



Data doesn’t just support your business anymore. It is your business.
Your data will flow and affect multiple departments and decisions throughout its lifecycle, and a single error will impact all downstream systems.
Now, imagine the mistake occurs as raw data is imported into your system.
A strong data ingestion strategy will guarantee your data’s reliability is off to a good start.
What is Data Ingestion?
Data ingestion is the process of collecting, importing, and processing data from various sources into a storage system where it can be accessed, analyzed, and used for business operations.
Think of it as the entry point for all data flowing into your organization's analytical ecosystem.
Unlike simple data copying, ingestion involves intelligent routing, transformation, and validation to ensure data arrives in a usable format.
This process handles everything from a bank's transaction records to a hospital's patient monitoring systems or a manufacturing plant's sensor data.
Where Does Data Ingestion Stand in Your Data Platform?
In your data platform, data ingestion serves as the crucial first layer that feeds downstream processes.
It sits between your operational systems, such as source databases, applications, or APIs, and your analytical infrastructure, like data warehouses, data lakes, and business intelligence tools.
A data lake is a centralized repository that stores structured and unstructured data at any scale, while a data warehouse is a structured system optimized for analysis and reporting.
Data ingestion determines how quickly and reliably your organization can respond to changing business conditions.
Data Ingestion vs Data Integration
While these terms are often used interchangeably, they serve distinct purposes in your data strategy.
Data ingestion focuses specifically on the initial collection and loading of data from source systems into storage destinations. It's the first step in your data pipeline, emphasizing speed, reliability, and minimal transformation.
Data integration encompasses the whole process of combining, harmonizing, and synchronizing data from multiple sources to create a unified view for analysis and decision-making.
Data Ingestion Process
Effective data ingestion follows a structured three-step process that ensures data quality and reliability from source to destination.
.avif)
Step 1: Data Collection
The collection phase identifies and connects to several data sources across your organization. Modern businesses typically gather data from:
- Databases and data warehouses
Traditional relational databases (PostgreSQL, MySQL, Oracle) and cloud data warehouses (Snowflake, BigQuery) that contain transactional and historical business data.
- APIs and web services
Application programming interfaces that provide real-time access to external services, partner systems, and SaaS applications like Salesforce, HubSpot, or financial market data feeds.
- Log files and application data
System logs, application performance metrics, security events, and user behavior tracking data that provide operational insights.
- IoT and sensor data
Connected devices in manufacturing facilities, smart building systems, vehicle telematics, and environmental monitoring equipment that generate continuous data streams.
- File-based sources
CSV files, JSON documents, XML feeds, and other structured or semi-structured data formats shared via FTP, cloud storage, or email systems.
For example, a healthcare organization might collect patient vitals from medical devices (IoT), billing information from their ERP system (database), appointment scheduling data via APIs, and compliance logs from various applications.
Step 2: Transformation
The transformation phase ensures data arrives in a consistent, usable format. This involves several critical activities:
- Data cleaning
Removing duplicates, correcting formatting inconsistencies, and handling null or invalid values.
For example, a financial services firm might standardize date formats across different trading systems or remove test transactions from production data.
- Data validation
Checking that incoming data meets expected schemas, data types, and business rules.
This prevents downstream issues when a manufacturing company's sensor data suddenly reports impossible temperature readings or when customer IDs don't match expected formats.
For instance, a healthcare provider might validate patients’ age range (e.g., 0–120 years), or an e-commerce company could ensure that product prices are positive numbers and order IDs follow a specific pattern.
- Data Structuring
Converting data into standardized formats and schemas that align with your storage destination requirements.
This might involve flattening nested JSON from APIs or normalizing data from different regional systems.
Step 3: Loading
The final phase delivers transformed data to its destination storage system:
- Data lakes
Data lakes are perfect if you need to store large volumes of raw or minimally processed data in various formats.
A media company might load video metadata, user engagement metrics, and content performance data into a data lake for future analysis.
- Data warehouses
Data warehouses hold structured data that is ready for analysis and supports your business intelligence and reporting needs.
A bank might load processed transaction data, customer demographics, and risk metrics into a data warehouse for regulatory reporting.
- Real-time systems
These stream processing platforms and operational databases that require immediate data availability for applications like fraud detection, recommendation engines, or automated trading systems.
ETL vs ELT
Two primary approaches dominate modern data ingestion architecture, each with distinct advantages depending on your use case.
ETL (Extract, Transform, Load) processes data transformation before loading it into the destination system. Imagine a traditional assembly line where raw materials are processed and refined before entering the warehouse.
On the other hand, ELT (Extract, Load, Transform) loads raw data first, then performs transformations within the destination system using its processing power. This is like bringing raw materials directly into a smart warehouse that can process them on-demand.
