



Did you know 84% of CEOs doubt the integrity of the data on which they base their decisions?
Why does this happen?
Their data teams are using observability tools that CEOs and other teams cannot understand.
While Monte Carlo is a solid data observability tool, it focuses to much on the technical side of data and leaves out context and business teams.
If this is happening to you, check out 5 alternatives to Monte Carlo.
What is Monte Carlo?
Monte Carlo pioneered the data observability space and remains one of the leading platforms in the market.
The platform automatically ingests metadata and statistical profiles from both structured and unstructured data sources to detect anomalies and data quality issues in real-time. When problems arise, Monte Carlo immediately alerts data teams and provides data lineage to help root cause analysis.
Built as a cloud-native solution, Monte Carlo integrates seamlessly with modern data stacks including Snowflake, Databricks, and BigQuery.
The platform's value proposition centers on preventing data downtime (a term they coined) through continuous pipeline monitoring and proactive issue detection.
By tracking historical data patterns and providing end-to-end visibility, Monte Carlo helps organizations keep reliable data pipelines, prevent downstream system failures, and preserve confidence in data-driven decisions.
Monte Carlo’s Features
Monte Carlo delivers a complete toolkit of data observability capabilities designed to keep pipeline reliability and accelerate incident response.
The platform's feature set spans automated monitoring, intelligent alerting, and operational insights that help data teams proactively identify and resolve data quality issues before they impact business operations.
Understanding how these features translate into real-world value is essential for data teams considering Monte Carlo as their observability solution
1. Data Asset Discovery & Cataloging
Monte Carlo's asset management functionality provides detailed visibility into your entire data ecosystem.
The platform automatically discovers and catalog’s data assets across your warehouse and downstream applications, creating a centralized inventory that data teams can search, filter, and explore through an intuitive interface.
The catalog search capability allows users to quickly locate specific datasets using keyword searches and tag-based filtering, streamlining data discovery workflows for both technical and business users.
Credit: Monte Carlo
Each cataloged asset contains rich contextual metadata that Monte Carlo continuously collects and maintains.
When users select a specific data asset, they gain access to comprehensive operational intelligence including:
- Table and field lineage - Complete dependency mapping showing data flow relationships
- Query execution logs - Historical query patterns and performance metrics
- Data freshness and volume trends - Automated tracking of update patterns and size changes
- Alert history and timelines - Incident tracking and resolution patterns
- Downstream impact analysis - Visibility into affected reports, dashboards, and applications
- Custom monitoring rules - Configured data quality checks and thresholds
This unified view enables data teams to quickly assess asset health, understand dependencies, and make informed decisions during incident response or routine maintenance.
2. Intelligent Alerting & Incident Management
Monte Carlo's alerting system automatically detects data anomalies and immediately notifies relevant stakeholders with contextual information needed for rapid triage and resolution.
Instead of overwhelming teams with noise, the platform delivers targeted alerts that include root cause analysis suggestions and actionable remediation guidance.
The centralized incident management dashboard provides complete visibility into your data reliability posture. Teams can filter and analyze alert history to identify patterns, track resolution times, and optimize monitoring coverage across their data estate.
Credit: Monte Carlo
Monte Carlo's alerting capabilities include several important features that streamline incident response:
- Smart notification routing - Alerts are automatically sent to asset owners and relevant team members based on data lineage and organizational structure
- Contextual incident details - Each alert includes affected downstream systems, historical context, and suggested investigation starting points
- Severity classification - Automated prioritization helps teams focus on business-critical issues first
- Collaborative resolution tracking - Built-in workflows so you can assign ownership, documenting fixes, and preventing recurring incidents
- Custom alert rules - Flexible configuration for business-specific monitoring requirements and escalation policies
- Integration capabilities - Native connectivity with existing incident management tools like PagerDuty, Slack, and JIRA
This comprehensive approach to alerting ensures data teams can quickly identify, prioritize, and resolve data quality issues before they impact business operations or downstream analytics.
3. Monitors
Monte Carlo's monitoring engine provides constant oversight of your entire data ecosystem through automated pattern learning and customizable quality checks.
The platform can monitor critical data assets without manual configuration while also supporting deep, targeted monitoring for your most business-critical tables and pipelines.
Monte Carlo organizes its monitoring capabilities into four core categories:
- Table monitoring
Automatically learns baseline patterns for data volume, schema changes, and update frequencies to detect pipeline disruptions and unexpected data behavior without requiring manual threshold setting.
