



Monte Carlo and Sifflet are two big names in data observability.
Monte Carlo stands as one of the first data observability platforms, which makes it one of the most popular choices.
Although Sifflet is a newer player, it has taken data observability with a whole new approach in philosophy and architecture.
Monte Carlo takes on a more technical approach, detecting algorithms, lineage, or integrations breadth.
However, data engineers and domain experts still remain separated.
Sifflet aims to protect technical rigor, while including business context in the mix so observability aligns with the business.
In this Monte Carlo vs Sifflet, we put both tools to the test.
Monte Carlo vs Sifflet: 1st Analysis
| Dimension | Monte Carlo | Sifflet | Insight |
|---|---|---|---|
| Positioning | Prevent data downtime | Enable every team with contextual observability | Contextual observability vs siloed alerts |
| Personas | Data Engineers, Platforms Teams, CDOs | Engineers, Analysts, Data Scientists, Execs, CDOs | Broader persona engagement |
| Features | Anomaly detection, lineage, alerts | No-code monitors, catalog, lineage, cross-persona alerts | Faster time-to-value and collaboration |
| UX and setup | Developer-focused, enterprise-grade | Intuitive UI, natural-language wizard, Chrome extension | Minimal onboarding friction |
| Pricing | Tiered enterprise pricing | Flexible tiers; faster ROI | Agility vs premium positioning |
| Integrations | Snowflake, Databricks, dbt | Same as Monte Carlo + contextual metadata integrations | Best-of-breed.ecosystem synergy |
Monte Carlo
Monte Carlo is a data observability platform that focuses on helping organizations prevent data downtime by identifying and resolving data quality issues.
Monte Carlo offers the necessary tools to track anomaly detection, lineage, and data monitoring, and is primarily targeted at data engineering teams within large-scale, fast-growing enterprises.
This tool automates monitoring and incident management, aiming to provide full insights into data pipelines with alerts based on statistical anomalies.
While Monte Carlo is a powerful tool, traditionally, it has focused more on detection than on cross-functional usability or seamless integration into team workflows.
In Monte Carlo’s latest product update, they have pulled their shift more toward AI with the Obersvability Agent.
Sifflet
Sifflet is a full-stack data observability platform designed for both technical and non-technical users. The tool offers clear and actionable insights into the health of your data.
Sifflet combines anomaly detection, lineage, monitoring, and collaboration all in one user-friendly tool. This allows for data to be unified across an entire organization.
Sifflet combines 3 main technologies:
The tool has a strong emphasis on usability, scalability, and intelligent alerting, Sifflet helps organizations detect issues early but also resolve them faster and prevent recurrence.
Sifflet stands out because it offers content into every alert in order to provide trust and adoption.

For example, if there is a spike in data (higher sales due to a flash sale) , a regular data observability tool could flag this as an anomaly and data engineers could spend a long time solving an issue that doesn’t really exist.
Who are the ICPs?
The main difference in both tools lies in team collaboration.
While Monte Carlo caters to more technical users, Sifflet aims to make data accessible and usable throughout the entire enterprise.
Monte Carlo’s ICP
Monte Carlo uses workflows that are centred around engineering, which require deep integrations with the rest of the data stack and collaboration with infrastructure teams.
Monte Carlo focuses on technical users, such as data engineers, platform teams, or CDOs.
- Data engineers
Monte Carlo focuses especially on data engineers who are in charge of keeping data pipelines and resolving data quality issues.
The platform is centered around incident detection and resolution workflows for engineering teams.
- Platform teams
Platform teams are in charge of keeping the organization’s data infrastructure.
Monte Carlo offers automated observability into data pipelines, allowing platform teams to detect and resolve data incidents.
- Chief Data Officers
Monte Carlo also targets data leadership roles by providing dashboards and insights into data reliability.
However, actionable use still depends on more technical teams to interpret alerts and act accordingly.
In other words, Monte Carlo is designed for teams with engineering knowledge and capabilities.
Sifflet’s ICP
On the other hand, Sifflet is designed for both technical and non-technical teams, which makes data observability a shared responsability.
Let’s break down the personas:

- Data engineers and analytics engineers
Sifflet allows automated monitoring, root cause analysis, and easy-to-use workflows that reduce time to detection and resolution.
Its no-code and low-code interfaces give access across multiple engineering levels.
- Data scientists
Sifflet proactively alerts data scientists on data quality, schema, changes or other issues without requiring them to manage the data platform.
Sifflet offers an understanding of the data flow through the whole pipeline, from ingestion to dashboards, with a clear understanding of upstream and downstream dependencies of the datasets.
- Business analysts
Sifflet also caters to less technical users, as it offers collaboration tools and intuitive visuals so business analysts can detect data issues that will impact dashboards.
