI makes setup effortless, even when uploading dbt manifest files via the API. Their documentation is concise and easy to follow, and their team's communication has been outstanding—quickly addressing issues, keeping us informed, and incorporating feedback. "


"Sifflet serves as our key enabler in fostering a harmonious relationship with business teams. By proactively identifying and addressing potential issues before they escalate, we can shift the focus of our interactions from troubleshooting to driving meaningful value. This approach not only enhances collaboration but also ensures that our efforts are aligned with creating impactful outcomes for the organization."


"Having the visibility of our DBT transformations combined with full end-to-end data lineage in one central place in Sifflet is so powerful for giving our data teams confidence in our data, helping to diagnose data quality issues and unlocking an effective data mesh for us at BBC Studios"


"Sifflet has transformed our data observability management at Carrefour Links. Thanks to Sifflet's proactive monitoring, we can identify and resolve potential issues before they impact our operations. Additionally, the simplified access to data enables our teams to collaborate more effectively."

"Using Sifflet has helped us move much more quickly because we no longer experience the pain of constantly going back and fixing issues two, three, or four times."









Frequently asked questions













-p-500.png)
