




Anomalo describes itself as an AI-powered data quality monitoring platform that detects data issues, alerts its data users, and finds the root cause automatically across your entire enterprise.
This review examines how Anomalo’s core features perform in practice across detection, diagnostics, and resolution of data quality issues. We summarize real-user feedback, highlight the platform’s strengths and tradeoffs, and compare its capabilities to Sifflet’s approach to enterprise-grade observability.
What is Anomalo?
Anomalo is an AI-powered data quality platform that uses unsupervised machine learning to detect anomalies and other data quality issues.
It does so by learning the typical patterns of warehoused data without relying on predefined rules, thresholds, or validation checks. This pattern-based approach is advantageous for spotting subtle shifts, especially in large, stable datasets.
Connecting to cloud warehouses like Snowflake, BigQuery, and Databricks, it performs scheduled scans of tables and alerts on changes in volume, schema, or data distribution.
Who is Anomalo For?
Anomalo is well-suited for large enterprises with a mature data infrastructure and established data operations. It offers a practical solution for those with substantial volumes of analytical data, where table volume and flow complexity make manual rule-writing impractical.
The system performs best in environments with stable pipelines, clear data ownership, and teams ready to act on ML-driven insights.
Organizations focused on automation and low-effort anomaly detection tend to see value early, particularly when Anomalo’s outputs are integrated into a broader governance or stewardship model to guide follow-up activities.
Who Shouldn’t Use Anomalo?
Smaller organizations or those still building stable data architectures may struggle to realize value from Anomalo. The platform assumes a mature infrastructure, established data governance processes, and the expertise to act on ML-generated insights.
Anomalo runs daily by default, checking tables after new data is fully delivered. While custom schedules are supported, it's not optimized for real-time or streaming data, making it a weaker fit for those needing instant visibility into dynamic data environments.
Additionally, while Anomalo offers no-code validation options and supports some customization through SQL and APIs, its primarily ML-driven approach can prove limiting for enterprises using complex, domain-specific rules or extensive policy logic.