- Operations and DevOps
Sifflet allows cross-functional collaboration by bringing in operations, DevOps, and business teams.
DevOps teams can integrate Sifflet into their observability stack, supporting SLAs and platform reliability.
- Executives and CDOs
Sifflet provides deep insights and governance tools that help leaders monitor data trust across the organization, that will allow them to align data quality tasks with business strategies.
Features
| Feature | Monte Carlo | Sifflet |
|---|---|---|
| Anomaly detection | ✔ | ✔ |
| Lineage and catalog | ✔ | ✔ |
| No-code monitor creation | ✗ | ✔ |
| Cross-persona alerts | ✗ | ✔ |
| AI-powered root cause | ✔ | ✔ |
| Incident workflows | ✔ | ✔ |
Monte Carlo and Sifflet share many important features of data observability such as anomaly detection, lineage, data catalog, and incident workflows.
The main difference in features is in UX, accessibility and AI features.
Sifflet stands as a more inclusive and intuitive user experience, with a no-code monitor creation that allows non-technical users to define custom monitors.
Additionally, Sifflet supports cross-persona alerts, ensuring the right users are notified with the right level of context.
Monte Carlo, by contrast, remains more engineer-centric, and lacks no-code workflows or broad alert customization. Monte Carlo requires deeper expertise and manual configuration to fully leverage its toolset.
Regarding AI capabilities, Monte Carlo uses AI to monitor your data quality across data pipelines.
Monte Carlo's AI uses Smart Monitor recommendations that analyze patterns in your dataset to suggest relevant monitoring.
This feature is particularly useful for data scientists as it helps prevent silent data issues that can alter dashboards.
The AI copilot is a metadata-driven assistant that works throughout your whole data stack. It has the ability to learn, reason, and recommend actions based on your data pipeline, behavior, and activity.
The AI copilot is a metadata-driven assistant that works throughout your whole data stack. It has the ability to learn, reason, and recommend actions based on your data pipeline, behavior, and activity.
Monte Carlo have recently included an Observability Agent too.
The Observability Agent essentially monitors the performance and reliability of AI agents within the data AI ecosystem.
This will allow you to monitor agent behavior, detect anomalies, and solve issues by tracing agent decisions and identifying bottlenecks.
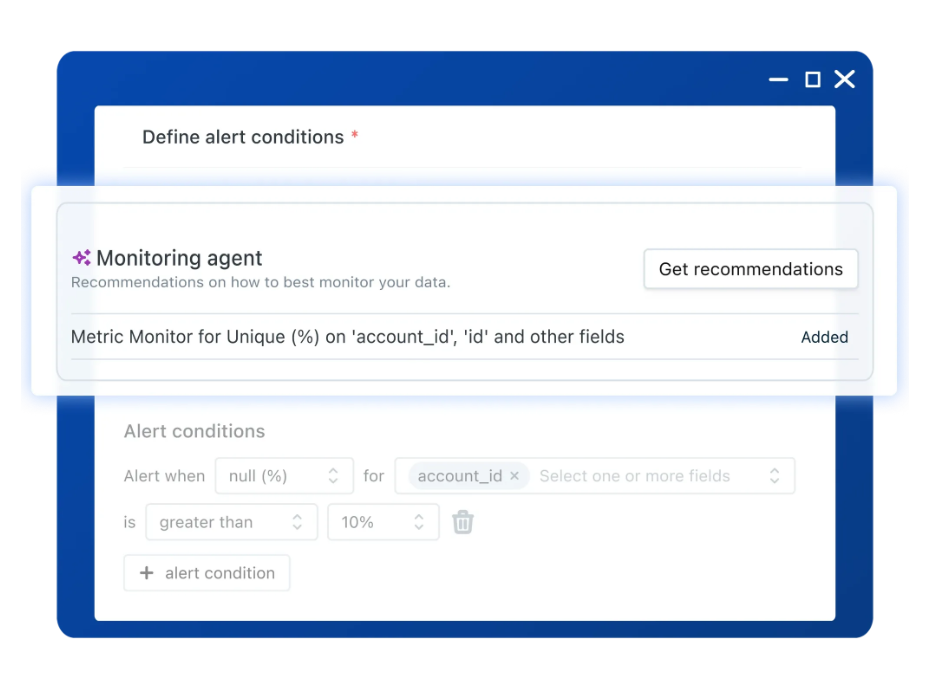
Sifflet’s AI uses context to indicate lineage and recommend precise monitoring in order to avoid alert fatigue.
Thanks to Sifflet’s AI you can prioritize your alerts so you can focus on the most important actions and issues that come your way.
