



7 Data & AI Predictions for 2026
Every year, we see predictions about the death of SQL, the rise of the lakehouse, or some new paradigm that will change everything. Most don't pan out.
But 2026 feels different. Not because of hype, because of convergence. The forces that have been building for years are finally reaching critical mass: open table formats are mature, AI capabilities are production-ready, and the integration tax of the 50-tool data stack has become unbearable.
Here's what I see coming grounded in conversations with hundreds of data leaders, patterns from our work at Sifflet, and the tectonic shifts happening across the industry.
Prediction 0: The Basics Still Matter
Before we get to the exciting stuff, let's ground ourselves in reality.
Schema changes will still break pipelines. NULL values will still corrupt reports. Volume anomalies will still happen on weekends when no one's watching.
According to Gartner, organizations estimate that poor data quality costs them an average of $12.9 million per year. Many research reports found that data teams spend up to 40% of their time on data quality issues, time that could be spent on strategic work.
The gap between 'what's possible' and 'what's deployed' is massive. Most teams are still struggling with basic volume and freshness checks.
The difference in 2026 won't be whether these problems exist. They will. The difference will be whether you detect them in minutes or days, and whether you fix them manually or automatically.
That's the common thread through everything that follows.
Prediction 1: Open Table Formats Win, But Metadata Becomes the Battleground
The storage layer debate is over. Iceberg, Delta Lake, and Hudi have won. Parquet is the lingua franca. The question of "where do I store my data?" has a clear answer.
But here's what's happening now: the war is shifting upstream. Whoever owns the metadata layer owns the intelligence layer.
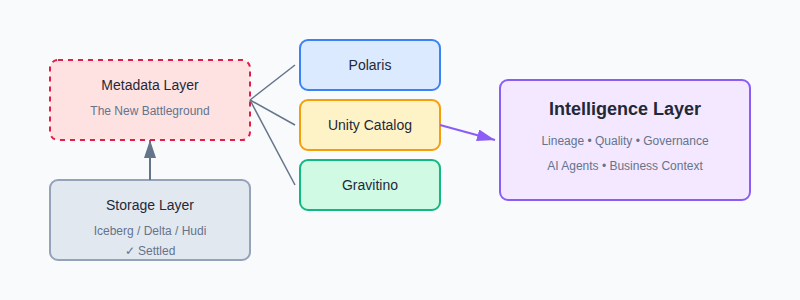
The metadata layer is where the next battle will be fought.
Look at what's happening:
Snowflake launched Polaris as an open catalog for Iceberg. Databricks is pushing Unity Catalog as the universal governance layer. Apache Gravitino (incubating) is positioning itself as the vendor-neutral alternative.
Why does this matter? Because the catalog isn't just a technical component anymore, it's becoming the operating system for data. Lineage, quality rules, access policies, business context all of it lives in the metadata layer.
If your observability tool doesn't understand Iceberg table evolution, time-travel, and partition metadata natively, it's already obsolete.
The implication: data observability built on open formats will win over tools that treat Iceberg as an afterthought. Native integration isn't a feature, it's table stakes.
Prediction 2: The 50-Tool Data Stack Collapses Into 5 Platforms
We've hit peak tool fatigue.
The average enterprise data team manages 15-30 different tools. Ingestion, transformation, orchestration, quality, cataloging, governance, visualization, each with its own vendor, its own UI, its own way of thinking about the world.
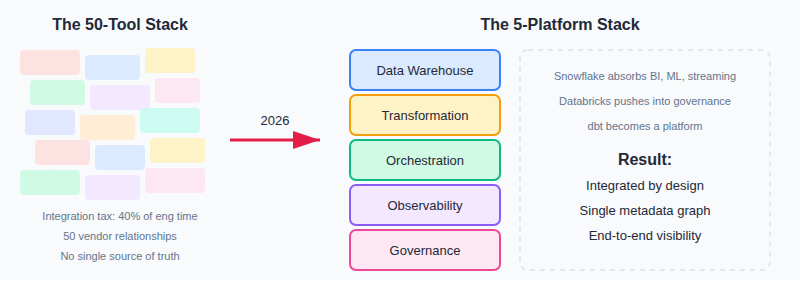
Consolidation is accelerating across the data stack.
The integration tax is killing productivity. According to Fivetran's research, data engineers spend 40% of their time on integration work rather than building value. That's not sustainable.
In 2026, consolidation accelerates:
Snowflake absorbs more—notebooks, streaming, ML serving. Databricks pushes deeper into governance and BI. dbt Labs evolves from a tool into a platform with the Semantic Layer and dbt Cloud. Point solutions get acquired or struggle for relevance.
If you're building a point solution in 2026, you're building an acquisition target, not a company.
The winners will be platforms that span ingestion → transformation → serving → observability with a single metadata graph. Not because bundling is better, but because integration is that painful.
Prediction 3: Data Quality Becomes a Business Function, Not an Engineering Task
Here's a question I ask every data leader: "What's the revenue impact when your data pipeline fails?"
Most can't answer. They can tell me which table had NULL values, which job failed, how long the SLA breach lasted. But they can't connect that to the CFO's dashboard being wrong or the ML model serving bad recommendations.
That changes in 2026.
Data quality moves from engineering metrics to business outcomes. SLAs get defined in business terms; revenue at risk, customers impacted, decisions delayed.
