




Convenience always comes with a higher price.
Centralized data warehouses offer the convenience of storage and compute all managed under one roof. But as data volumes explode and AI demands grow, that harmony has become a prison of excessive egress fees and rigid constraints.
Consequently, many enterprises are turning away from convenience and toward an Open Data Architecture to achieve cost savings and greater control.
What is Open Data Architecture?
Open Data Architecture is a vendor-agnostic, modular framework that utilizes open-source standards and interoperable tools to separate data storage from compute. It makes data portable, eliminates vendor lock-in, and allows companies to scale storage and processing independently.
The benefits of this open shift are threefold:
- Unrivaled flexibility: Use the right tool for the right job on the same dataset.
- Long-term cost control: Avoid proprietary formats that make moving data prohibitively expensive.
- Future-proofing: Infrastructure that is ready for the next wave of AI and LLM innovation.
Who Benefits From An Open Data Architecture?
When Netflix and Uber ran up against the limits of traditional data lakes, the seeds of open architecture were planted.
Netflix originally developed Apache Iceberg, the foundational open table format, to allow for atomic transactions and high-performance querying; features unavailable in proprietary warehouses and early data lakes.
Specifically, Netflix was trying to solve for silent data corruption, where queries returned partial or incorrect results while the system continued to report a successful execution state.
Similarly, Uber developed Apache Hudi to manage real-time updates and deletes for millions of concurrent trips, a feat traditional write-once data lakes couldn't support.
These pioneers proved that at a certain scale, proprietary systems become a bottleneck rather than a benefit. It was their journey that turned the promise of Open Data Architecture into an enterprise reality.
When to Move To An Open Data Architecture
While the pioneers solved for scale, more recent adoptees did so to free themselves from rigid confines and rising costs. The following situations are today’s primary drivers.
- When your data sources outgrow a single platform
Modern stacks are no longer just a single database. Companies now manage a massive influx of streaming data, SaaS logs, and unstructured files. They need a vendor-agnostic architecture to ingest and store this variety without creating dozens of new proprietary silos.
- When vendor lock-in becomes a business risk
Relying on a single vendor's black box is a risk few modern enterprises can afford. An open architecture provides a vendor-agnostic framework that puts you back in control of your data formats. This grants you the sovereignty to choose the best tools for today’s needs while retaining the flexibility to switch them tomorrow.
- When AI and real-time use cases can’t wait on propriety pipelines
AI and real-time analytics can’t afford to wait for a proprietary engine to process data. An open architecture gives models direct, low-latency access to the raw data source.
- When scale and cost demand decoupled storage and compute
Decoupling storage from compute serves two purposes. It eliminates vendor lock-in and allows data volumes to scale while paying only for the processing power actually used.
While any of the reasons are worthy of taking action, escaping the monolithic black box requires a meticulously assembled stack and the smooth interaction of six core open architectural layers.
The Components of an Open Data Architecture
Open Data Architectures are modular by design. Each layer connects with the others via open protocols. As a result, individual components can be replaced without disrupting any of the other layers or the foundation as a whole.
- Ingestion layer
Raw data is ingested directly into the lake using ETL/ELT and streaming, landing data in open formats like Parquet to keep assets pure and portable from the moment they're collected.
- Storage layer
Cost-effective cloud storage containers, along with open table formats such as Apache Iceberg, maintain database transactional integrity while keeping data in a vendor-neutral state.
- Transformation layer
Transformation engines clean and model data. This logic remains independent of the query engine, keeping business logic portable even if the compute engine changes.
- Analytics layer
Engines can access the same dataset simultaneously, reducing the need to move or copy data multiple times. Teams work from the same source of truth and avoid excessive processing costs.
- Governance
Data governance acts as a universal guardrail, defining security and compliance centrally, to maintain safety and compliance from source to storage to deletion.
- Metadata
Metadata serves as the connective tissue, tracking the location, schema, and history of data across all modular layers to prevent fragmentation.
Moving to an open architecture requires a shift in priorities, placing data ownership and interoperability at the center of the stack from day one.