Sifflet, on the other hand, offers an AI copilot that holds 3 different AI agents:
- Sentinel
Sentinel “watches over” your whole data pipeline and reads your metadata, instead of scanning rows. This allows to spot issues in their earliest stage, before there is any real impact.
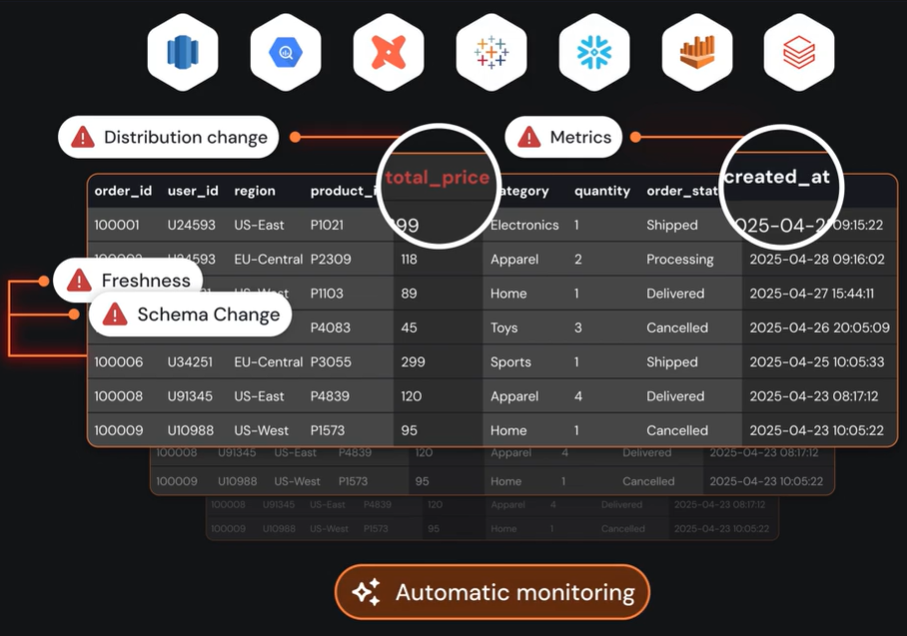
Sentinel tracks lineage, freshness, schema drift, and usage patterns. Then it uses AI to interpret your metadata and predict risks.
Because it offers metadata context, it is able to recommend strategic monitoring based on your data environment.
Thanks to Sentinel, Sifflet can scale observability coverage intelligently, without over-monitoring.
- Sage
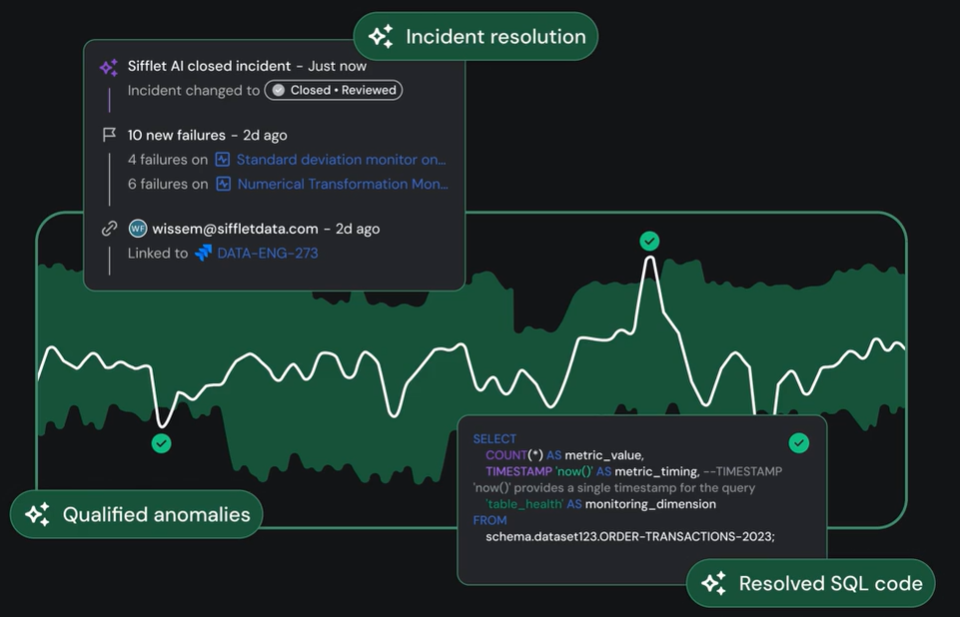
Sage will act as a kind of AI detective. When there is an issue, its AI will be able to trace past and present events that led to that particular problem, and give a full narrative of the issue and lineage.
It joins metadata from lineage, query logs, code changes, and historical incidents to construct an accurate timeline, therefore making root-cause analysis quicker and more effective.
