




Considering Bigeye for data observability?
Sure, it's a powerful platform. But not everyone wants to speak in YAML.
This guide breaks down the 5 best alternatives to Bigeye, each offering a slightly different path to data reliability.
Whether you're after faster deployment, simpler configuration, or more robust AI-powered safeguards, the goal is the same: finding the tool that best fits your stack, workflows, and technical bandwidth.
So. Is Bigeye the right fit? Let's take a look and explore the alternatives.
What Bigeye Does and Lacks
Bigeye delivers enterprise-grade data observability for modern and legacy data stacks.
Its strength is early detection, to catch changes in freshness, volume, and schema to spot anomalies. With column-level monitoring of critical assets, it scans metadata to spot issues at their source, before they hit production.
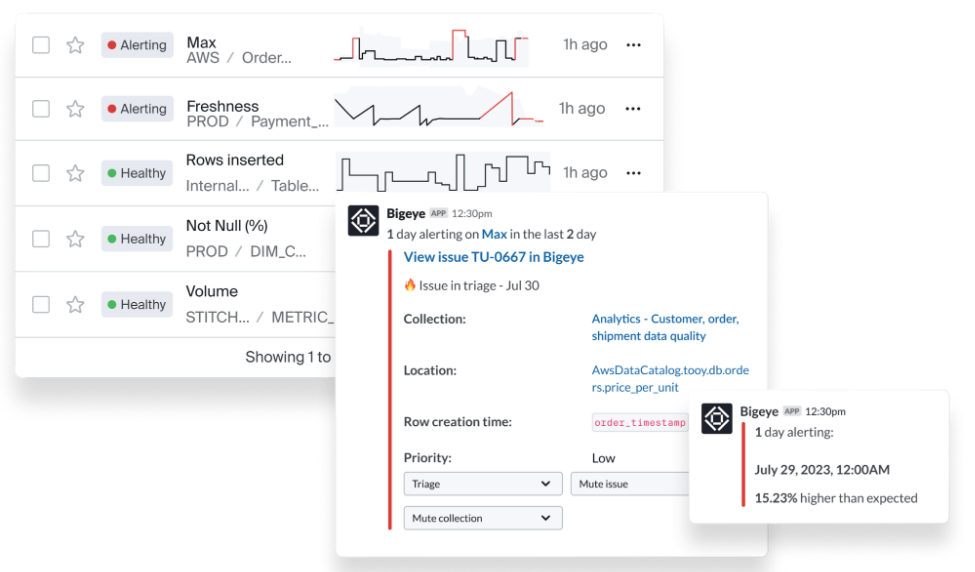
Bigeye also offers granular control. While the platform offers reusable YAML templates and adaptive thresholds to jumpstart monitoring, platform leads and engineers can code their own SQL-based checks and custom monitors to enrich detection.
And Bigconfig, its configuration engine, integrates with Git and Terraform for platform management, so it can be managed like any other app in the software stack.
Yet, with extensive control comes trade-offs in accessibility. Bigeye will challenge non-technical users lacking the specialized skills required to operate it.
Bigeye also falls somewhat short in autonomous action. While bigAI, added in 2025, delivers root cause analysis and remediation suggestions, the platform still requires engineering teams to investigate and implement fixes independently.
Bigeye lacks autonomous remediation and self-healing workflows found elsewhere.
Also absent is an agentic layer for autonomous observability. Bigeye is taking a different approach: its forthcoming AI Trust Platform (launching in late 2025) will govern how third-party AI agents access and use data, rather than automating observability actions itself.
Where Bigeye Fits Best
Bigeye is best in the hands of technical users working in mature, code-first environments and large enterprises with hybrid infrastructure. Those most accustomed to infrastructure-as-code and observability run through Git, Terraform, and YAML, will derive the most value from the platform.
Engineering teams that codify, version-control, and deploy pipelines through CI/CD will appreciate Bigeye. So, too, will platform and infrastructure teams writing custom SQL, managing complex DAGs, and employing data contracts in daily operations.
But Bigeye isn't for everyone. Although it offers no-code starting points like Autometrics and low-code visual builders, leveraging it successfully requires SQL expertise and ample time for designing custom checks and YAML configurations.
Without these, the learning curve and operational overhead could prove limiting.
That's where our alternatives come in: tools that deliver data observability without the heavy technical lift.
The 5 Best Bigeye Alternatives for Data Observability
Bigeye isn't the only platform solving data observability.
