




Many companies have a simplified metadata management system.
It's called Slack.
It's where analysts go to ask what "revenue_actual" or "customer_id" ****means.
Then everyone argues about which answer is right.
Enjoy your next incident review.
If this sounds like your approach, you're doing metadata management the hard way.
What is Metadata Management?
Metadata management is the process of collecting, organizing, and maintaining the information that describes your data. It sets the rules and systems that keep that information accurate and easy to find.
Metadata is the contextual layer that gives meaning to your raw data. It records how data is structured, where it originates, how it changes, and how it's used.
Metadata shows how data works from every angle: its structure, meaning, performance, and use. It's the connective tissue that turns fields and tables into data people can actually find, understand, and trust.
Why Metadata Management Matters
An analyst builds a report on data she assumes is current. It isn't.
Sensitive customer data is shared in a report because it's not accurately tagged as restricted.
Revenue totals differ across executive dashboards, and no one agrees which is correct.
These aren't anomalies. They're symptoms of the same problem: the lack of a functional metadata management system.
With strong metadata management, quality control moves upstream. Pipelines know which fields matter, dashboards automatically display freshness, and anomalies are caught before they affect decision-making.
When it doesn't, quality control falls to end users, who end up validating reports, reconciling numbers by hand, and doubting both the inputs and outputs.
It's a recipe for inefficiency and mistrust that slows decisions, inflates costs, and erodes confidence in the data itself.
Sound metadata management practices restore and preserve trust:
- Defined standards catch quality issues early
- Clear lineage shortens incident recovery
- Trusted data speeds decisions
- Enforceable governance turns audits into routine checks
But metadata management goes beyond quality alone. It's also the foundation for governance, integration, lineage, and discovery; the systems that make trust scalable.
Metadata Management in Action
Consider two worlds inside the same retail company.
In the first, an analyst looking for customer purchase patterns finds three tables with unclear definitions.
"Repeat customer" might mean someone who's bought twice or someone active in the last year. After two weeks of back-and-forth, she builds a dataset she doesn't fully trust.
In the second, metadata is managed properly. The analyst searches the catalog, finds the customer dataset, and sees a clear definition for "repeat customer."
Ownership, update timestamps, and dependencies are all visible. She builds her analysis in minutes, not weeks.
The cost of ineffective metadata management shows up everywhere.
- How does it impact governance and integration?
Metadata management underpins every major data discipline.
Data governance depends on it. Policies, classifications, and access controls are all defined in metadata. Without clear ownership and definitions, governance breaks down.
At the same time, data integration uses metadata to connect systems. It maps fields, aligns transformations, and keeps pipelines consistent as data moves through them.
Metadata-driven integration eliminates manual mapping and reduces errors.
- How does it impact data lineage and quality?
Data lineage starts with metadata. Relationships in technical metadata create the map for lineage, tracing metrics from dashboards back to their source systems.
When something breaks downstream, that trace shows where and leads to why.
Data quality lives in metadata, too. Rules, thresholds, and quality indicators define standards and track compliance.
Together, lineage and quality turn complexity into clarity.
How to Manage Metadata
Metadata can live in spreadsheets or within an automated platform, but disciplined management determines whether it remains accurate and usable.
Sound metadata management leverages three components**: governance, structure, and process.**
Governance: Roles, Standards, and Stewardship
Governance defines ownership, standards, and how metadata is maintained.
Assign ownership first. Form a governance council with IT, engineering, analytics, and business leads. They define documentation standards, asset classification, and what's required.
Keep rules short enough for people to understand. A one-page guide beats a fifty-page manual no one will read.
Focus standards on three essentials: data that requires protection (PII or financial information), data quality levels and acceptable thresholds, and metadata tags.
In automated systems, engineering embeds these standards in code so they're enforced across pipelines. In manual setups, use checklists and peer reviews to confirm consistent application.
Appoint data stewards to keep those standards current as assets and definitions evolve.