Most modern organizations adopt a hybrid approach, using ETL for sensitive or well-defined data sources while applying ELT for exploratory analytics and rapidly changing data requirements.
Types of Data Ingestion
Different business requirements demand different ingestion approaches, each optimized for specific latency, volume, and processing needs.
1. Batch Ingestion
Batch ingestion processes data in scheduled, discrete chunks rather than continuously.
This approach works well for scenarios where immediate data availability isn't critical.
Traditional batch processing handles large volumes of data during off-peak hours, typically daily or weekly.
An insurance company might process claims data overnight, updating risk models and generating regulatory reports without impacting daytime operations.
While micro-batching processes smaller data chunks more frequently (every few minutes or hours) balancing processing efficiency with reduced latency.
A logistics company might update delivery tracking information every 15 minutes, providing near real-time visibility without the complexity of true streaming.
Batch ingestion advantages include predictable resource usage, simplified error handling, and cost-effective processing of large data volumes. However, it introduces latency that may not suit time-sensitive applications.
2. Real-Time Ingestion or Streaming Ingestion
Real-time ingestion processes data continuously as it arrives, enabling immediate analysis and response. This approach is essential for applications that require instant decision-making.
Financial trading platforms use real-time ingestion to process market data feeds, enabling split-second trading decisions. Similarly, fraud detection systems ingest transaction data in real-time to identify and block suspicious activities before they complete.
Streaming ingestion excels in scenarios that require immediate alerts, live dashboards, or automated responses to changing conditions. A smart grid operator might use real-time ingestion to monitor power consumption and automatically adjust generation capacity to prevent outages.
The trade-offs include increased infrastructure complexity, higher operational costs, and the need for specialized expertise in stream processing technologies.
3. Lambda Architecture
Lambda architecture combines batch and real-time processing to balance the benefits of both approaches. This hybrid model keeps separate processing paths for different data types and use cases.
The batch layer processes complete datasets to generate comprehensive, accurate views of business metrics. Meanwhile, the speed layer handles real-time data to provide immediate insights and alerts. A serving layer combines both outputs to present unified results to end users.
A telecommunications company might use lambda architecture to monitor network performance. The batch layer analyzes historical usage patterns to optimize network capacity planning, while the real-time layer detects and responds to immediate service disruptions or usage spikes.
This approach provides comprehensive historical analysis and immediate operational responsiveness, though it requires two separate processing infrastructures.
Why Do You Need Data Ingestion?
Data ingestion has several uses cases within your business, including:
- Analytics and reporting
Modern business intelligence depends on timely, accurate data ingestion to provide meaningful insights.
A healthcare system might ingest patient flow data, treatment outcomes, and resource utilization metrics to optimize staffing levels and improve patient care quality.
Effective ingestion ensures analysts have access to complete, current datasets for strategic planning, performance monitoring, and regulatory compliance. Poor ingestion leads to incomplete reports, delayed insights, and misguided business decisions.
- AI/ML model training
Machine learning models require large volumes of high-quality training data to produce accurate predictions.
A financial institution that is developing fraud detection models needs to ingest transaction patterns, customer behavior data, and historical fraud cases to train effective algorithms.
Data ingestion quality directly impacts model performance.
Inconsistent data formats, missing values, or delayed updates can degrade model accuracy and lead to poor business outcomes. Real-time ingestion also allows constant model retraining to adapt to changing patterns.
- Compliance and audit readiness
Regulatory requirements demand comprehensive data tracking and retention capabilities.
A pharmaceutical company must ingest and preserve clinical trial data, manufacturing records, and adverse event reports to demonstrate regulatory compliance.
Effective ingestion creates auditable data trails, ensures complete data capture, and protects data integrity required for regulatory scrutiny. This reduces compliance risks and simplifies audit preparation.
- Operational monitoring
Real-time operational visibility requires continuous data ingestion from various systems and sensors.
A manufacturing facility might ingest equipment performance data, production metrics, and quality measurements to prevent downtime and optimize efficiency.
Operational monitoring depends on reliable, timely data ingestion to enable predictive maintenance, quality control, and resource optimization. Ingestion failures can blind operators to critical issues, leading to costly disruptions.
Best Practices for Data Ingestion
Implementing effective data ingestion requires attention to several critical practices that ensure reliability, performance, and maintainability:
1. Clean and validate data from the start
Implement data quality checks at the earliest possible stage to prevent issues from propagating downstream.
Establish clear data validation rules based on business requirements and expected data characteristics.
- Next steps?
Create data quality checkpoints that validate format, completeness, and business logic before data enters storage systems.
