




If active metadata is the life of the party, passive metadata is the quiet and reliable designated driver.
It’s the calm, steady presence that holds the stack together while everything else races ahead.
Here’s everything you need to know about passive metadata, and why the quiet one is still in the driver’s seat.
What is Passive Metadata?
Passive metadata is the descriptive information that defines your data assets: their structure, ownership, and purpose. It's a snapshot of each dataset's schema and context at a single point in time.
This foundational layer helps data teams understand what data exists, how it's organized, and how assets connect across systems. It supports cataloging, governance, and discovery by supplying the consistent documentation that every data platform depends on.
Passive metadata includes:
- Table and column names
- Data types and formats
- Business definitions and glossary terms
- Ownership and creation details
- Structural relationships between datasets
Although it doesn't capture live usage or transformations, passive metadata serves as a reliable reference point for data management, governance, and lineage analysis.
Passive Metadata In Data Catalogs
Passive metadata is the structural backbone of every data catalog. It captures each asset's core technical attributes to organize data for search and discovery. This static layer serves as the reference map for data inventory and navigation in data-rich environments.
A data catalog gives users a clear view of their data landscape. Analysts can trace which datasets feed their dashboards. Engineers can check lineage before making changes. Governance teams can confirm ownership, sensitivity, and access rights without chasing down spreadsheets or emails.
The data catalog is a shared workspace where everyone can find, evaluate, and access the same information.
Passive vs. Active Metadata
Passive and active metadata describe two ways of managing information about data assets.
Passive metadata captures what your data is: its structure, definitions, and ownership.
Active metadata captures what your data does: how it moves, changes, and is used in real time.
Passive metadata serves as the fixed source of truth for your catalog and governance processes. It defines the data landscape and ensures everything is documented and searchable.
Active metadata builds on that base. It enriches what's documented with real-time context; updating lineage, monitoring quality, and surfacing impact as data flows through your systems.
For example:
- Passive Metadata: A "customer_data" table lists its columns — customer_id, name, email — and notes it was last updated in March 2025.
- Active Metadata: That same table updates automatically today when the schema changes, showing how it feeds into marketing dashboards, making the change available for review.
Together, they form a complete system of record and response: passive metadata establishes clarity and control, while active metadata adds motion, visibility, and automation.
How Passive Metadata Works
To better understand passive metadata, let's review how it's collected, updated, and used to connect data, people, and decisions.
Passive metadata is generated either from human input or automated extraction.
- Manual curation: Data stewards document assets, add business context, and link datasets to glossary terms.
- System ingestion: Catalog tools pull technical details such as schemas and column types directly from source systems.
Passive Metadata Maintenance
Passive metadata only remains accurate if it goes through appropriate maintenance.
Automated syncs pull updates from connected systems whenever schemas, tables, or owners change. These syncs add new assets to the catalog and remove retired ones, keeping the inventory current.
Manual maintenance closes the gap between what systems track and what people change.
Data stewards and domain owners review assets on a set schedule, often monthly or quarterly, to confirm ownership, update glossary terms, and make sure business definitions still match production logic.
When data models shift, those reviews extend downstream to include lineage and dashboard documentation.
Some common use cases include:
- Documenting key assets
Teams record schemas, column details, and ownership for critical datasets like customer_orders, creating a single point of reference for anyone using the data.
- Defining business metrics
Glossary entries for terms such as "MRR" standardize reporting across finance and analytics, so recurring revenue means the same thing everywhere it appears.
- Tracing data movement
Capturing lineage between tables, such as sales_metrics and their CRM source, makes it easier to understand dependencies and assess the impact of schema or pipeline changes.
- Supporting governance and compliance
Passive metadata strengthens metadata in analytics governance by providing consistent definitions, ownership, and lineage documentation across systems.
Passive metadata turns scattered information into a structured reference layer. It gives every member (analyst, engineer, or compliance officer) a single source of truth for understanding and trusting the data they use.
Why Passive Metadata Matters in Sifflet
Metadata's role is expanding well beyond documentation.
As Dataversity notes, it's becoming the interface between IT and AI, the connective layer that gives systems context and meaning.
Sifflet's metadata management approach starts with passive metadata as the structural foundation of its catalog, lineage, and observability systems. It drives search, discovery, and relationships across the entire platform, from the data catalog to lineage to governance.
At the center of that layer is Sifflet's data catalog. It ingests passive metadata to link assets across warehouses, pipelines, and BI tools, creating a complete, searchable map of the data environment.