Our Verdict: Anomalo fits larger enterprises with a modern data stack and mature data operations. It's not as well-suited for smaller organizations, real-time use cases, or those still developing their data infrastructure.
Anomalo’s Core Features
From anomaly detection to governance, the technology offers a broad set of tools for managing data quality in both structured and unstructured sources.
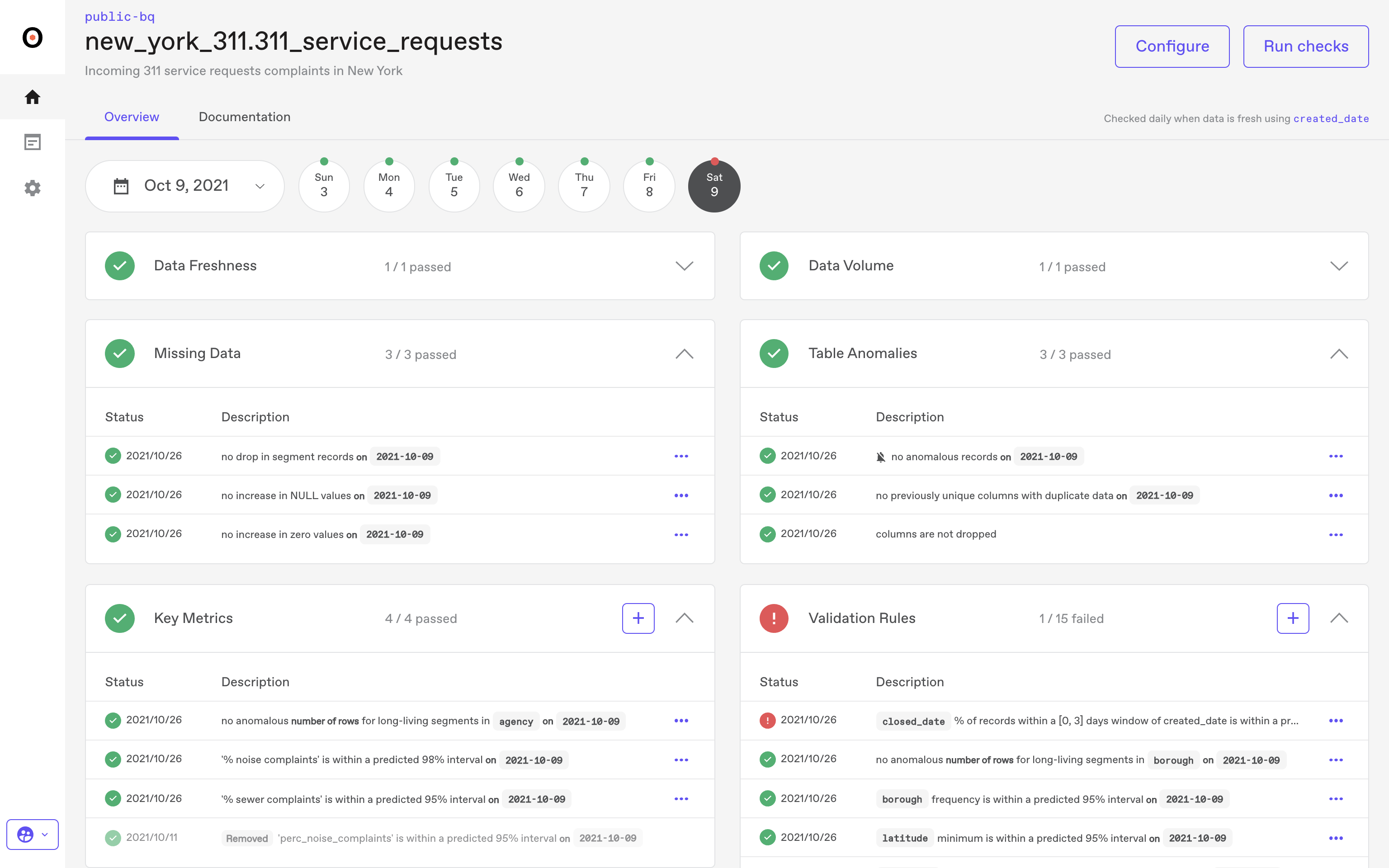
Automated Anomaly Detection
Anomalo uses machine learning to set a baseline of expected values and distributions for each table. It recognizes anomalies when new data deviates from these learned patterns.
This pattern-based detection helps identify unexpected shifts in volume, structure, and distribution without manual thresholds or rules.
It learns the normal patterns of data within key tables and identifies anomalies, including unexpected issues that humans may not anticipate.
The system scales effectively to handle growing data volumes and complexity, while remaining accessible through both APIs and no-code configuration.
You can customize detection thresholds to align with your priorities, and each alert includes a severity score to guide response.
Smart alerts reduce noise by adapting to the data, offering automated routing, built-in triage, and root cause analysis. In addition, the system tracks how data patterns and KPIs evolve over time, detects spikes and drops in specific segments, and identifies when models need retraining due to data drift.
Data Governance Features
Anomalo supports enterprise governance with role-based access controls, audit trails, SOC 2 compliance, and in-VPC deployment.
Anomalo’s data governance features provides tools to ensure data integrity, compliance, and security across your data ecosystem.
The platform combines governance and data quality management by using AI-driven anomaly detection to monitor data automatically and highlight potential risks. You can view data quality information for all tables at a glance, set validation rules, and track compliance thresholds to streamline regulatory adherence.
Anomalo integrates quality insights into data catalogs like Alation, notifying teams of outages or incidents, and minimizing issues during migrations or source integrations.
For sensitive assets, the system offers robust protections, including SOC 2 Type II certification, HIPAA compliance, in-VPC deployment to keep data within the organization’s systems, and role-based access controls.
