



The data observability market has a dirty secret: most platforms can tell you what broke, but they can’t tell you why it matters or what to do about it.
This is the paradox of modern data observability. We’ve built sophisticated systems that generate thousands of alerts, capture extensive metadata, and create beautiful lineage graphs. Yet data teams are overwhelmed, business stakeholders are disconnected, and the time-to-resolution for critical incidents hasn’t improved meaningfully in years.
The problem isn’t more monitoring. It’s that traditional observability treats data reliability as purely a technical problem, when it’s fundamentally a business problem.
The False Promise of “More Coverage”
Walk into any data team today and you’ll hear the same pain points:
“We can’t monitor everything, we’d drown in alerts.” Most teams monitor their top 200–300 critical tables and hope for the best. The rest of their data estate runs dark, creating blind spots where critical business issues hide
“When something breaks, we spend hours figuring out what’s actually affected.” A failed dbt model triggers 15 downstream monitors. Which failure actually matters? Which teams are impacted? The observability platform can’t tell you, it just knows something is red.
“By the time we know there’s a problem, business stakeholders are already asking questions.” The sales VP’s dashboard is stale, but the data team discovers this only after the 9am executive meeting has already happened.
“We know what broke, but not why or how to fix it.” Root cause analysis means manually tracing through pipelines, checking logs, debugging queries, and hoping someone on the team has seen this before.
These aren’t edge cases. This is the daily reality of data reliability work. And traditional observability, built for infrastructure monitoring and adapted for data, can’t solve it.

Why Traditional Observability Falls Short
Data observability platforms today excel at one thing: detection. They’re sophisticated alert generators. But detection alone doesn’t create reliability.
Consider what happens when a monitor fails in a typical observability platform:
- Alert fires → Someone gets paged
- Triage begins → “Is this real? How bad is it? Who’s affected?”
- Investigation starts → Checking lineage, logs, recent changes
- Root cause analysis → Usually manual, often time-consuming
- Fix implementation → Hope someone knows what to do
- Prevention → Maybe we create another monitor?
This workflow has three fundamental flaws:
It’s entirely reactive. Nothing happens until after the failure. Business impact is already occurring.
It’s designed for technical users only. Business stakeholders can’t understand the alerts, can’t assess impact themselves, and can’t participate in prioritization decisions. They’re dependent on data teams to translate everything.
It requires humans for every step. From triage to investigation to resolution, every incident demands human time and expertise. This doesn’t scale, and it definitely doesn’t scale to monitoring your entire data estate.
The result? Data teams are stuck in an impossible position: monitor more and drown in alerts, or monitor less and miss critical issues.
Enter: Intelligent Data Reliability
What if instead of just detecting failures, your observability platform could:
- Decide what to monitor based on what actually matters to your business
- Understand business impact the moment something fails
- Investigate root causes automatically while you sleep
- Recommend specific fixes based on what worked before
- Take action when appropriate, with your approval
This is what AI agents make possible. Not chatbots. Not copilots. Agents, autonomous systems that can reason, act, and learn.
At Sifflet, we’re building three agents that work together as an integrated system for intelligent data reliability:
Sentinel: The Monitoring Agent
What it does: Analyzes your data assets and automatically recommends the right monitors to create.
Why it matters: Most teams only monitor 10–20% of their data estate because manual monitor creation is tedious and requires deep technical knowledge. Sentinel eliminates this bottleneck.
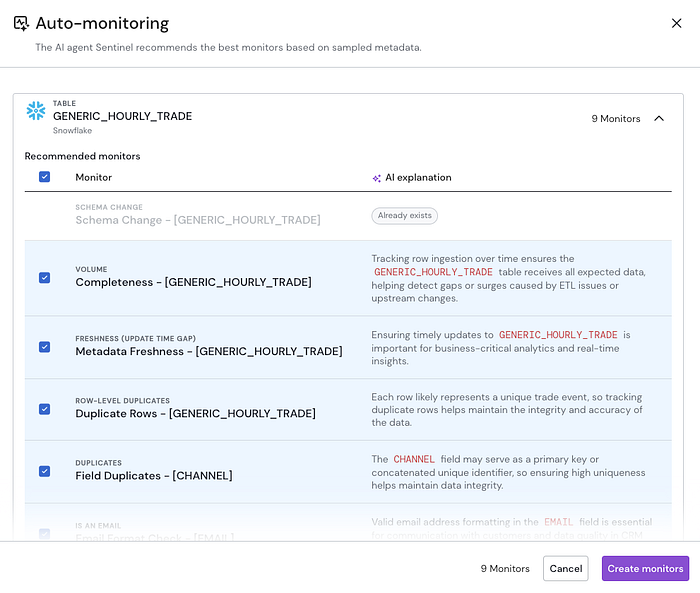
Here’s how it works: Point Sentinel at a table, a set of tables, or an entire data product. Within seconds, it analyzes column names, data types, actual data samples, existing patterns, and relationships to other assets. Then it suggests specific monitors, format validations, uniqueness checks, statistical anomaly detection, logical consistency rules.
