



Let’s start with an uncomfortable truth: for years, data observability tools have built a reputation for having impressive demos that are nearly impossible to reproduce in production. It’s the shiny demo syndrome: deciding how to monitor a single pipeline with basic transformations is straightforward, but that confidence evaporates when you have to define meaningful monitoring across hundreds of pipelines with ambiguous structures.
And if we’re being honest, the reputation is partiallypartialtly warranted. Many platforms were built for the UI first, while the chaotic, sprawling, and complex reality of a modern data stack was treated as an afterthought.
At Sifflet, however, our guiding principle has always been to build for scale first. This mindset is precisely what drove our major push last year for an "everything as code" paradigm. We completely overhauled our Data-Quality-as-Code framework and built our Universal Connector not just for developer convenience, but because we believe a programmatic, API-first approach is the only way to sustainably manage data quality in a complex environment. It provides the fundamental control and governance needed to handle thousands of assets.
But a programmatic foundation, while essential for control, is only half of the equation. This year, our focus shifted to the other half: intelligence. We asked ourselves: How can we use this scalable foundation to actively solve the two biggest blockers to data trust at scale - ensuring the right assets are monitored and managing the resulting alert noise?
As we began tackling these challenges, AI and autonomous agents became the clear catalyst, allowing us to build a layer of intelligence that automates and simplifies these exact problems. This post will walk you through the key capabilities we shipped this year to make data trust at scale not just a theoretical possibility, but a practical, everyday reality. While each feature plays a critical role, be sure to stick around for the last two - it's where our AI-powered approach truly shines.
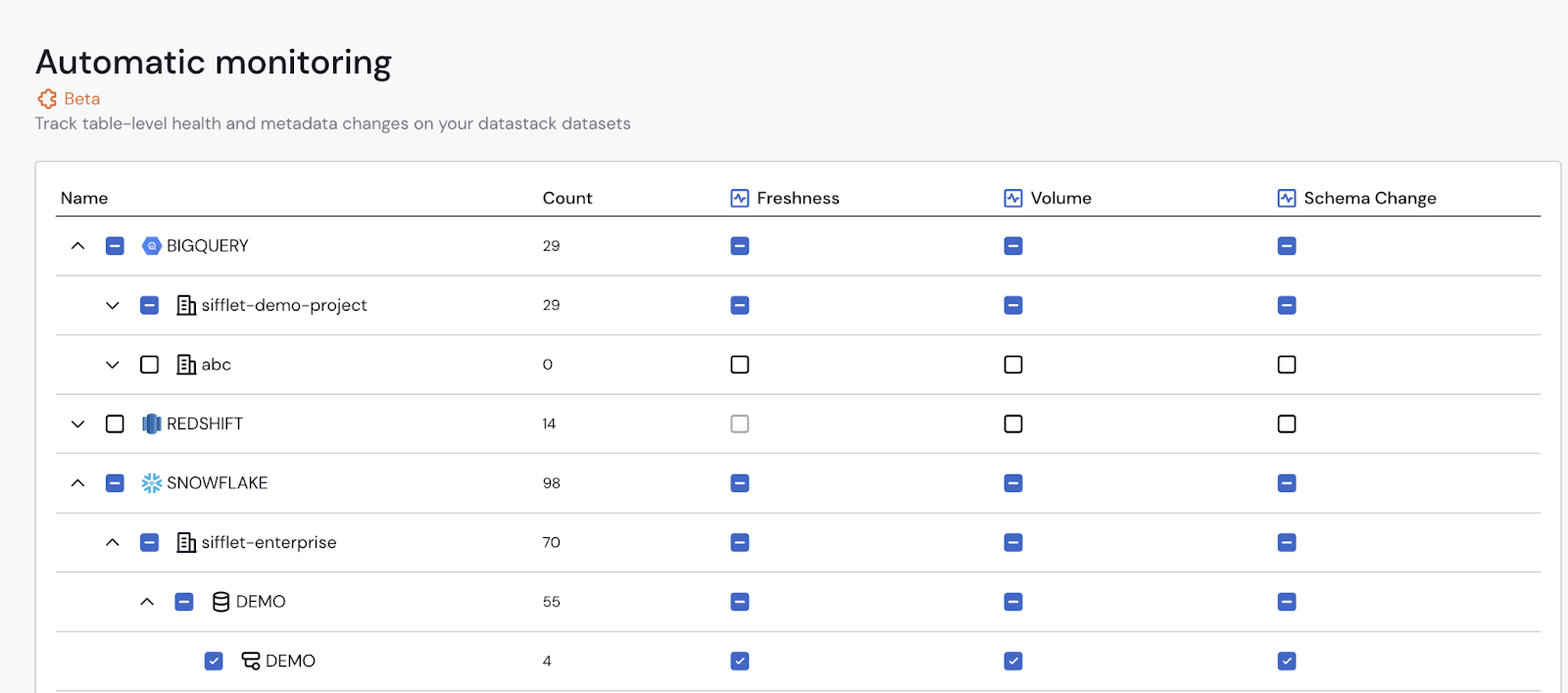
Automatic Monitoring
Scaling data quality effectively means establishing a solid monitoring foundation from day one, which is difficult to achieve with an asset-by-asset approach. Automatic Monitoring is our answer. Instead of the traditional bottleneck of manual setup, you can now apply a comprehensive suite of intelligent monitors to entire schemas or databases with a single toggle. This instantly creates a robust baseline of coverage for all existing and future assets, providing a scalable foundation for data trust from the very beginning.
Thinking in Products, Not Assets
Data isn't just a collection of disparate tables and dashboards; it’s instead the foundation on top of which data products are built. At Sifflet, we’ve always firmly believed that data products are the right level of abstraction for data teams. They group together the use case, pipelines, assets, and quality guarantees. Sifflet now allows you to model these Data Products natively. Instead of managing hundreds of individual assets, teams can now think in terms of the business value they deliver, monitoring the health of an entire "Marketing Analytics Product" or "Financial Reporting Product" as a single, coherent unit.

