




Data is everywhere. And frankly, that's the problem.
You can't find anything.
And even if you do, how do you know it's what you need? How can you be sure it's still current, correct, and trusted?
Metadata. That's how.
What Is Metadata?
Metadata is the story behind your data. It explains what each dataset represents, where it came from, who owns it, and how it should be used.
It's the connective layer that gives raw data meaning. Without it, numbers are just numbers without any context.
A column labeled “amount” shouldn't spark debate. Is it revenue or cost? Before or after tax?
With metadata, those answers already exist. Definitions, ownership, and calculation logic are documented and visible.
Metadata provides the context that makes data usable and trustworthy. A framework in which context travels with the data itself.
Examples of Metadata in Data Systems
In a database, metadata is the table name, column type, and timestamp when someone last modified the data.
In a BI tool, business metadata is the metric definition, calculation logic, source dataset, and the owner responsible for maintaining accuracy.
In a data pipeline, operational metadata records activity and flow. Data lineage traces where data originated, which transformations shaped it, and where it moves next.
Even a business glossary is metadata. It’s the approved definition, steward, and classification tag for critical business terms such as revenue or customer.
These are the details that describe each chapter of your data's story. Metadata.
Why Metadata Matters for Data Governance and Compliance
In data, context is everything.
Metadata is that context.
It creates clarity through lineage and classification; identifying sensitive fields, tagging PII, and tracking ownership so teams know where data lives, who touches it, and what protection it requires.
It reinforces accountability through governance by managing access controls, applying retention rules, and recording who accessed what and when. When regulators or executives ask for proof, metadata provides the evidence.
Metadata for Data Discovery, Speed, and Trust
Metadata also enhances discovery and performance. Analysts can find the right datasets without chasing links or messages. Engineers can trace lineage and resolve issues in minutes. Leaders can validate metrics and make confident decisions based on trustworthy data.
Metadata keeps the rules straight, the records clean, and the work moving, all while making trust the default.
How Metadata Supports Data Teams and Business Users
Every team uses data differently. Metadata gives each one the context to do it better.
Using metadata, analysts can check whether a field labeled amount refers to revenue or cost. They can find trusted datasets faster, understand how each metric is defined, and move from questions to insights without delay.
For data engineers, metadata drives speed and precision. It exposes lineage across systems, showing how data moves and where dependencies exist. That visibility pinpoints the source when anomalies appear and shows which pipelines or dashboards are affected. Troubleshooting becomes targeted instead of trial and error.
Behind the scenes, metadata builds trust. It makes ownership visible, tracks updates, and links data to business outcomes that matter. It gives leaders verifiable context behind every report, dashboard, and decision.
Types of Metadata
Metadata takes many forms. Each one defines, governs, and builds trust in a different dimension of your data.
- Technical Metadata
Technical metadata defines how data is structured and stored.
That's schema details such as table and column names, data types, file formats, and constraints.
This layer is the schematic for machines to read, transform, and query data.
- Business Metadata
Business metadata connects technical details to business meaning.
It defines how data supports operations and reporting, giving everyone a shared understanding of what they're looking at.
It specifies what a metric represents, who maintains the dataset, and where it appears in dashboards.
Business metadata brings producers and consumers together through clear definitions and ownership.
- Operational Metadata
Operational metadata tracks activity within your data environment.
It records refresh schedules, row counts, error logs, and performance metrics.
These signals show whether pipelines are running as expected and whether data is current. Operational metadata keeps the system healthy and responsive.
- Governance Metadata
Governance metadata enforces rules that protect sensitive information and maintain compliance. It defines access permissions, data classifications, PII tags, and audit trails.
This layer turns policy into practice. It controls visibility, safeguards privacy, and provides traceability that regulators demand.
Other types of metadata further complement these core layers:
- Descriptive metadata supports discovery through titles, tags, and summaries.
- Structural metadata explains how tables, fields, and relationships connect.
- Administrative metadata manages lifecycle details such as versioning, ownership, and retention.