Gartner predicts that by 2026, 80% of organizations will deploy data quality solutions that leverage AI/ML capabilities. But the bigger shift is organizational: the CDO owns reliability tied to business outcomes, not just the data engineering team.
Data contracts; formalized agreements about schema, freshness, and quality between producers and consumers become standard. Not because they're trendy, but because without them, there's no accountability.
If your quality tool can't answer 'what's the revenue impact of this failure?', it's not solving the actual problem.
At Sifflet, this is core to how we think about observability. Connecting technical anomalies to business context isn't a nice-to-have, it's the whole point.
Prediction 4: AI Agents Replace Dashboards for Data Operations
This is the prediction I'm most convinced about.
For 20 years, data observability has meant dashboards. Something breaks, you get an alert, you open a UI, you investigate manually. Maybe you find the root cause in an hour. Maybe it takes all night.
That model is broken.
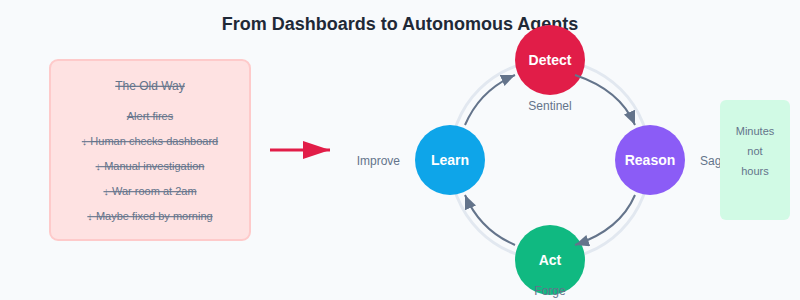
The shift from reactive dashboards to autonomous agents.
In 2026, AI agents handle the operational burden:
Detection that understands business context, not just technical metrics. Investigation that traverses lineage automatically, correlating signals across systems. Resolution that applies fixes, validates results, and learns from every incident.
The 2am war room becomes a Slack notification: "Issue detected in revenue pipeline. Root cause: upstream schema change in CRM sync. Fix applied. Validation passed."
Detection is commoditized. Every tool can tell you something broke. Reasoning and action are the new moats.
This isn't about adding a chatbot to your existing tool. It's about fundamentally rethinking what observability means when AI can do the investigation work.
Prediction 5: AI Rewrites the Data Infrastructure Playbook
Here's a truth that's uncomfortable for some in our industry: the data stack was built to serve dashboards. It was not built to serve AI.
But AI is now the primary consumer of data in many organizations. Feature stores, embedding pipelines, RAG architectures, fine-tuning datasets, these have different requirements than the BI workloads we optimized for.
AI models are less forgiving of bad data than humans reading dashboards. A human can see an outlier and ignore it. A model trains on it.
In 2026, we see two types of companies:
AI-native: Infrastructure rebuilt from the ground up to serve AI workloads. Quality validation at write time, not read time. Semantic richness built into the metadata. Lineage that tracks not just tables but features and embeddings.
AI-bolted-on: Traditional data stacks with AI capabilities added as an afterthought. Chatbots on dashboards. Copilots that generate SQL but don't understand business context.
Every data tool will have an AI layer in 2026. But most will be a wrapper, not native. The difference matters.
The companies that win aren't adding AI to their product. They're rebuilding for AI from the ground up.
Prediction 6: The Semantic Layer Finally Has Its Moment
For years, the semantic layer was a nice-to-have. Something sophisticated teams implemented but most ignored.
AI changes the calculus.
Here's the problem: when you ask an LLM to generate a query for "revenue by region," it needs to know what "revenue" means in your organization. Is it gross or net? Does it include refunds? Which tables have the canonical definition?
Without a semantic layer, text-to-SQL is just guessing.
dbt's Semantic Layer, Cube, AtScale, these solutions solve the "different numbers in different dashboards" problem that has plagued analytics teams for decades. But the AI use case makes them essential, not optional.
The semantic layer is where business logic lives as code, not tribal knowledge. AI agents need this context to be useful. Data quality tools need it to validate what matters, not just what exists.
The semantic layer becomes the bridge between technical data and business meaning. AI can't cross that bridge without it.
The Common Thread
If there's one theme across all seven predictions, it's this:
Data infrastructure is evolving from passive to active.
Passive: store, transform, visualize, wait for humans to notice problems.
Active: understand, reason, act, learn from every interaction.
The platforms that win will be those that embed intelligence into every layer, not bolt it on after the fact. That means:
• Metadata that understands business context, not just technical schemas
• Quality that connects to revenue impact, not just row counts
• Observability that investigates and resolves, not just alerts
• Infrastructure built for AI workloads, not retrofitted
The basics still matter. Schema changes will still break things. But how you detect, investigate, and resolve those issues, that's where the game is being won.
Want the full story, with examples and how to prepare?
In the webinar, I go deeper on each prediction, including:
- What these shifts look like inside real stacks
- The failure patterns most teams miss until it is painful
- The “2026 readiness checklist” I would use as a CDO
- What to consolidate, what to keep, and what to stop doing
👉 Watch the webinar to get the full breakdown.
What predictions would you add? What feels obvious, and what feels wrong?












-p-500.png)