How to Build an Open Data Architecture
You can't build a modular, open system without a clear set of rules. Before designing systems or buying new tools, define these non-negotiable guardrails that will govern your open source stack:
1. Define the Open Mandate
Set 'Open' as a procurement and governance requirement. Every new platform or tool must support open, widely adopted formats and standard APIs as a condition for its implementation.
Think of this as a Data Constitution founded on Open principles.
2. Choose Canonical Open Formats
Select a definitive set of open formats, such as Parquet for files and Apache Iceberg or Hudi for tables.
Standardization sustains interoperability and portability.
3. Formalize the Access Layer
Mandate that data be accessible via open protocols like Standard SQL and REST APIs.
Open connection protocols allow any software, from a simple spreadsheet to a high-end AI, to talk to data using its native language and without the need for expensive custom integrations.
4. Standardize Metadata Tagging
Universal tagging standards create a common language so that fields in your storage layer maintain the exact definition in BI tools and everywhere else.
Standardizing metadata prevents semantic drift that occurs when isolated systems apply conflicting logic to the same raw data.
5. Codify the Blueprint
Summarize these rules in a one-page diagram that illustrates where data lives, how people will find it, and which tools are allowed to access it.
Think of this as a building code for pipelines and dashboards to keep their construction aligned with and in support of the Open architecture philosophy.
The Challenge of the Open Shift: The Visibility Tax
In a classic storage system, the vendor holds control over system health across every layer, from storage all the way to the end-user dashboard.
In an Open Data Architecture, that centralized control plane disappears. Data, metadata, and logic are distributed across a collection of independent tools, and while this decoupling enables flexibility, it also introduces fragmentation. Without direct visibility and coordinated controls between modular layers, tracking, validating, and managing data becomes significantly more difficult.
In bundled compute-and-storage architectures, the vendor also provides the processing intelligence, albeit in a closed and inaccessible form.
When organizations move to an open architecture, they gain data sovereignty, but they give up that centralized processing brain in the process. This tradeoff introduces a new class of operational challenges that traditional architectures were designed to hide.
One of the most damaging issues is the lack of integration awareness across the stack.
In decoupled systems, tools are effectively blind to one another. A routine schema change at the ingestion layer, for example, may not trigger a failure in storage or transformation. Instead, it quietly propagates downstream.
Transformation models and dashboards continue to run on schedule, producing outputs based on mismatched data. The result is zeroes, nulls, or corrupted values reaching end users without any explicit errors being raised. These silent failures are particularly dangerous because they erode trust while remaining invisible to operators.
Even when teams adopt shared metadata standards, semantic consistency remains fragile.
Different tools may still interpret the same data in slightly different ways. As business logic is no longer confined to a single system, it becomes both portable and mutable.
Without a centralized view of logic and meaning, multiple versions of the truth can coexist within the same architecture, shifting conversations away from insight and toward disputes over whose numbers are correct rather than what they represent.
Trust is further strained by the constant handoffs between vendors that open architectures require.
Each transfer introduces an opportunity for data to be delayed, corrupted, or lost. In a walled-garden warehouse, these internal movements are managed by the vendor’s software, which can detect failures, roll back changes, or surface alerts.
In an open stack, those internal movements become external handoffs between entirely separate systems, for example, from an object store to a transformation service to a query engine. Without a built-in safety net, failures become harder to detect and even harder to diagnose.
Unfortunately, traditional monitoring tools offer limited relief in this environment, as they were designed for vertically integrated systems rather than fragmented, multi-vendor data stacks.
Why Traditional Monitoring Falls Short
Traditional monitoring was designed for a closed system, a predictable and contained environment. An open architecture is neither, which presents several challenges from a monitoring standpoint.
- The "cargo vs. container" problem
To start, traditional monitoring was built for IT operations, not data operations. It's fine for tracking infrastructure metrics: Is the server online? Is CPU usage under 80%? Is the disk full?
