




The Big Box warehouse was safe, managed, and secure.
It was also a cage.
When we needed flexibility or speed, that safety turned to bitter limitation.
So, we chose freedom. We traded closed for Open to paint a high-performance mosaic of Snowflake, Databricks, and Trino.
But in the rush to scale, the connective tissue vanished. We gained our independence, but we lost the thread of truth.
Life Outside the Box
In the old world, the central warehouse was judge, jury, and executioner. In our new one, work is split across specialists; each engine brilliant in its part, but blind to the rest.
It starts in the cloud, the settlement layer. Here, Snowflake and BigQuery provide a governed, structured environment for financial and operational reporting. They are the systems of record, built for precision.
But the sheer volume of today's data stores requires more than precision; it requires raw power. Compute engines like Spark and Trino are the heavy lifters, built to crush massive, unstructured datasets that traditional storage could never afford or handle.
Finally, there are the predictors. Specialized environments like Databricks and SageMaker take all that processed data and transform it into AI and ML models. They don't care about SQL tables; their focus is on feature sets and training loops.
The Cost of Freedom
On paper, this division of labor is a masterpiece of efficiency. We chose the Open Data Architecture because the benefits were too great to ignore. We acquired a scalpel for data science and a sledgehammer for petabyte processing. We now enjoy superior economics and zero vendor lock-in.
But there's a catch.
Metadata doesn't travel well. When data jumps from one engine to the next, the context doesn't follow. Lineage lingers at each engine's edge. Schema history stays trapped in local logs. Semantic context erodes in the gaps.
In a multi-engine mosaic, every handoff is a technical blind spot.
The Loss of Truth
In the Big Box era, metadata was native. Catalog, logs, and lineage lived under one roof. The system knew the origin of every column because it never left the building. Lineage was a single, coherent thread of truth.
In the multi‑engine era, that thread frays. Lineage becomes a collection of disconnected logs and catalogs scattered across silos. Each engine captures its own view of the world, but shares it in a language the others can’t understand.
Semantic Drift: One Metric, Three Truths
Without a translating layer, definitions inevitably clash. A Revenue calculation in a Databricks Python script might handle null values or currency conversions differently than a SQL model in dbt.
When logic fragments, it creates three versions of the truth: the model's, the Finance team's, and the raw data's. This is two versions too many. Eventually, users stop asking for clarity and abandon the dashboard.
Between engines and end users, trust is hard to build but easy to lose.
The Missing Layer of Truth
Fragmented architecture has led to fragmented monitoring. Snowflake tells you the queries are fast; Spark tells you the job has finished. But in a decoupled world, success in one engine can still mean failure in the next.
In a multi-engine data stack, job success is more of a vanity metric than a meaningful measure.
Consider this typical workflow for an executive dashboard:
- Raw logs are captured in S3
- Processed via Spark
- Stored in Iceberg
- Queried by Snowflake
A change, someone updating a Currency field from a string to an integer, doesn't trigger an alarm. Instead, the Spark job silently compensates, casting the incompatible data as NULL and reporting a successful run.
The Iceberg table now contains 20% null values, yet Snowflake reads the data perfectly, and the dashboard loads in seconds.
Every light is green. Every query succeeds. But the truth has gone dark in silence.
To find the light, you have to move beyond the individual logs of your warehouse or your lake. You need a layer that goes beyond monitoring the engines, but validates the journey they share.
Your Strategy for the Multi-Engine Data Stack
Building a high-trust architecture requires more than just new software; it requires a shift in strategy. While the multi-engine mosaic offers unparalleled freedom, it demands a new set of operational rules:
- Standardize open: Use formats like Iceberg not just for storage, but as a commitment to metadata transparency across the stack.
- Centralize the view: Avoid the Dashboard of Dashboards trap. Use a single source of truth for data health to keep everyone looking at the same lineage.
- Define ownership at the border: Explicitly define who owns data quality as it moves from the Data Lake (Spark/Databricks) to the Data Warehouse (Snowflake/BigQuery).
- Embed observability early: Don't bolt observability onto a finished pipeline. Build it in from day one, so trust is baked into the architecture, not added as a patch.
Sifflet Data Observability: The Metadata Control Plane
You can't fix a multi‑engine problem with a single‑engine tool.
Modern data stacks need a neutral control layer to reconnect the truth lost in handoffs, preferably one that lives above warehouses, lakes, and compute engines
That layer is Sifflet.