But Sentinel isn’t just template-matching. It understands context. It knows that a column called order_date should validate that values are in the past, while delivery_date should be greater than order_date. It recognizes that an email column needs format validation, while a user_id column needs uniqueness checks.
The result? Data teams go from monitoring 20 critical tables to monitoring 200 in the same amount of time. More coverage, less effort, better protection.
Current state: Sentinel is in beta today and already generating monitor recommendations across format validation, data integrity, and statistical health checks. Learn more →
Sage: The Investigation Agent
What it does: Automatically investigates incidents to determine root cause and business impact.
Why it matters: Investigation is where data teams spend most of their incident response time. Sage makes this instant instead of hours-long.
When a monitor fails, Sage immediately gets to work. It analyzes upstream dependencies in your data lineage to trace where the issue originated. It examines recent code changes, pipeline logs, and query history. It reviews past incidents to see if this has happened before. It assesses downstream impact to understand which dashboards, reports, and teams are affected.
Then it synthesizes all of this into a clear analysis: “This freshness failure in customer_orders originated from a failed Airflow DAG. Three BI dashboards are affected, including the Revenue Dashboard used by 47 sales reps for daily standup at 9am. Similar incident occurred two weeks ago due to warehouse resource limits.”
Most critically, Sage translates technical failures into business impact. It doesn’t just say “table is stale”, it tells you which business stakeholders are affected, which business processes are broken, and what the actual business consequences might be.
Forge: The Resolution Agent
What it does: Recommends specific fixes for incidents, and can take action when appropriate.
Why it matters: Even after investigation, teams often struggle with “okay, now what?” Forge turns understanding into action.
Based on Sage’s root cause analysis, Forge suggests concrete remediation steps. For a failed dbt job, it might recommend: “Retry this specific job, it failed due to temporary warehouse resource limits. Historical success rate for retry: 94%.” For a stale table, it might say: “Run the available backfill job to refresh data. This will take approximately 12 minutes based on past runs.”
But Forge goes beyond recommendations. With your approval, it can take action: retry jobs, trigger backfills, restart pipelines. Each action includes clear explanation, estimated impact, and explicit approval gates. You stay in control while eliminating the manual execution work.
As teams build trust in Forge’s recommendations, the system learns patterns. When you approve “retry dbt job” for a specific failure pattern five times in a row, Forge can ask: “Should I auto-approve this action in the future?” Progressive autonomy, earned through demonstrated competence.
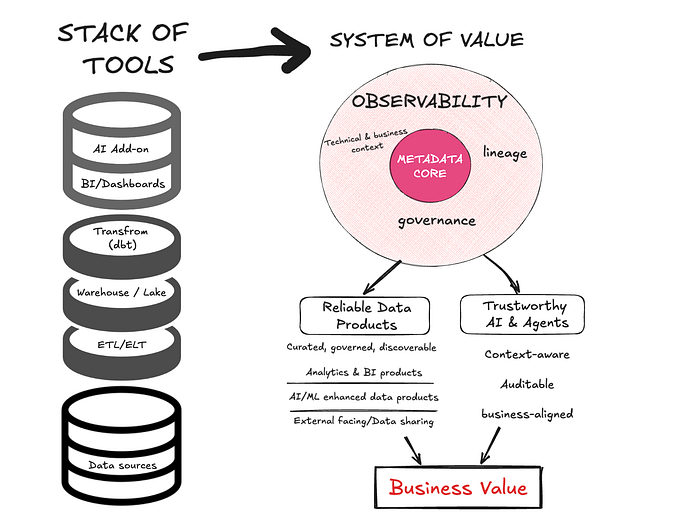
The System is Greater Than Its Parts
Here’s what makes this powerful: these agents don’t work in isolation. They’re designed as an integrated system.
Sentinel ensures comprehensive coverage across your data estate. Instead of monitoring 30 tables, you’re monitoring 300. Instead of guessing which monitors matter, you’re deploying monitors that actually catch real issues.
Sage means every incident, even ones affecting rarely-monitored tables, gets instant, thorough investigation. No more “I’ll look into this when I have time.” No more manual lineage tracing. Instant root cause, instant business impact assessment.
Forge turns investigation into resolution. Instead of “now someone needs to figure out what to do,” you get immediate, actionable recommendations. Instead of “someone needs to execute this fix,” the fix can happen automatically with appropriate safeguards.
Together, these agents create a flywheel:
- More monitoring → more incidents detected
- Better investigation → faster triage and prioritization
- Automated resolution → reduced mean time to recovery
- Learning from every incident → smarter recommendations over time
This is fundamentally different from traditional observability. It’s not about generating better alerts. It’s about creating a system that can reason about your data, understand your business, and act on your behalf.