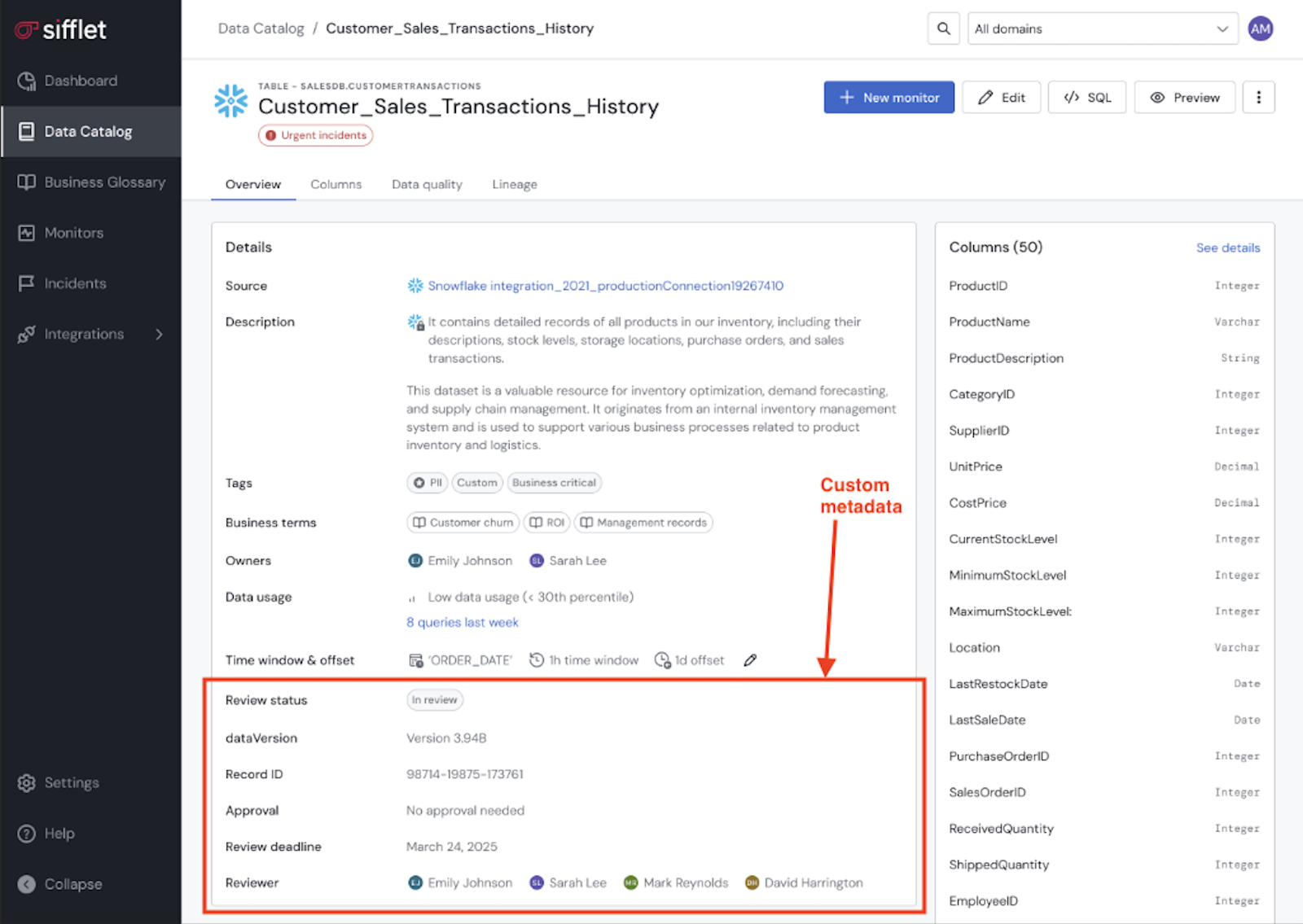
Custom Metadata for Real-World Complexity
No two organizations are the same. Your company has its own way of defining data ownership, classifying data sensitivity, or tracking project codes. We now support Custom Metadata, allowing you to enrich assets in Sifflet with the specific attributes your organization needs. This ensures that even in the most complex environments, your assets are documented with the right business context, making them discoverable and understandable for everyone.
A Simpler, More Scalable Source Management
We took a hard look at our source management experience and drastically simplified it. The new experience aligns one source in Sifflet with one account in an external data system (e.g., a single Snowflake account). This one-to-one mapping dramatically simplifies setup, permissioning, and mental overhead, making the platform easier to administer as you connect more parts of your data stack.