- Metrics monitoring
Learns from historical performance data to establish expected ranges for key business metrics, enabling early detection of anomalies in specific data segments or KPI calculations.
- Validation monitoring
Supports both custom SQL-based data quality rules and pre-built validation templates for common data integrity checks, allowing teams to enforce business-specific quality standards.
- Job monitoring
Tracks query execution times, pipeline runtime performance, and scheduling reliability to ensure data processing workflows meet operational SLAs.
This multi-layered approach forms the foundation of Monte Carlo's AI-powered observability framework, combining automated anomaly detection with configurable business rules to maintain data reliability at scale.
For mission-critical datasets, teams can create customized monitoring workflows that execute targeted quality checks and validation rules on defined schedules, ensuring comprehensive coverage of high-value data assets.
4. Dashboards
Monte Carlo provides two distinct dashboard types designed to serve different organizational needs and stakeholder requirements.
- Data reliability dashboard
The executive-level data reliability dashboard delivers comprehensive visibility into your organization's data ecosystem health and operational performance.
This centralized view presents key metrics including incident frequency, mean time to resolution (MTTR), platform adoption rates, and overall system uptime with automated updates every 12 hours.
Credit: Monte Carlo
The dashboard provides actionable insights across several critical dimensions:
- Incident analytics - Historical trends, severity distribution, and resolution patterns to identify systemic issues
- Response performance - MTTR tracking and team performance metrics to optimize incident management processes
- Adoption monitoring - Platform usage statistics and coverage metrics to ensure comprehensive data observability
- Availability tracking - System uptime and reliability scores with trend analysis for capacity planning
- Table health dashboard
The table health dashboard offers granular visibility into data quality metrics at the dataset level within your data warehouse or lake environment.
This operational view allows data engineers and analysts to proactively identify quality issues before they trickle downstream and impact other assets.
Key capabilities include real-time quality scoring, anomaly detection results, and detailed resolution tracking to protect high data integrity standards across your most critical datasets.
5. Platform Configuration & Administration
Monte Carlo's administrative settings provide deep control over platform configuration, allowing your organization to customize the observability experience to match their specific data governance requirements and operational workflows.
Key administrative capabilities include:
- API keys management - Secure credential generation and rotation for programmatic access to Monte Carlo's REST API and SDK functionality
- Domain management - Organizational data asset categorization and ownership assignment to establish clear governance boundaries and responsibility models
- User access control - Role-based permissions and authentication management to ensure appropriate access levels across teams and stakeholders
- Integration configuration - Connection setup and maintenance for data warehouses, BI tools, and third-party systems in your data stack
- Data asset exclusions - Granular control over which datasets and tables are included in monitoring and observability workflows
- Lineage customization - Manual lineage adjustments and relationship mapping to enhance automated dependency discovery with business context
6. Agent Observability
Agent Observaility is a new expansion of Monte Carlo Data. It is designed to provide end-to-end visibility across data and the AI stack.
With this feature, data teams can detect, triage, and resolve reliability issues in production enviornments.
Teams can evaluate agent outputs using either deterministic checks or LLM-as-judge assessments, define what “good” responses should look like, and receive alerts when production results don’t meet those standards.
Agent Observability includes a set of low-code evaluations designed to address common quality dimensions such as relevance, clarity, readability, language consistency, and task completion.
These checks are paired with telemetry that captures prompts, completions, queries, latencies, and error traces, enabling teams to investigate issues and identify potential root causes more efficiently.
The goal of this feature is to improve reliability and governance within AI systems.