The tools below offer uniquely competitive strengths: faster time to value, agentic automation, simpler workflows, and broader accessibility.
These are the 5 best alternatives to Bigeye, each solving a different piece of the
observability puzzle.
1. Sifflet
⭐⭐⭐⭐⭐ 4.9/5
Best End-to-End Observability | Best for Business-Centric Observability
Sifflet unifies monitoring, anomaly discovery, and troubleshooting in a single AI-native platform. Field-level lineage provides end-to-end visibility from data ingestion, across cloud warehouses, data lakes, and to BI tools.
Where code-first platforms require manual prioritization via SQL checks, Sifflet automatically identifies and prioritizes the most business-critical assets. It traces data quality and anomalies directly to the dashboards, reports, and business outcomes they affect, revealing impact, not just incidents.
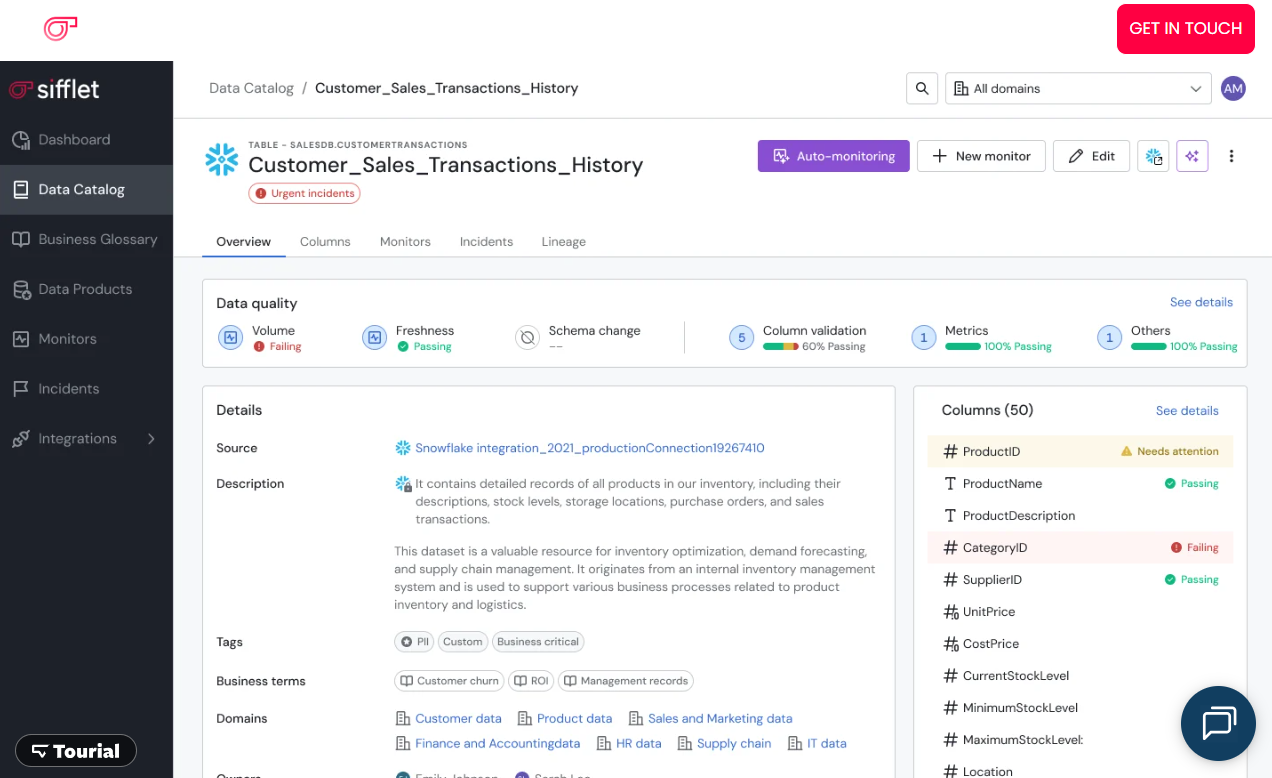
Sifflet’s AI agents automate observability across data’s complete lifecycle:
- Sentinel targets high-impact assets, prioritizing them for monitoring
- Sage traces root causes by linking anomalies to upstream inputs and downstream business impact
- Forge recommends fixes based on pattern recognition and its historical record of incidents
To further enhance and report on data reliability, Sifflet embeds trust scores throughout the platform. These scores appear in its data catalog, lineage graphs, monitoring dashboards, and BI tools, providing asset reliability ratings at every decision point.