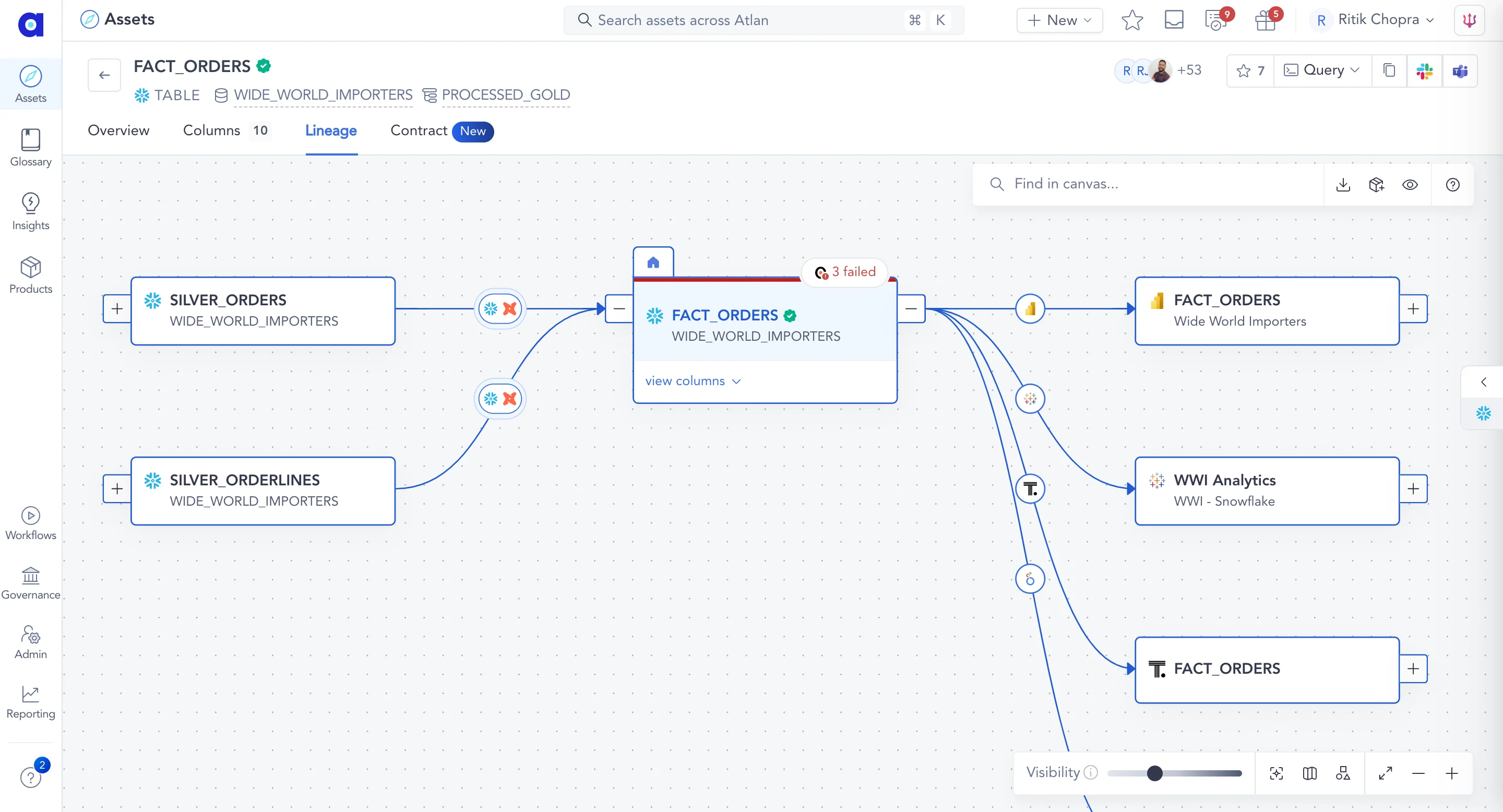
Automated Data Lineage
Anomalo offers lineage tools so you can track how your data flows from its raw source up to its destination.
The tool delivers a clear, visual representation of data movement, showing both upstream sources and downstream consumers while pairing lineage information with data quality checks.
Anomalo supports both API and no-code configuration, so it can be used and understood by business teams too.
Its lineage view speeds up the triage process by connecting real-time alerts to visual data flows, allowing you to assess downstream effects quickly.
Additionally, it helps detect ripple effects by clustering related issues across multiple tables, enabling faster root cause identification and resolution.