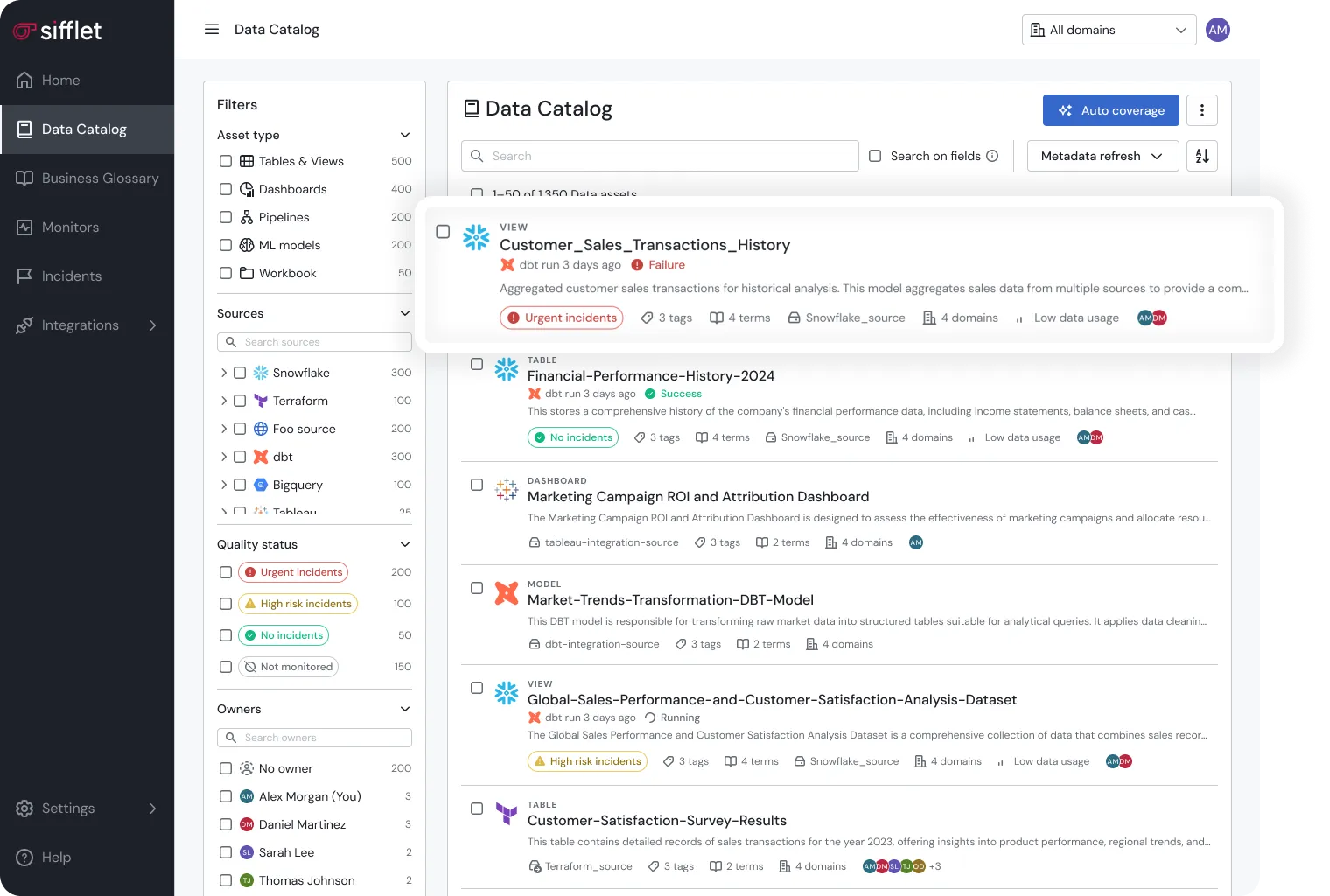
That same foundation powers Sifflet's three AI agents — Sentinel, Sage, and Forge — which use passive and active metadata to detect anomalies, trace causes, and automate fixes. Together, they turn metadata into intelligence.
Sifflet's data catalog consolidates passive metadata from warehouses, transformation frameworks, and BI systems into one workspace. Every dataset, table, and dashboard becomes discoverable and traceable through its metadata profile.
Sentinel uses this cataloged metadata to understand data structures and ownership when monitoring quality and detecting anomalies. Forge relies on it to automate onboarding and configuration as new assets appear.
Each asset page in Sifflet draws from passive metadata to present key context such as owner, schema, domain, and glossary links, alongside live signals like freshness, usage, and quality.
Sage uses these relationships and definitions to interpret business meaning and trace root causes when issues arise. It connects technical changes to their downstream impact.
By capturing schemas and dependencies, Sifflet builds end-to-end lineage views that show how data moves through pipelines, models, and dashboards. This makes it easier to diagnose issues and understand their impact before changes go live.
Sentinel and Sage both use lineage metadata to trace incidents upstream, while Forge automatically updates lineage as new connections form.
Passive metadata does the heavy lifting behind all of this. It gives Sentinel, Sage, and Forge the structure and context to operate accurately, intelligently, and at scale.
How to Manage Passive Metadata in Sifflet
To get the most from passive metadata in Sifflet, follow these best practices:
1. Connect your data sources
Integrate Sifflet with your primary data systems, data warehouses, transformation frameworks, and BI tools.
Native connectors streamline setup, and most integrations take less than thirty minutes per source.
2. Standardize your tags
Establish a clear metadata tagging policy. Every asset should include tags for ownership, sensitivity (such as PII), data domain, and quality level. Keep the rules simple and visible through a shared reference guide.
3. Build and a business glossary
Define critical metrics and terms in Sifflet's glossary. Link each term directly to datasets and dashboards so business and technical users share a single vocabulary.
4. Automate metadata ingestion and clissification
Use Sifflet's automation to capture descriptions at the asset and field levels, detect and classify PII, and suggest relevant tags. Review the results regularly to keep classifications accurate and meaningful.
5. Enrich and and curate metadata manually
Automation speeds up your setup, but context still matters.
Ask data stewards and domain experts to refine descriptions, clarify ownership, and link business meaning to technical detail.
Get the basics right, and the rest of your stack falls into place.
Passive Metadata: Driving Intelligent Data
Passive metadata is still the data that makes data discoverable anywhere and by anyone.
It maps the origins, owners, and organization of each dataset for compliance and risk management.
It keeps cataloging and asset views clean and consistent so people can find, understand, and trust the data they're working with.
And it powers automated monitoring and adaptive governance by giving Sifflet’s Sentinel, Sage, and Forge the structure they need to understand data behavior and surface the signals that matter.
Ready to turn your metadata into confidence and clarity?
Discover Sifflet data observability. Book a demo or explore the Resources Hub to learn more about metadata in motion.















-p-500.png)