Why Choose Sifflet Over Bigeye?
Sifflet eliminates the setup burden that Bigeye brings. While Bigeye demands weeks of YAML-heavy configuration, Sifflet's agent-based model automates asset discovery, threshold tuning, and monitor deployment. Most enterprises start receiving insights in days, not weeks.
Sifflet packs end-to-end observability into a single, AI-native platform. Its agents detect failures in high-value assets, trace root causes, and recommend targeted resolutions. Every alert is accompanied by a complete picture of what broke, where, what was impacted, and what to do next.
Sifflet makes advanced observability accessible across the entire enterprise.
Best Fit for Sifflet
Sifflet thrives where engineers, analysts, and business users need visibility into their data’s reliability. It's especially valuable for fast-moving teams, distributed architectures, and enterprises where self-service data discovery is part of its culture.
Sifflet scales from startups to enterprises. Whether you're managing a single warehouse or complex multi-cloud infrastructure, the platform grows with your data stack without requiring operational changes to your team's workflows.
Sifflet is the best choice when you need total observability that deploys fast, scales easily, and is adopted willingly by both technical and non-technical users.
It's the best alternative to Bigeye for companies ready to move beyond code-first platforms or those without the bandwidth to manage yet another complex platform.
2. Monte Carlo
⭐⭐⭐⭐ 4.7/5
Better for Large-Scale AI-Ready Deployments | Market Leader
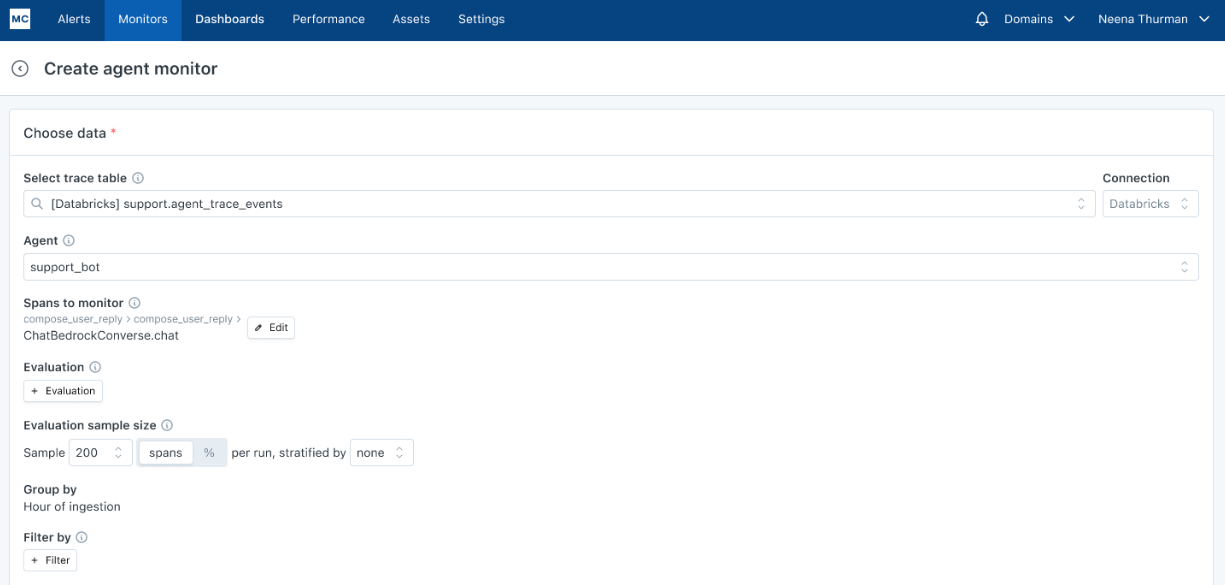
Monte Carlo has recently expanded its platform to include data and AI observability.
It monitors five key dimensions for freshness, quality, volume, schema, and lineage, while tracking data across ingestion pipelines, cloud warehouses, and BI tools. Its newly released AI agents recommend datasets for monitoring, tune thresholds, and investigate root causes autonomously..
A differentiating feature, Monte Carlo supports unstructured data, including PDFs, embeddings, and other document-based assets, integral to AI and LLM initiatives.
With native integrations for Snowflake, Databricks, and BigQuery, the platform pairs intelligent monitor recommendations with built-in incident response tools to accelerate resolution and reduce operational overhead.
Why Choose Monte Carlo Over Bigeye?