What This Means for Data Teams
The practical implications are significant:
Monitoring becomes comprehensive, not selective. When Sentinel can analyze and recommend monitors in seconds, you can finally monitor your entire data estate. No more agonizing over which tables are “critical enough” to justify the setup time. No more blind spots where business-critical issues hide.
Incidents become business-prioritized, not technically-prioritized. When Sage assesses business impact automatically, you stop treating all red monitors as equally urgent. You focus on what actually matters to the business, the dashboard used by executives at 8am, the data feeding production ML models, the table that determines customer billing.
Resolution becomes guided, not guessed. When Forge recommends specific actions based on incident context and historical patterns, junior team members can handle incidents that previously required senior expertise. Institutional knowledge gets encoded into the system.
Data teams can scale without growing linearly. The bottleneck in data reliability isn’t data volume, it’s human time and expertise. When agents handle monitoring strategy, investigation, and routine fixes, data teams can support 5x more assets without 5x more people.
The Road Ahead: Business-Aware Observability
But this is just the beginning. The real transformation comes when observability becomes genuinely business-aware.
Imagine a data observability platform that doesn’t just monitor technical metrics, but understands business outcomes:
- Business SLA tracking: “Revenue dashboard must be ready by 9am for exec meeting” becomes a first-class concept, not just a technical freshness check
- Impact quantification: “This incident affects $X in revenue processing” instead of “5 monitors failed”
- Proactive prevention: “This table’s growth rate suggests it will hit row limits next Tuesday, should I scale the warehouse now?”
- Natural language access: Product managers can ask “Is our daily signup metric healthy?” without understanding SQL or data lineage
This is where the industry is heading. Not just better detection, but intelligent systems that understand business context, act proactively, and make data reliability accessible to everyone who depends on data, not just the technical experts.
From Detection to Intelligence
The evolution of data observability mirrors the evolution of infrastructure monitoring:
First generation: Manual monitoring. Someone checks if things are working.
Second generation: Automated monitoring. Systems check if things are working and alert humans.
Third generation: Intelligent monitoring. Systems understand what’s working, why it matters, and what to do about it.
Most data observability platforms today are solidly in the second generation. They’re sophisticated alerting systems. They can tell you what broke with impressive technical precision.
But they can’t tell you why it matters to your business. They can’t investigate on your behalf. They can’t act to prevent or fix issues. They can’t learn from patterns to get smarter over time.
That’s what AI agents make possible. Not incremental improvement in alerting, but a fundamental leap in capability.
Building vs. Buying Intelligence
Some teams will try to build this themselves. They’ll wire together LLMs, write prompts, create workflows. And for narrow use cases, this might work.
But building a production-grade agent system requires solving problems that aren’t obvious until you’re deep in production:
- How do you give agents reliable access to lineage, logs, metrics, and code history without creating a security nightmare?
- How do you prevent agents from taking harmful actions while still giving them enough autonomy to be useful?
- How do you train agents to understand your data semantics, your business logic, your failure patterns?
- How do you handle the inevitable errors and edge cases without eroding user trust?
- How do you make agents’ reasoning transparent so teams can understand and override decisions?
These are engineering problems that take years to solve properly. They require deep integration with data platforms, careful prompt engineering, sophisticated error handling, and extensive real-world testing.
The companies that solve this first will define the category. Everyone else will be catching up.
Not All AI Agents Are Created Equal
As AI agents enter the data observability market, it’s important to understand what makes them fundamentally different. The distinction isn’t about who has agents, it’s about what those agents are designed to do and who they’re designed to serve.
The Technical-Only Approach
Most observability platforms today are launching AI agents focused purely on technical workflows. These agents excel at analyzing data patterns, detecting anomalies, and investigating technical root causes. They’re powerful tools for data engineers.
For example, some platforms offer monitoring agents that analyze data samples and metadata to recommend monitors based on sophisticated pattern detection. Others provide troubleshooting agents that investigate technical failures by examining logs, query histories, and pipeline metadata. These are valuable capabilities that accelerate technical workflows.
But they’re built with one persona in mind: the data engineer. They speak in technical language. They prioritize based on technical severity. They require deep data platform expertise to interpret and act on their recommendations.
This creates a fundamental limitation: these agents can tell you what broke and where, but they can’t tell you why it matters to your business.
The Business-Aware Difference
What makes Sifflet’s approach different isn’t just having agents, it’s building agents that understand both technical failure and business impact.
When Sage investigates an incident, it doesn’t just trace upstream dependencies to find the failing pipeline. It also analyzes downstream impact to determine which business stakeholders are affected, which business processes are broken, and what the actual business consequences are.