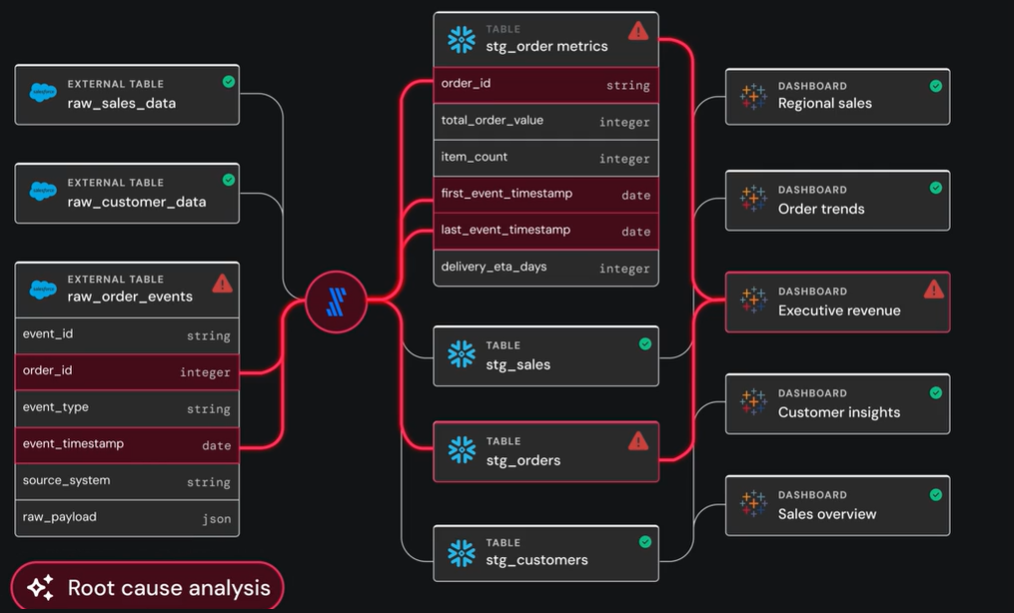
- Forge
Forge studies past fixes, identifies patterns, and drafts tailored solutions grounded in your own operational history.
Forge is basically your “fixer”. Once you have identified the root cause, Forge helps you on the resolution with suggestions and context.
By learning from previous problem resolutions, Forge offers a clear resolution path, where everything is traceable with context from your workflows.
However, don’t worry, because the decision will be ultimately yours. Forge gives you the tools and instructions, but does not take control over your resolution.
Onboarding and UX
As we have mentioned previously, Monte Carlo is tailored for technical users, so initial set up requires specific knowledge on configuration screens, setting up alert rules and metadata structures.
Monte Carlo has a clean interface, although it requires experience with data schemas and metadata.
Sifflet, on the other hand, can be set up in under 10 minutes. It is desgined for everyone.
Users can connect their data sources without using codes, SQLs, or metadata expertise. Additionally, business teams are able to configure their own alerts.
Sifflet defends accessibility through a natural-language wizard, where users can describe their requests for the data observability tool and the system will intelligently interpret and configure the appropriate monitor.
Sifflet’s interface offers a guided, natural-language-driven experience that adapts to both technical and non-technical users.
Integrations
No data observability tool can work without strong integrations into other tools that make up your data platform, or communication tools (such as Slack).
Monte Carlo offers many integrations across the data stack, including data warehouses like Snowflake, transformation tools like dbt, orchestration platforms such as Airflow, and BI tools like Looker.
However, not all integrations have the same depth. Some integrations prioritize anomaly detection over deep metadata insight, and full functionality may require engineering configuration.

As we have mentioned, Sifflet focuses on storing context gathered from your full data pipeline, so integrations include deep hooks into your data catalog, BI tools, and custom metadata sources.
Sifflet connects seamlessly to cloud data warehouses like Snowflake, BigQuery, Redshift, and Databricks; transformation tools like dbt and Airflow; ingestion platforms such as Fivetran and Kafka; and BI tools including Looker, Tableau, and Power BI.
Sifflet reads lineage, freshness, usage, and schema signals,therefore allowing smarter, cost-efficient observability that scales with your stack.

So… Sifflet or Monte Carlo?
Both tools offer solid data observability capabilities and aim to help you analyze your data pipeline and data quality.
However, choosing one or the other will make a huge difference in your efficiency and overall results.
While choosing Monte Carlo will reduce data downtime, data observability should be about improving your data quality with context and offering access to the entire enterprise.
Choosing Sifflet over Monte Carlo means:
%2520copy%2520(3).avif)












-p-500.png)