Monte Carlo addresses gaps that Bigeye intentionally leaves open. Its architecture prioritizes automation, AI-readiness, and support for unstructured data.
Monte Carlo provides visibility into AI inputs, outputs, and hallucinations through its LLM-as-a-judge monitoring, essential for teams building generative AI or machine learning pipelines. The platform analyzes system behavior, detects quality degradation, and flags potential failures before they reach end users.
For those needing speed, scale, and cross-domain visibility across data and AI assets, Monte Carlo surpasses Bigeye. The trade-off, however, is depth. Like
Bigeye, realizing Monte Carlo’s full potential requires ongoing engineering investment and technical maturity.
Best Fit for Monte Carlo
Monte Carlo serves enterprises building AI-driven data products or managing complex, multi-cloud pipelines.
Experienced data teams that can wield a feature-rich platform are in the best position to extract value from the platform.
Monte Carlo is a better alternative to Bigeye if observability must extend to AI initiatives or unstructured data. It's also more suitable for enterprises striving for hands-free automation over code-first, configuration-heavy approaches like Bigeye.
Just be prepared to support the platform. Monte Carlo, like Bigeye, tailors its approach to technical teams with the time and capacity to support and maintain it.
3. Acceldata
⭐⭐⭐⭐4.5/5
Better for Complex Multi-Cloud Operations | Enterprise-Scale Automation
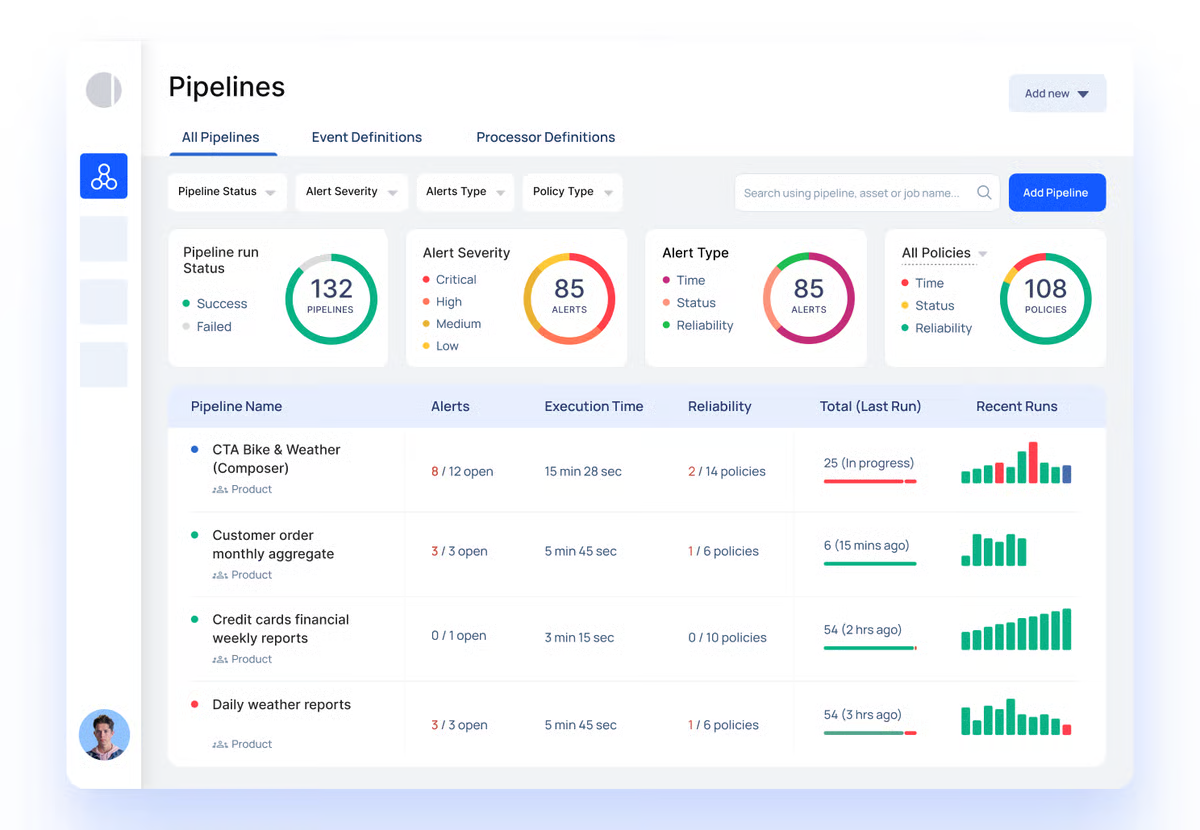
Acceldata takes a fundamentally different approach to observability via autonomous data management. Rather than generating alerts for human investigation, its AI agents autonomously detect problems, execute remediation, and continuously improve based on historical patterns and business context.