Document expected data schemas and maintain validation rules as business requirements evolve.
2. Detect and resolve schema drift
Data sources frequently change their structure, adding fields, modifying data types, or reorganizing information hierarchy.
Implement automated schema monitoring to detect these changes before they break downstream processes.
- Next steps?
Establish schema versioning and change notification processes. Create flexible ingestion pipelines that can handle minor schema variations while alerting administrators to significant structural changes.
3. Monitor in real-time
Implement comprehensive monitoring for data flow rates, processing latencies, error rates, and system health metrics. Real-time monitoring allows fast response to issues before they impact business operations.
- Next steps?
Set up automated alerts for ingestion failures, performance degradation, and data quality issues. Create monitoring dashboards that provide visibility into ingestion health across all data sources.
4. Apply data governance standards
Establish consistent policies for data classification, access controls, retention periods, and privacy protection.
Data governance ensures ingested data meets organizational and regulatory requirements.
- Next steps?
Define data governance policies before implementing ingestion pipelines.
Create automated enforcement mechanisms for data classification, encryption, and access controls based on data sensitivity levels.
5. Ensure scalability and fault tolerance
Design ingestion systems that can handle growing data volumes and recover from failures with ease. Implement redundancy, error recovery, and capacity planning to maintain reliable operations.
- Next steps?
Build ingestion pipelines with horizontal scaling capabilities and automated failover mechanisms. Regularly test disaster recovery procedures and capacity limits under realistic load conditions.
Best Data Ingestion Tools
Selecting the right ingestion tools requires evaluating several key factors: the breadth of data source connectors, scalability to handle growing data volumes, reliability and fault tolerance capabilities, and comprehensive monitoring features for operational visibility.
Ingestion tools should provide pre-built connectors for common data sources, reducing development time and maintenance overhead.
Scalability ensures the solution can grow with your business without requiring architectural overhauls.
Reliability features like automatic retry mechanisms and error handling prevent data loss during system disruptions.
Monitoring capabilities provide operational visibility essential for maintaining production systems.
Cloud Data Warehouses
Snowflake leads this category with robust ingestion capabilities built into their cloud data warehouse platform.
Snowflake provides native connectors for major databases, cloud storage systems, and streaming platforms, with automatic scaling to handle variable data volumes.
The platform excels in enterprise environments requiring strong security, compliance features, and support for both structured and semi-structured data. Its separation of compute and storage allows cost-effective processing of large ingestion workloads.
However, Snowflake's ingestion capabilities work best when targeting Snowflake as the destination warehouse, which may limit flexibility for multi-warehouse environments.
ETL/ELT Platforms
Fivetran specializes in automated data pipeline management with over 400 pre-built connectors for popular business applications, databases, and cloud services.
The platform automatically handles schema changes, provides built-in data transformation capabilities, and offers transparent pricing based on data volume.
Fivetran shines in organizations seeking minimal maintenance overhead and rapid deployment of new data sources. Their automated approach reduces the expertise required for pipeline management while providing enterprise-grade reliability.
However, Fivetran’s strength in automation can become a limitation if you need extensive custom transformation logic or need to integrate with proprietary systems not covered by existing connectors.
Stitch (owned by Talend) provides a more developer-friendly approach to data ingestion with open-source foundations and extensive customization options.
It offers competitive pricing for smaller data volumes and supports both ETL and ELT patterns.
Stitch works well for organizations with technical teams capable of managing more complex configurations and custom integrations. The platform provides good balance between automation and flexibility.
However, Stitch requires more hands-on management compared to fully automated solutions and may lack some enterprise features.
Stream Processing Platforms
Apache Kafka dominates real-time data streaming with unparalleled throughput, durability, and ecosystem integration.
Kafka excels at handling high-volume data streams from multiple sources while providing exactly-once delivery guarantees.
Organizations with significant real-time processing requirements and technical expertise find Kafka invaluable for building scalable streaming architectures. Its open-source nature and extensive ecosystem provide flexibility and cost advantages.
Kafka's complexity requires specialized expertise for deployment, configuration, and ongoing maintenance. It's best suited for organizations with dedicated platform engineering teams and significant streaming data requirements.
Analytics and Monitoring Platforms
Splunk combines data ingestion with powerful analytics capabilities, particularly strong for log data, security monitoring, and operational intelligence.
Splunk can ingest virtually any machine-generated data and provides immediate search and analysis capabilities.
The platform is particularly useful if you need immediate operational insights from diverse data sources, particularly for security, compliance, and troubleshooting use cases. Its universal data acceptance and powerful query language provide flexibility for exploratory analysis.