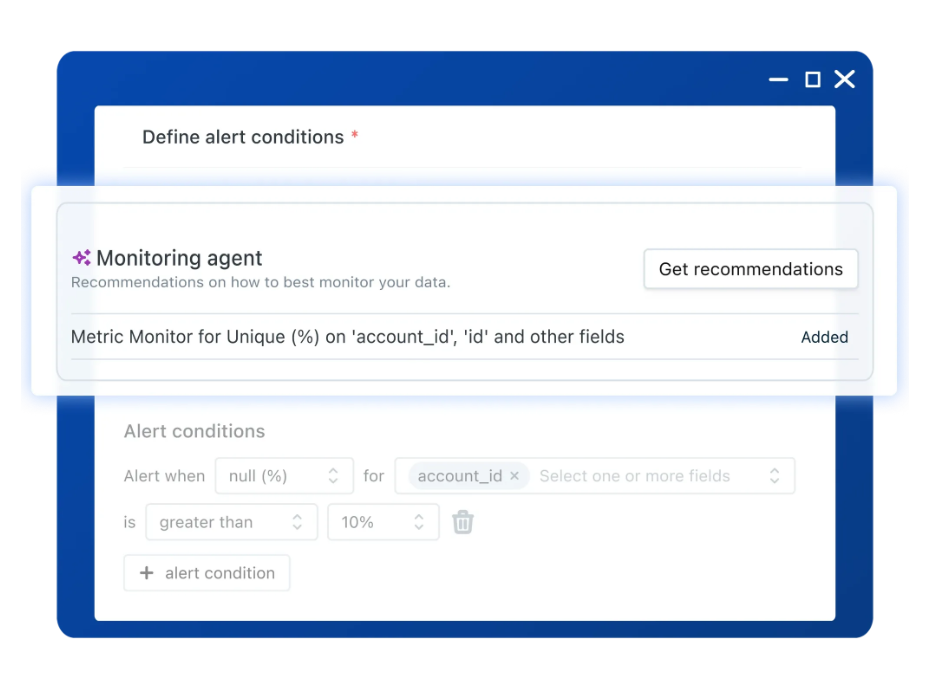
Why Data Teams Consider Alternatives to Monte Carlo
Monte Carlo established the data observability category, but engineering teams increasingly report fundamental limitations that impact both technical operations and business adoption.
Concerning technical constraints, Monte Carlo offers a rigid monitoring framework that requires too much manual configuration, although it does have limited customization if you need complex data architecture.
Because Monte Carlo doesn’t offer business context, which means your data teams will be dealing with alert fatigue on the daily.
On the business side, Monte Carlo has become a rather expensive tool that does not scale with smaller teams.
Additionally, Monte Carlo is a tool that mostly benefits data engineers, as business teams cannot be involved in the data quality process nor can they understand and view triage, due to a lack of business context.
Basically, Monte Carlo pioneered the first wave of data observability, but hasn’t evolved with the more modern trends in the field.
In the 1st wave, where Monte Carlo excelled, data observability focuse primarily on infrastructure. Monitor data like servers, focused on uptime, volume, schema changes.
In the 2nd wave, data observability tools took a more developer-centric approach. This was grear for engineering teams, although it offered a very low business visibility with observability-as-code, embedded in CI/CD pipelines.
And finally, the 3rd wave, where we find ourselves now, is focused on business context. We now understand that all teams in an organization need to work together and have access to the same information.
Data observability tools that understand this focus should offer intelligent monitoring that understands business impact, allows cross-functional collaboration, and provides contextual incident resolution.
5 Best Monte Carlo Alternatives
While there are many data observability tools, 5 stand out as solid alternatives to Monte Carlo because of their pricing, focus, infrastructure, complexity, and features.
1. Sifflet
Stands out as business-context aware observability.
Sifflet is an AI-powered data observability platform that caters to both technical and non-technical users in order to provide a centralized view of your organization’s data health and quality.
Some technical advantages include:
- AI-powered monitor creation using natural language for domain experts
- Dynamic context engine correlating metadata, lineage, and business logic
- Cross-persona alerting with context-appropriate notifications
- Field-level lineage with business impact propagation
Sifflet’s technical architecture is built on:
- Metadata-first approach enabling faster onboarding
- API-driven extensibility for custom integrations
- Cloud-native deployment with private agent options
- Real-time lineage calculation without performance impact
Sifflet is best for organizations wanting to democratize data quality beyond engineering teams while maintaining technical sophistication.
In regards to agentic observability, Sifflet has 3 native AI agents that operate across the full observability stack to recommend triage and guide resolution of data issues.
Sentinel watches over you data and examines metadata such as lineage, schema drift, and usage patterns to recommend where you should focus your monitoring to reduce alert fatigue.
Sage saves past incident and tracks down root cause analysis in seconds.
And finally, Forge suggests context-aware fixes based on historical patterns so your team can have actionable advice at their reach.
You can implement this tool with a 2-3 day setup, and receive immediate value from ML-suggested monitors, business users productive within first week.
What makes Sifflet a better choice?
2. Acceldata
Acceldata manages full-stack data operations.
This tool is a comprehensive platform that monitors data infrastructure, pipelines, and quality.