The platform monitors five connected domains: data quality, pipelines, infrastructure, usage, and cost. This cross-domain view exposes dependencies that single-focus tools miss. When a pipeline fails, teams immediately see the impact on performance, cloud costs, and downstream outcomes all in one place.
Acceldata handles petabyte-scale workloads across hybrid, multi-cloud, and on-prem environments. It runs natively on Snowflake, BigQuery, Spark, and legacy systems. The platform scales with self-adjusting baselines and auto-tuned thresholds without needing constant configuration.
Why Choose Acceldata Over Bigeye?
Acceldata goes further than Bigeye in two ways: it monitors the five connected domains instead of quality alone, and its AI agents autonomously execute remediation. Bigeye requires manual detection setup and investigation; Acceldata automates both.
For distributed, multi-cloud, or hybrid environments, Acceldata also brings a level of adaptability that Bigeye can't. Its agents learn which alerts matter, adjust sensitivity in context, and elevate issues tied to critical business outcomes.
Where Bigeye expects hands-on tuning and Terraform pipelines, Acceldata prioritizes self-correction and autonomy over manual control.
Best Fit for Acceldata
Acceldata performs well in large-scale and complex enterprises demanding full-spectrum observability. It's a good fit for data and FinOps teams, in particular, who benefit from usage and cost details tied to infrastructure, pipeline, and quality monitoring through a single control plane.
The platform thrives in hybrid and multi-cloud environments where speed, reliability, and cost tradeoffs require constant balancing. Organizations with mission-critical data systems (especially in finance, healthcare, and the public sector) benefit from Acceldata's autonomous operations, flexible deployment options, and built-in governance.
Acceldata delivers broader coverage and deeper automation than Bigeye. Its five-domain model, intelligent agent framework, and multi-cloud support make a compelling case for complex, distributed environments where code-first tools might prove heavy.
However, that scope comes with trade-offs. Acceldata requires clear domain ownership and cross-functional alignment to reach its full potential.
4. Metaplane
⭐⭐⭐⭐ 4.0/5
Better for Rapid Deployment | Fastest Time-to-Value
Metaplane is a fast, developer-friendly, prevention-focused, lightweight observability platform designed for lean teams. It connects in under 30 minutes, with anomaly detection and lineage insights ready the next day.
Metaplane is entirely metadata-driven. It reads schema, freshness, and anomaly signals without touching production data or adding load.
Metaplane is unique in emphasizing prevention over detection through pre-deployment testing. Metaplane's GitHub integration is purpose-built to catch issues before code merges by forecasting downstream impact and running regression tests automatically on dbt pull requests.
Column-level lineage updates automatically, granting visibility into what changed, what broke, and what needs attention without manual tuning and configuration.
Why Choose Metaplane Over Bigeye?
Lean teams want to monitor, not configure.
Bigeye requires YAML configuration, Terraform management, and manual tuning. Metaplane offers similar coverage, but through a no-code interface far simpler to operate.
Metaplane's freemium model and flexible pricing address another critical gap: affordability for leaner budgets. Unlike Bigeye's enterprise sales model, Metaplane teams can start free, pay-as-you-scale, and avoid long-term contracts. This pricing model allows small teams access to production-grade observability without board-level budget approvals.
Best Fit for Metaplane
Metaplane supports fast-moving analytics teams working in modern cloud environments like Snowflake, BigQuery, and Databricks. It's a flexible fit for startups, dbt-native companies, and scale-ups with limited engineering capacity that can't afford months of platform setup and tuning.
Teams that need immediate visibility and impact benefit most from Metaplane's speed-first approach. If your organization values quick time-to-value and operational simplicity over deep infrastructure observability, Metaplane strikes the right balance.
Metaplane is the quickest way to get observability up and running. It delivers immediate value without the engineering lift or warehouse impact for startups and scale-ups.
Yet, it can only do so much. Metaplane is not for complex, multi-domain environments or enterprise-scale governance. As infrastructure expands, so will the need for deeper visibility into costs, pipelines, and infrastructure performance.
If you're early in your observability journey and want a lightweight, production-ready solution, Metaplane is an innovative, low-cost alternative to Bigeye. It's a decent starting point for slightly larger concerns, but not the endgame.