The problem with traditional monitoring in an open architecture is that systems can report a healthy status while delivering duplicated or corrupted data.
- Opt-in and static rules
Traditional monitoring relies on predefined thresholds and manual configuration per table or pipeline, which doesn't scale to dynamic, open environments with thousands of assets.
It can't automatically adapt to schema changes, new data sources, or varying business semantics without constant human intervention.
- Lack of horizontal lineage
Traditional monitoring is strictly vertical, focusing on the health of a single tool, such as a Snowflake monitor or an AWS CloudWatch alert. However, in an open architecture, data moves horizontally across a multi-vendor landscape. Data breaks usually occur in the "no-man's-land" between systems, during the hand-off from Fivetran to Iceberg or dbt to Tableau.
For similar reasons, cross-platform impact analysis is also unsupported. They can monitor a table change in your storage layer, but they can't predict which downstream BI dashboards or AI models that change will break ten minutes later.
Sifflet's Role In An Open Data Architecture
Sifflet is the metadata intelligence layer of the open data architecture. Sifflet's data observability brings horizontal oversight to a modular stack, turning a fragmented architecture into a synchronized, trusted system.
Sitting atop the modular layers, Sifflet restores centralized visibility and intelligence without the vendor lock-in.
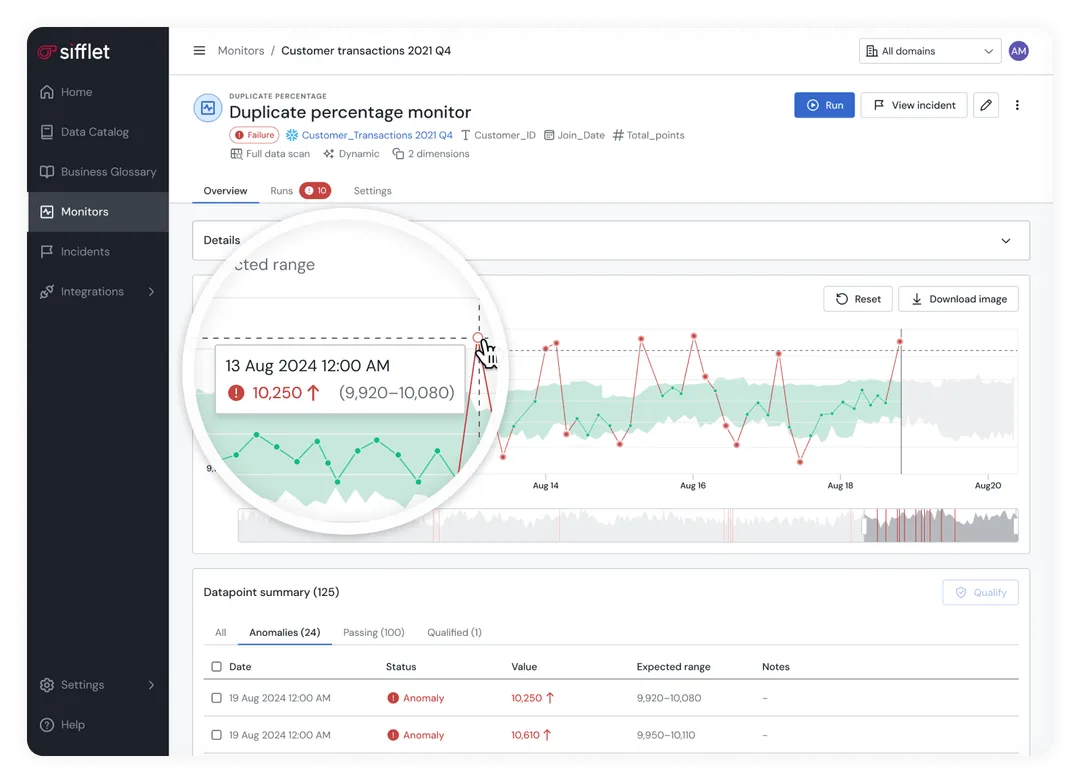
Automated Monitoring Across Pipelines
While infrastructure tools check whether the servers are up, Sifflet checks whether the data is correct. It monitors data quality across the entire pipeline, catching anomalies the moment they appear and before they reach the end user.