Unstructured Data Monitoring
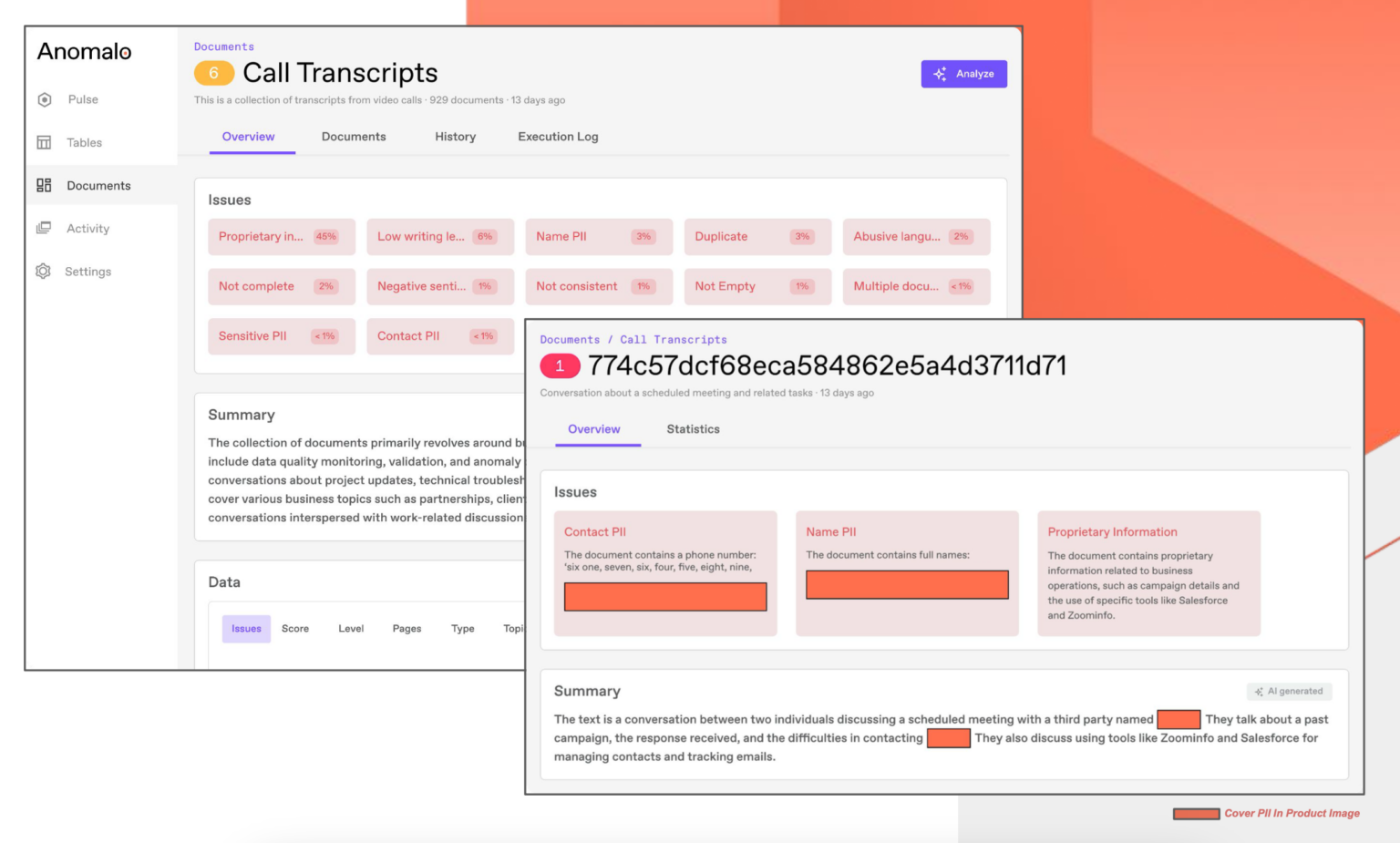
With Anomalo you can measure, monitor, and enhance the quality of their unstructured document data, such as customer support transcripts, user-generated content, and regulatory reports, before using it for AI and analytics initiatives.
The system uses LLM to automatically detect a wide range of quality issues, including missing metadata, corrupted files, unreadable formats, sensitive PII, and proprietary content.
Each document receives a quality score from 1 to 10, so you can prioritize fixes and ensure that unstructured data is complete, safe, and AI-ready.
Anomalo Unstructured Data Monitoring also transforms unstructured data into actionable business intelligence. By combining metadata filters and natural language prompts, you can identify relevant documents, uncover emerging trends, detect customer sentiment, or highlight potential revenue opportunities.
Integration with Modern Data Stacks
Anomalo integrates natively with major cloud warehouses and lakehouses like Snowflake, Redshift, and Databricks. It also supports metadata extraction and webhook triggers for tools like dbt and Airflow.
Governance teams can connect Anomalo to major data catalogs and route alerts through Slack or Jira for automated ticketing.
Anomalo can also be integrated directly into Atlan’s metadata lakehouse so you can monitor both structured and unstructured data and collaborate on unified context.
User Reviews: What Customers Like and Don’t Like
G2 4.4/5 | Gartner 4.8/5
Reviewers repeatedly cite the service's unsupervised ML, out-of-the-box setup, and clean dashboards as key reasons they can catch problems early without the usual configuration grind.
Enterprise users call out the platform's scalability, API access, and Python SDK as differentiators. Frequent feature updates and a responsive support team also earn high marks.
But the feedback isn't all glowing.