From Fragments to Flow
Where traditional tools see pieces, Sifflet sees a system. It ingests metadata from every engine (Snowflake, Spark, dbt, Iceberg) and weaves it into a continuous lineage graph. Transformations, schema changes, and quality metrics become part of the same living network.
Sifflet connects the dots that engines can't.
When Spark silently casts a field to NULL or a schema evolves upstream, Sifflet doesn't just see a successful job; it sees the broken promise. It flags the impact before it reaches the dashboard, allowing your team to prevent errors rather than perform forensics.
Monitoring the Meaning, Not Just the Mechanics
Most observability platforms stop at performance metrics: did the query run, did the job finish? Sifflet goes deeper. It monitors the data itself: distribution drift, schema evolution, volume anomalies. When job success no longer equals truth, Sifflet makes sure you know the difference.
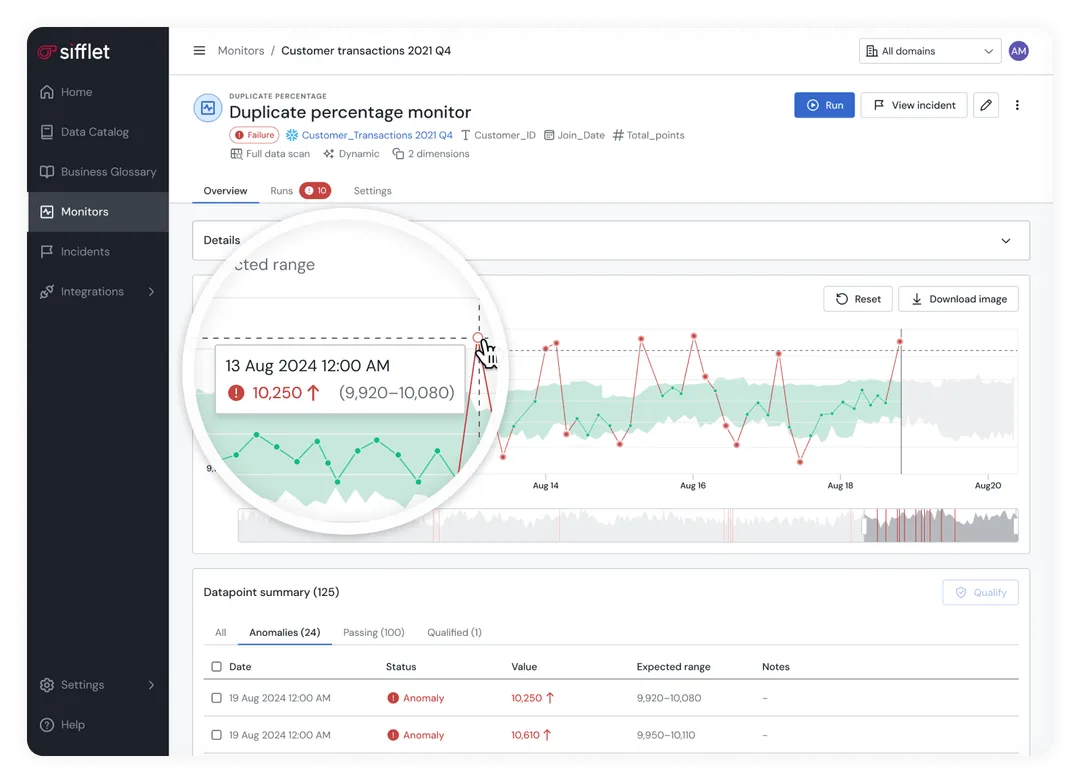
Sifflet restores what the Big Box once guaranteed: continuity, context, and confidence. By unifying metadata across the mosaic, we eliminate the blind spots created at the handoff. You keep the freedom of the Open architecture with the reliability of a managed one.
As a result, dashboards don't just load; they tell the truth.
The New Standard of Trust
The move away from the Big Box was never about governance; it was about growth. We chose the multi-engine mosaic because it was the only way to meet the scale and speed the times demanded. As such, we traded the safety of the cage for the power of the tools.
Sifflet Data Observability restores the certainty we lost when we decoupled the stack. It provides a single source of truth that spans warehouses, lakes, and compute engines, deleting all technical blind spots by unifying metadata that engines can't see on their own.
With Sifflet as the metadata control plane, freedom and truth are no longer at odds.
Don't let your truth linger at the edge of your engines. Book Sifflet demo today.















-p-500.png)