Data Quality as Code, Evolved
Our YAML framework was already a power user’s dream for managing quality at scale, using wildcards and for-loops to apply rules across thousands of assets. We’ve supercharged it by adding support for a wider range of monitors and launching an even more powerful Sifflet CLI. These additions take the ability to embed quality into your development lifecycle to the next level. Now, you can manage, validate, and deploy your definitions with greater control directly from your CI/CD pipeline, while the introduction of workspaces provides the structure to do it all effectively at scale.
From Alert Overload to Meaningful Incidents with Sage
Here’s where AI makes a dramatic entrance. As you scale monitoring, you inevitably scale alerts. We heard it time and time again: hundreds of alerts fire, but they all point to one upstream pipeline failure. Alert fatigue is real, and it’s the single biggest killer of data quality initiatives.
Our AI agent, Sage, now provides Incident Auto-Grouping. It analyzes the firehose of alerts, understands the underlying lineage and relationships between them, and automatically groups them into a small set of meaningful incidents. Instead of waking up to 500 individual alerts, your on-call engineer sees one incident: "Upstream ingestion from Salesforce failed." It’s a game-changer for reducing noise and focusing teams on what actually matters.

Sentinel: Your Proactive Monitoring Partner (Soon in GA)
Once you’ve identified your critical assets, the next bottleneck is knowing how to monitor them effectively. Which columns should have null checks? What’s a reasonable freshness expectation? Manually profiling tables one by one to answer these questions is a time-consuming process that doesn't scale.
Sentinel is designed to eliminate this guesswork. You simply select the assets you want to monitor (whether it’s a handful of critical tables or an entire data product) and Sentinel gets to work. It instantly analyzes the structure and data within each asset, generating a tailored set of high-impact, recommended monitors for the entire selection at once.
This allows you to establish a meaningful and robust monitoring baseline across entire groups of assets in minutes, not days. It acts as an expert partner to ensure your coverage is not just broad, but also deep and relevant, even at scale.

And That’s Not All…
While scale was our north star, we also shipped a host of other critical improvements. We released improved analytics to better track the ROI of your data quality program, introduced pipeline alerting to catch failures at the process level, and refined our alerts to make them more actionable and context-rich.
The Journey Continues
Building a truly scalable data observability platform is a journey, not a destination. It requires a fundamental shift from manual, reactive processes to an automated, intelligent, and proactive system. By embracing concepts like Data Products and shipping AI agents like Sage and Sentinel, we’re not just adding features - we’re building a platform that can grow with you, continuously finding and fixing data issues with ever-increasing autonomy.












-p-500.png)