Cross-Tool Lineage and Impact Analysis
Sifflet tracks data across every hand-off. When a schema change occurs in the storage layer, Sifflet's field-level lineage tracks exactly which downstream dashboards will break. Data teams receive a complete accounting of an issue and its impact in Slack or Jira, and the right people receive notifications long before business users ever encounter a broken report.
Alerting for Freshness, Volume, and Schema Drift
Sifflet provides the shared brain necessary to close the coordination gap. It monitors for the three most common causes of data failure:
- Freshness: Ensuring data arrives on time and hasn't stalled between hand-offs.
- Volume: Detecting if a file is smaller or larger than usual, indicating a partial or faulty ingestion.
- Schema Drift: Catching changes in data structure at the source before they break downstream models.
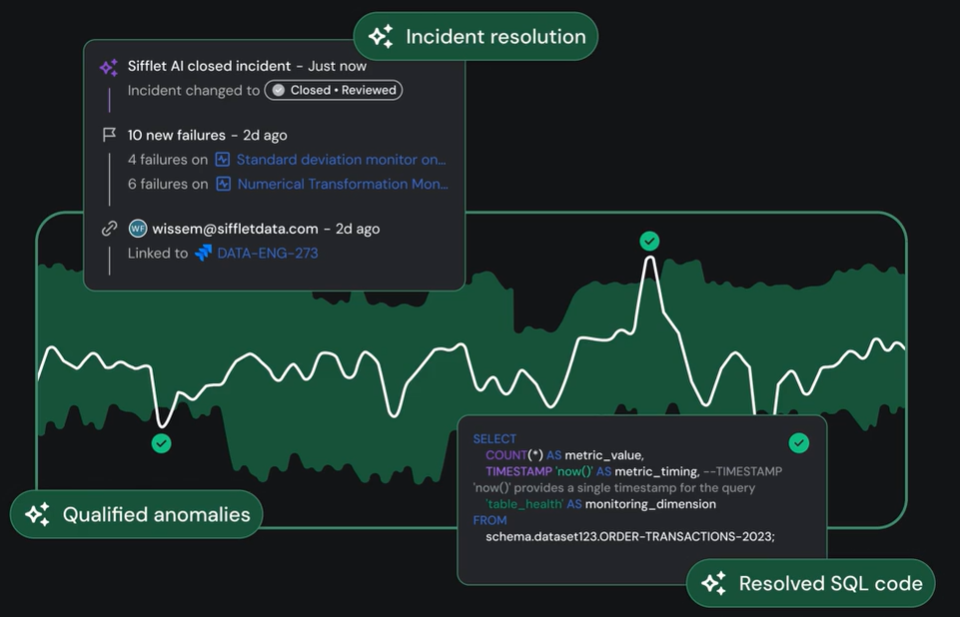
Collaboration and Incident Resolution
When errors occur, Sifflet deleted the detective work across multiple vendor logs by pinpointing the specific hand-off where the chain broke.
By linking technical failures to business outcomes, the platform shifts the conversation from which tool is at fault to how quickly business-critical data can be restored.
Sifflet Data Observability for Open Data Architectures
The goal of an Open Data Architecture is to make your data more portable, more scalable, and more useful for the next wave of AI innovation. Sifflet closes the coordination gap and preserves the trust that is often at risk in a decentralized system.
Sifflet provides the connective tissue that turns a collection of independent tools into a unified, high-performance architecture. It eliminates the silent data corruption that early pioneers like Netflix had to address with custom tools.
With horizontal lineage, content-aware monitoring, and business-aware root cause analysis, you can finally enjoy the benefits of an open stack with the unified visibility and confidence of a managed monolith.
Activate the intelligence layer of your open stack. Check out our Resource Hub for more information about Sifflet Data Observability.














-p-500.png)