Together, they create the intelligence that powers metadata management in data catalogs.
Why Metadata Is Important in a Data Catalog
Metadata is what brings a data catalog to life.
It gives structure its purpose in making data discoverable, explainable, and ready for use.
Metadata provides discovery with context. It turns search into certainty.
When an analyst looks for a "revenue" dataset, metadata discloses which table is production-ready, when it last refreshed, and who owns it.
Instead of tedious searching and repeated checking, a data catalog uses metadata to find the perfect data for every user.
Catalogs enriched with metadata display classification, permissions, and usage patterns. Governance teams can discern which assets contain sensitive data and verify who accessed them.
Data governance from theory to reality, when every asset carries its own audit trail.
Lineage metadata maps dependencies across the data lifecycle. Before changing a schema, engineers can see which dashboards, models, or pipelines will be affected by changes to the dataset.
That visibility prevents disruptions to downstream workflows and reduces the cost of maintenance and troubleshooting.
Metadata provides leaders with confidence in every metric. Lineage, ownership, and quality indicators trace results back to their source and confirm their validity.
Transparency reinforces accountability and strengthens trust in every data-driven decision.
Metadata and the data catalog give each other purpose: one organizes, the other informs.
A successful relationship, however, relies on how one captures, updates, and governs metadata.
How to Manage Metadata: Best Practices for Automation
Manual metadata management does not scale. Spreadsheets and static documentation work for a few datasets but quickly fail as data volumes and systems grow.
Modern data environments depend on automation to keep data discoverable, updated, and reliable across systems. This is in addition to reducing the cost of data management overall.
According to Gartner, enterprises without a metadata-driven approach to modernization “could end up spending as much as 40% more on data management.”
Automated metadata management connects to your primary data systems. It helps to capture schema changes, refresh schedules, ownership updates, and lineage paths. Yet, frequent synchronization is required to keep data catalogs accurate.
Process discipline matters as much as technology. Clear standards for classification, naming, and ownership create uniformity across systems. When each dataset follows the same conventions, discovery is faster and audits are straightforward.
AI now drives the next step in this evolution. Intelligent systems identify sensitive data, classify it by risk, and suggest the right policies to defend it.
For more about metadata tagging, policy, and design, see our Metadata Tagging Guide.
AI-Powered Metadata Management and Automation
AI now powers metadata systems that automatically discover, classify, and maintain context, promoting metadata from static documentation to a living signal network.
But automation is table stakes. Intelligence is where Sifflet leads.
Sifflet achieves intelligent metadata management through its AI Agent, Sentinel. It detects drift, tracks schema evolution, analyzes behavior, and identifies risk before issues surface.
Traditional systems document metadata. Sentinel acts on it.
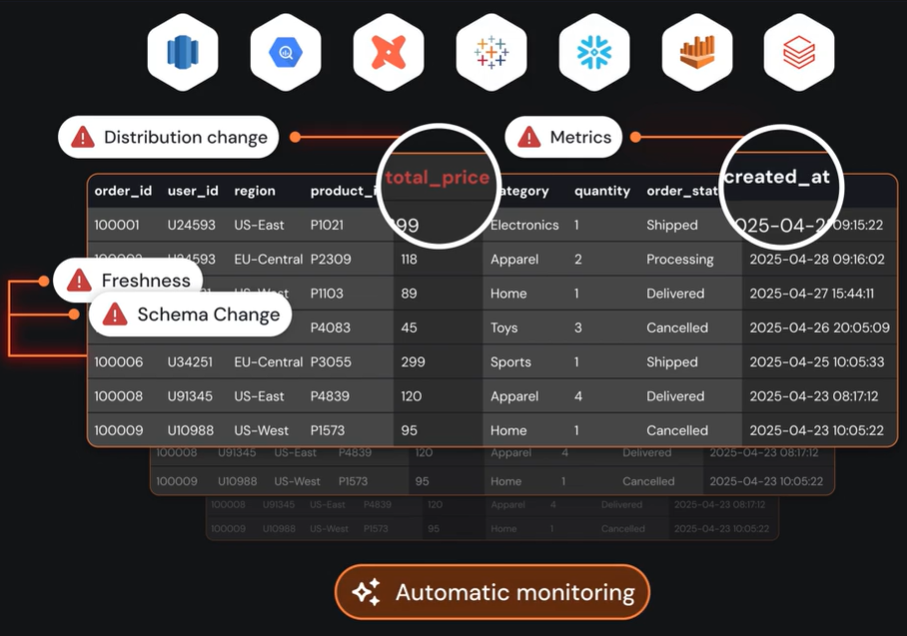
Sentinel: Sifflet's Metadata-Driven AI Agent
Sentinel turns metadata into observability. It sees what’s changing, what’s at risk, and what matters most before anyone feels the pain.
- Sentinel reads the signals.
Lineage shifts, schema edits, and query surges all tell a story. Sentinel connects them to reveal how data behaves and when it drifts off course.
- Calculates the stakes.
Every dataset carries a different weight. Sentinel weighs usage, dependencies, and business value to spotlight what needs attention first.
- Focuses the response.
No noise or guesswork. Sentinel tailors monitoring depth to each asset’s critical business impact and importance.
- Learns the rhythm.
With every incident resolved, Sentinel sharpens its sense of what “normal” looks like. It grows smarter, faster, and more precise over time.
Sentinel does more than observe. It understands, turning metadata into a living intelligence layer.
Sentinel strengthens confidence in critical assets and enables proactive governance while its data catalog keeps every asset discoverable, governable, and trusted.
Metadata: The Intelligence Behind Data
Data users demand clarity.
Metadata delivers that clarity. Sifflet's data catalog organizes it. Sentinel keeps it alive.
With Sifflet, that system learns and adapts on its own. Sentinel turns metadata into a source of awareness that scales with your business and safeguards every decision built on data.
Ready to see metadata in motion?
Discover how Sifflet transforms context into confidence across your entire data ecosystem.




%2520copy%2520(3).avif)












-p-500.png)