False positives and alert fatigue are mentioned often. Some users report that tuning sensitivity or suppressing low-priority alerts takes more effort than expected. And in high-volume environments, reviewers noted degraded performance when scanning wide or complex datasets.
Users praise Anomalo for fast setup, intelligent anomaly detection, and strong enterprise support. Yet, reviewers found it offers limited help resolving them, leaving engineering teams to manage triage, root cause, and remediation on their own.
Anomalo’s Pros and Cons
To better understand the platform, here's where the product excels and where challenges may arise.
✔️ Pros
- Fast setup, minimal configuration
Connects quickly to cloud warehouses and begins monitoring with no custom rules or validation logic required.
- Strong ML foundation for detecting unknown issues
Unsupervised machine learning finds unexpected changes in data distribution, volume, and structure; anomalies that rule-based systems often miss.
- Scales well in enterprise environments
Supports petabyte-scale deployments and thousands of monitored tables across large, distributed teams.
- Broad integration support
Connects with Snowflake, BigQuery, Databricks, Redshift, dbt, Airflow, Alation, Slack, and Jira to embed anomaly alerts into existing workflows and governance tools.
✖️ Cons
- Limited rule customization
Anomalo comes with 40+ no-code checks and allows for some customization through SQL and APIs. That works well for basic validation, but when layered policy logic or domain-specific rules are desired, it comes up short.
- Frequent false positives
Unsupervised detection can misclassify seasonal shifts or benign changes as anomalies, resulting in excessive noise.
- Static lineage
Anomalo’s lineage diagrams are generated from static metadata but aren’t integrated into live monitoring. They lack field-level resolution, don’t trace dynamic dependencies, and can’t connect how data quality issues impact downstream systems.
- Issue detection without context
Anomalo flags anomalies, but doesn't rank them based on their impact on business context and outcomes. With no trust scoring or triage support, resolution teams are left to sort important signals from noise.
- Lacks real-time monitoring
By default, Anomalo runs anomaly and freshness checks once per day. Custom schedules are supported, but standard runs don’t catch ingestion failures or streaming disruptions in event-driven pipelines or any use case that requires real-time visibility.
- Per-table pricing
Anomalo charges based on the number of tables monitored. As coverage expands, so do costs. Many users report pricing surprises during proof-of-concept phases and full rollout.
Custom schedules don’t carry a direct fee but can increase costs indirectly. More frequent checks across more tables raise usage, especially at scale, potentially triggering elevated expense.
With these pros and cons in mind, it leads us to the main question:
How does Anomalo stack up against Sifflet?
Anomalo vs Sifflet
On paper, both Anomalo and Sifflet offer anomaly detection, metadata insights, and integration with modern data stacks. But their philosophies—and the outcomes they drive—are fundamentally different.
Sifflet offers context-aware anomaly detection.
When a schema change sneaks into your nightly load, Anomalo’s unsupervised ML flags the deviation immediately. You’ll get an alert, but left to figure out what broke, where it broke, and who needs to care.
Sifflet takes a different approach. Its hybrid model combines machine learning with policy-based logic and field-level lineage. That exact schema change is still detected, but it’s escalated for resolution if it affects a critical column, breaks a business rule, or threatens a key dashboard. The alert is also accompanied by context on impacted assets, potential owners, and downstream risk, so your team can act quickly to resolve it.