This isn’t a minor feature enhancement. It’s a fundamental difference in design philosophy.
Technical-only agents answer: “This dbt model failed due to a schema mismatch in the upstream source table.”
Business-aware agents answer: “This failure affects your Revenue Dashboard used by 47 sales reps for daily standup at 9am. The last successful refresh was 14 hours ago, meaning today’s sales numbers are stale. Three similar incidents occurred in the past month, all traced to the same upstream data provider.”
One answer helps a data engineer start debugging. The other answer helps the entire organization understand impact, prioritize response, and make informed decisions.
Three Agents, One Integrated System
Another key difference is architectural. Some platforms have launched single agents that try to do everything. Others have separate agents for different tasks without deep integration between them.
Sifflet’s three-agent system is designed as an integrated intelligence layer where each agent has specialized expertise but they work together seamlessly:
- Sentinel ensures comprehensive monitoring coverage, learning from usage patterns and business context to recommend monitors that actually matter
- Sage investigates every incident with full context from Sentinel’s monitoring strategy and provides business impact assessment that Forge needs for prioritization
- Forge takes action based on Sage’s root cause analysis and business impact scores, learning from approval patterns to get progressively more autonomous
The integration creates a flywheel: more monitoring generates better incident data, better investigation enables smarter resolution, and every resolved incident improves all three agents’ decision-making.
Action vs. Recommendation
Perhaps the most significant difference is the ability to act.
Most observability agents today are deliberately read-only. They can analyze and recommend, but they can’t actually do anything. This is by design, vendors prioritize safety over utility. The result? Data teams still need to manually execute every fix.
Some newer platforms generate code suggestions for fixes, which is a step forward. But it still requires a data engineer to review the code, test it, and deploy it, often taking hours or days.
Sifflet’s Forge takes a different approach: guided autonomy with progressive trust.
Forge can execute safe, pre-approved actions with explicit approval gates: retry failed jobs, run backfills, restart pipelines. Each action includes clear explanation of what will happen, estimated impact based on historical patterns, and one-click approval or rejection.
Most importantly, Forge learns from your decisions. When you approve “retry dbt job” for a specific failure pattern multiple times, Forge asks if it should auto-approve next time. Trust is earned through demonstrated competence, not assumed from the start.
This makes the crucial difference between “here’s what you should do” and “I can do this for you if you approve.” One requires human execution time. The other scales.
Who Can Use It?
The final differentiator is accessibility. Technical-only agents require technical users. You need to understand data lineage, SQL, pipeline orchestration, and monitoring strategy to make sense of their outputs.
Business-aware agents can serve both technical and non-technical users. When Sage translates “freshness failure in dbt model customer_daily_summary” into “Morning sales report delayed, affects field team planning,” suddenly product managers and business analysts can understand what’s happening without a data engineer translating.
This extends further with natural language interfaces that let non-technical users create monitors in plain English: “Alert me if daily signups drop more than 20%” or “Tell me if our key revenue metrics look wrong.” The agent handles the technical translation automatically.
This isn’t about replacing data engineers. It’s about making data reliability a team sport where business stakeholders can participate in monitoring strategy, understand incident impact, and make informed prioritization decisions.
The Category Question
These differences aren’t incremental. They represent fundamentally different visions for what AI agents should do in data observability.
Technical-only agents optimize the existing workflow. They make data engineers more productive at their current jobs. They’re evolution within the second generation of data observability.
Business-aware agents transform the workflow. They make data reliability accessible to the entire organization. They bridge the gap between technical failure and business impact. They represent the third generation.
Both approaches have value. But only one has the potential to solve the fundamental problem that’s held back data observability adoption: the disconnect between technical metrics and business outcomes.
The market will ultimately decide which vision wins. But we believe the future belongs to platforms that can serve both data engineers and the business stakeholders who depend on data, not just one or the other.
The Bottom Line
Data observability isn’t a solved problem. Detection is solved. Alerting is solved. Visualization is solved.
But reliability, ensuring data is trustworthy, available, and useful when business needs it, that’s still largely manual, reactive, and dependent on specialized expertise.
AI agents change the equation. They make it possible to monitor comprehensively, investigate instantly, and act proactively. They make data reliability a system problem, not a human problem.
This isn’t about replacing data engineers. It’s about amplifying them. Letting them focus on strategic work while agents handle the operational grind. Letting them scale their expertise across more systems, more data, more teams.
The future of data reliability isn’t more dashboards, more monitors, or more alerts. It’s intelligent systems that can reason, act, and learn. Systems that understand both technical failure and business impact. Systems that don’t just tell you what broke, but investigate why and suggest how to fix it.
That future is being built today. The question for data leaders isn’t whether AI agents will transform data reliability. It’s whether you’ll be leading that transformation or following it.












-p-500.png)