Some technical advantages Acceldata offers include:
- Infrastructure observability tracking cluster health, query performance, compute costs
- Multi-layer root cause analysis correlating issues across the entire data stack
- Cost optimization insights with resource usage monitoring
- Pipeline performance monitoring for job-level visibility
Acceldata is a good choice large-scale data platforms who require infrastructure monitoring alongside data quality. Teams running Hadoop, Spark, or complex distributed systems.
The downside is that Acceldata requires a more complex setup than Monte Carlo, it requires infrastructure expertise.
This translates into a higher resource overhead for comprehensive monitoring.
What makes Acceldata a better choice:
3. Metaplane
Metaplane offers a much more lightweight developer experience as it is designed for modern data teams that need fast, easy monitoring without the overhead of a complex platform.
Metaplane offers fast deployment, and it a developer-friendly alternative for smaller teams.
Some technical advantages include:
- Fast deployment with minimal configuration
- Automated anomaly detection with smart baseline learning
- Native BI tool integrations for downstream impact visibility
- Flexible alerting via Slack, email, webhooks
Metaplane is ideal for startups and small-to-medium data teams who need immediate observability without enterprise complexity.
However, it does offer more limited advanced features compared to Monte Carlo, including basic lineage capabilities.
Additionally, Metaplane has less customization features for complex monitoring requirements.
What makes Metaplane a better choice?
4. Bigeye
Bigeye offers metric-driven quality management.
This platform is designed to help data engineering and analytics teams monitor, detect, and resolve data quality issues across pipelines. Bigeye supports user-defined metrics and SLA-focused monitoring, giving teams precise control over what is measured and how alerts are triggered.
Some of Bigeye’s technical advantages include:
- Custom metric creation with full user control
- SLA-based alerting with business-relevant thresholds
- Visual rule builder for complex quality logic
- Transparent monitoring logic versus black-box ML detection
Recent updates indicate that Bigeye is expanding beyond traditional data observability into AI governance, cost efficiency, and enterprise scalability.
Notable features include FinOps capabilities for monitoring cloud warehouse usage and costs, the upcoming AI Trust Platform for governing AI agent access and behavior, Dependency-Driven Monitoring and Lineage Plus to reduce alert noise and focus on high-impact datasets, and bigAI, which leverages AI to assist with incident resolution and root cause analysis.
Additional improvements such as Metadata Metrics, lineage-enabled workflows, bigConfig for infrastructure-as-code monitoring, a system integrator partner program, and EMEA hosting reflect Bigeye’s emphasis on scaling observability for large, global enterprises.
Bigeye is therefore well-suited for teams with established data quality KPIs who require precise control over monitoring logic, cost transparency, and emerging AI governance capabilities.
However, Bigeye does require more manual configuration during setup and it lacks native lineage features.
What makes Bigeye a better choice?
5. Soda
Soda is offers a code-first DataOps integration.
This tool is an open-source and commercial data quality monitoring platform designed to help data teams test, monitor, and enforce data quality standards across their pipelines.
Soda believes in building an open-source foundation with declarative quality-as-code approach.
Some technical advantages Soda offers include:
- SodaCL declarative syntax for version-controlled quality checks
- CI/CD pipeline integration for shift-left quality testing
- Open-source core with commercial cloud features
- Multi-warehouse support with consistent check syntax
Soda is built for engineering teams with strong DataOps practices wanting quality checks embedded in development workflows.
However, Soda does not offer any native lineage capabilities and it requires technical expertise for advanced configurations.
Additionally, the business user interface is quite limited.
What makes Soda a better choice?
Technical Implementation Comparison
Implementing your tool effectively in your team is also an important consideration.
Monte Carlo takes a pretty long time to implement in comparison with its other alternatives.
How to Make the Strategic Choice
The data observability market has matured beyond first-generation infrastructure monitoring. While Monte Carlo established the category, modern alternatives offer:
- Better business alignment
- More flexible architecture
- Intelligent and context-aware automation
- Cost efficiency
The right choice depends on your team's technical maturity, business stakeholder involvement, and architectural requirements.
But one thing is clear: the rigid, expensive, engineer-only approach of first-generation tools no longer meets the demands of modern data teams.
Ready to evaluate alternatives?
Consider your team's specific requirements around business user access, implementation timeline, and total cost of ownership. The data observability landscape offers better options than settling for yesterday's technology at tomorrow's prices.
If you’re ready to try other options, try Sifflet today!

.avif)













-p-500.png)