Splunk's pricing model based on data volume can become expensive for large-scale ingestion, and its strength in operational use cases may not align with traditional business intelligence requirements.
What Happens After Data Ingestion?
Data ingestion serves as the foundation for data management capabilities that drive business value.
Once data flows reliably into your systems, three critical areas determine your organization's ability to extract meaningful insights and maintain competitive advantage.
What comes next?
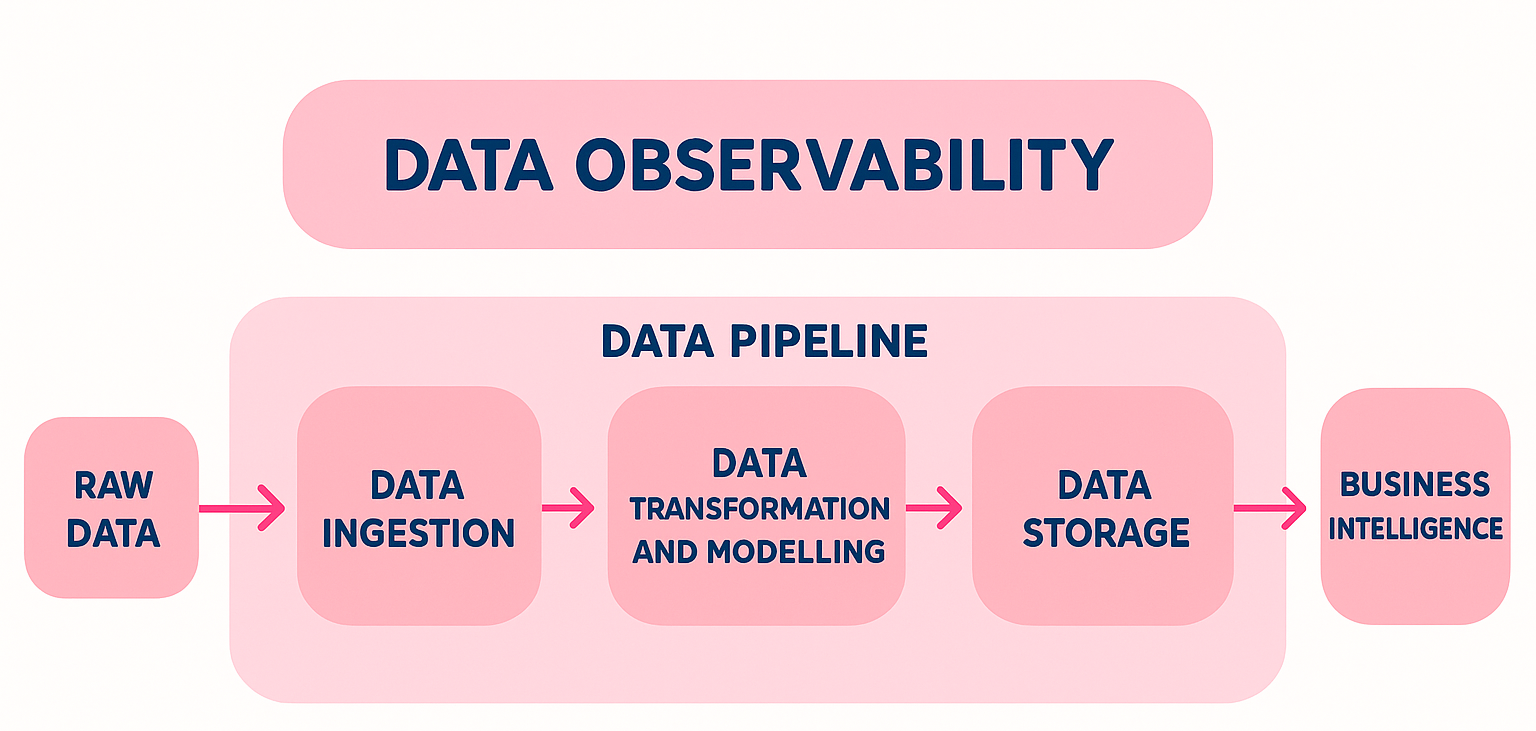
- Data observability tools monitor data quality, track lineage from source to consumption, and provide early warning systems for data issues that could impact business decisions.
- Data governance transforms a compliance checkbox into a strategic capability that ensures ingested data meets organizational standards for quality, security, and accessibility.
- Advanced analytics leverages reliably ingested data to power machine learning models, predictive analytics, and automated decision-making systems.
Essentially, better ingestion offers more comprehensive observability, which improves governance, which in turn supports more sophisticated analytics that allow you to make better and more profitable business decisions.















-p-500.png)