5. IBM Databand
⭐⭐⭐ 3.5/5
Best for Real-Time Pipeline Monitoring | Enterprise-Grade Reliability
IBM Databand is a pipeline-first observability platform built for data operations. Its architecture prioritizes job execution, orchestration reliability, and SLA enforcement, distinguishing it from platforms centered on data quality alone.
Databand connects directly to orchestration tools like Apache Airflow, IBM DataStage, and Snowflake pipelines to monitor real-time execution. It tracks missed tasks, failed jobs, and abnormal run durations across DAGs and flows in a single dashboard for managing pipeline health.
The system profiles historical pipeline behavior, establishing baselines without needing manual thresholds. It applies intelligent anomaly detection to flag deviations in run times, schema, or freshness. When incidents occur, built-in lineage and impact analysis reveal what went wrong, which assets are affected, and where to focus remediation efforts.
Databand integrates tightly within the IBM Data Fabric ecosystem. Aimed at hybrid and multi-cloud environments, it also offers enterprise-grade governance and performance.
Why Choose IBM Databand Over Bigeye?
Databand fills observability gaps that asset-focused platforms like Bigeye can't. Its orchestration-first, pipeline-centric design traces failures to their source and reduces mean time to resolution across complex, interconnected workflows.
While Bigeye focuses on data quality in landed assets, Databand monitors the pipelines and jobs that move data through the stack. It answers operational questions fundamental to managing high-volume pipelines and dense DAGs that Bigeye leaves unanswered.
Best Fit for IBM Databand
Databand appeals to infrastructure and data ops teams managing large-scale, highly orchestrated workflows. It delivers the most value in environments running Apache Airflow or IBM DataStage, where visibility into job execution and pipeline health is critical. For this, Databand easily trumps Bigeye.
The platform excels in mature, stable pipelines managed with centralized orchestration tools. Enterprises placing a premium on uptime and SLA enforcement will benefit most.
Databand is better than Bigeye for enterprises prioritizing pipeline observability and infrastructure reliability. It's particularly attractive to data engineering teams managing complex, multi-platform operations, or those already invested in IBM's data ecosystem.
A caveat, however. Databand is constructed for data engineering workflows like pipeline execution, job monitoring, and orchestration. It lacks depth for data quality monitoring or an analytics-first focus.
So, Which is the Best Data Observability Tool?
Bigeye delivers value. But its code-heavy, configuration-first model limits its attraction. For many, the engineering lift and long setup time make it hard to scale and maintain observability across an enterprise.
Other platforms offer better alternatives depending on their priorities, but Sifflet is best for:
- Fast deployment with minimal engineering support
- Full-stack observability without manual configuration
- AI-native root cause analysis that accelerates resolution
- Cross-functional visibility that empowers data, BI, and business teams alike
- Scalable governance with trust scoring and policy enforcement aligned to risk
For end-to-end observability with a business-first approach, Sifflet is the best alternative to Bigeye for speed, scale, and cross-functional trust.
If you’re still not sure, ask yourself these 8 questions to help you decide:
1. How much engineering bandwidth do you have?
For high bandwith choose Bigeye or MonteCarlo, for high bandwith plus autonomy and speed, choose Sifflet.
2. Are you cloud-native or hybrid?
For cloud-native, choose Sifflet, Metaplane, or Monte Carlo. For a hybrid and flexible implementation, choose Sifflet or Acceldata.
3. What's your primary data challenge?
Bigeye suits engineering-led orgs that want full configuration authority, Monte Carlo supports observability for LLMs, and Sifflet provides full observability.
4. How fast do you need to be up and running?
Less than one hour, Metaplane; less than a month, Sifflet, up to 4 months, Bigeye.
5. Who needs access to observability insights?
If only engineers need insights, Bigeye will do, for a cross-functional system, choose Sifflet.
6. What's your budget and compliance posture?
If you have a flexible budget, choose Sifflet, for groeing teams, choose Metaplane.
7. What's your compliance posture?
Bigeye supports on-prem and air-gapped deployments; strong for regulated industries; Sifflet is a Cloud-native software, with a compliance roadmap expanding for regulated industries.
Metaplane is best for non-regulated cloud environments.
8. How complex is your environment?
For a simple setup, Metaplane is enough, if you have multi-source or cross-domain pipelines, Sifflet if a better option.















-p-500.png)