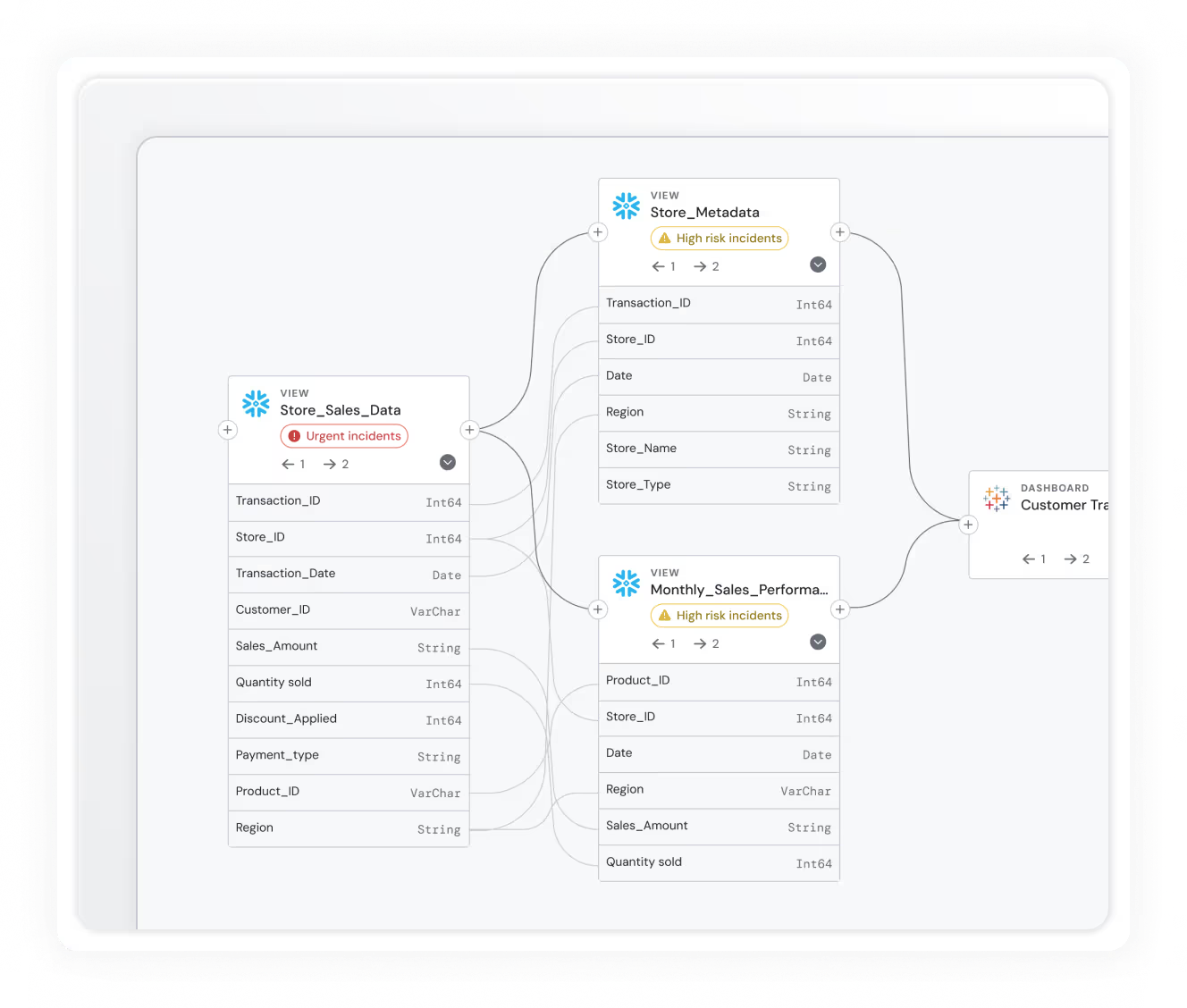
Anomalo sends alerts to Slack, email, or ticketing tools. But those alerts often arrive with limited context. Engineers must investigate column-level metrics, sift through lineage diagrams, and reconstruct the impact on their own.
Sifflet automates that entire process with a system of AI agents, each designed for a specific stage of incident response. Sentinel detects, Sage triages, and Forge traces issues to their root cause. Every alert is enriched with ownership, severity, impacted assets, and audit details. Jira tickets are created automatically, so incident response starts with context, not guesswork.
Anomalo is fast to deploy, connecting to warehouses and monitoring tables within hours. However, costs scale with the number of tables monitored. Many users report pricing surprises during proof-of-concept phases and full rollout.
Sifflet uses volume-based pricing and centralized watchlists. Setup may take longer, but once policies are in place, new datasets inherit rules automatically. The platform scales efficiently with shared logic, reusable policies, and alerting that prioritizes what matters to keep costs under control as coverage expands.
Is Anomalo the Right Fit?
Considering our findings and combined with real-world user feedback, here's the verdict:
Anomalo can be a good fit for large enterprises seeking rapid deployment and hands-off detection, especially when teams are in place to manage triage manually.
Sifflet’s AI-Native observability platform is better suited for organizations prioritizing end-to-end observability, cross-functional accountability, and resilience at scale. Teams with complex pipelines, regulatory demands, or limited engineering bandwidth benefit most from Sifflet’s automation and AI-driven workflows.
Anomalo only detects what’s wrong.
Sifflet helps you fix it. Faster, with context, and at scale.
If you’re ready to move from alert fatigue to intelligent, business-aware observability, book a demo and see how Sifflet puts trust at the core of your data strategy.















-p-500.png)