Structure: Your Metadata Building Blocks
Metadata works from every angle: structure, meaning, performance, and use. Managing it means handling each type with intention and keeping them connected.
Technical metadata is the foundation of your data stack.
In smaller setups, schemas and transformations live in spreadsheets or wikis. Although time-consuming, these methods can be enough to keep small, stable stores of technical metadata.
Automated platforms collect this metadata as systems run. Warehouses, lakes, and transformation tools capture schemas, field definitions, and lineage automatically. A connected catalog processes these records on schedule to keep the view up to date.
Business metadata defines metrics, rules, and ownership.
For most, those definitions first appear in documentation or shared folders. Record and share them in a central space, like Confluence or shared spreadsheets, to keep interpretations consistent.
Metadata platforms store this context within the same environment as the data itself.
Glossaries and automated lineage keep business context tied to the data wherever it's used. When new datasets arrive or schemas change, governance workflows prompt stewards to review and validate definitions.
Operational metadata tracks how data systems perform: load times, job duration, and error rates.
Without automation, monitor key indicators through system logs or cron reports and review them regularly.
Metadata platforms unify these signals across pipelines and tools, turning them into metrics and alerts on data health. Linked to governance workflows, they help enforce SLAs, quality thresholds, and audit readiness.
Usage metadata tracks how data is used across the business: which datasets are queried most often, which reports depend on them, and who uses them.
Most programs start by tracking this manually, exporting usage logs from BI tools, or noting high-traffic tables in documentation.
Orchestrated systems pull these signals straight from warehouses, BI tools, and query engines to create a clear view of how data is used and what drives value.
Governance and observability layers use that visibility to focus attention where it matters. They protect critical datasets, consolidate duplicates, and strengthen reliability where it counts.
Process: Collect, Curate, & Apply
Once metadata is flowing, the real work begins: turning it into a living system to keep information accurate, connected, and usable across every workflow.
Step 1. Collect
Bring all metadata into one place.
Scan warehouses, lakes, pipelines, and BI tools.
Extract schemas, lineage, ownership, freshness, and usage patterns. Import legacy records from spreadsheets if needed.
The goal is complete visibility: knowing what data exists, where it lives, and how it connects. Automate it through APIs or connectors wherever possible.
Step 2. Curate
Refine and enrich what you've gathered.
Add glossary definitions and link them to technical assets.
Verify accuracy, fill gaps, and flag the datasets that matter most. Assign trust scores based on reliability and freshness to make quality measurable.
Step 3. Apply
Put metadata to work.
Publish it in catalogs so analysts can search and understand assets.
Enforce governance by linking policies to measurable standards. Use lineage to trace dependencies and surface business impact. Surface freshness and quality directly in dashboards, so anomalies appear early.
Governance, structure, and process take metadata management from concept to practice.
Best Practices in Metadata Management
Apply these principles to build a metadata management program that works in practice, not just on paper.
Start by establishing ownership early, assigning responsibility for each domain, dataset, and decision.
Clear ownership keeps metadata accurate and makes accountability visible. Keep your standards simple by creating short reference guides rather than lengthy manuals, simple standards get used, while complex ones are often ignored.
Automate wherever possible so systems can capture schemas, track freshness, and map lineage without relying on manual updates. This keeps metadata current as data changes.
Build governance directly into daily workflows by tying policies to real processes such as approvals, quality checks, and pipeline releases. When governance is part of the workflow, compliance becomes automatic.
Finally, keep metadata visible within the tools people already use, since visibility builds trust and encourages adoption.
Treat metadata as a living system that evolves alongside your data landscape, review it regularly, refine it when needed, and expand it as your organization grows.
The Role of the Data Catalog in Metadata Management
A data catalog is the operational core of metadata management.
It brings every type of metadata (technical, business, operational, and usage) into one environment where information stays connected, current, and searchable.
In its simplest form, a catalog is an inventory: a place to see what data exists and where it lives. But in practice, it's far more.
A modern data catalog functions as the workspace where data meaning, movement, and quality converge.
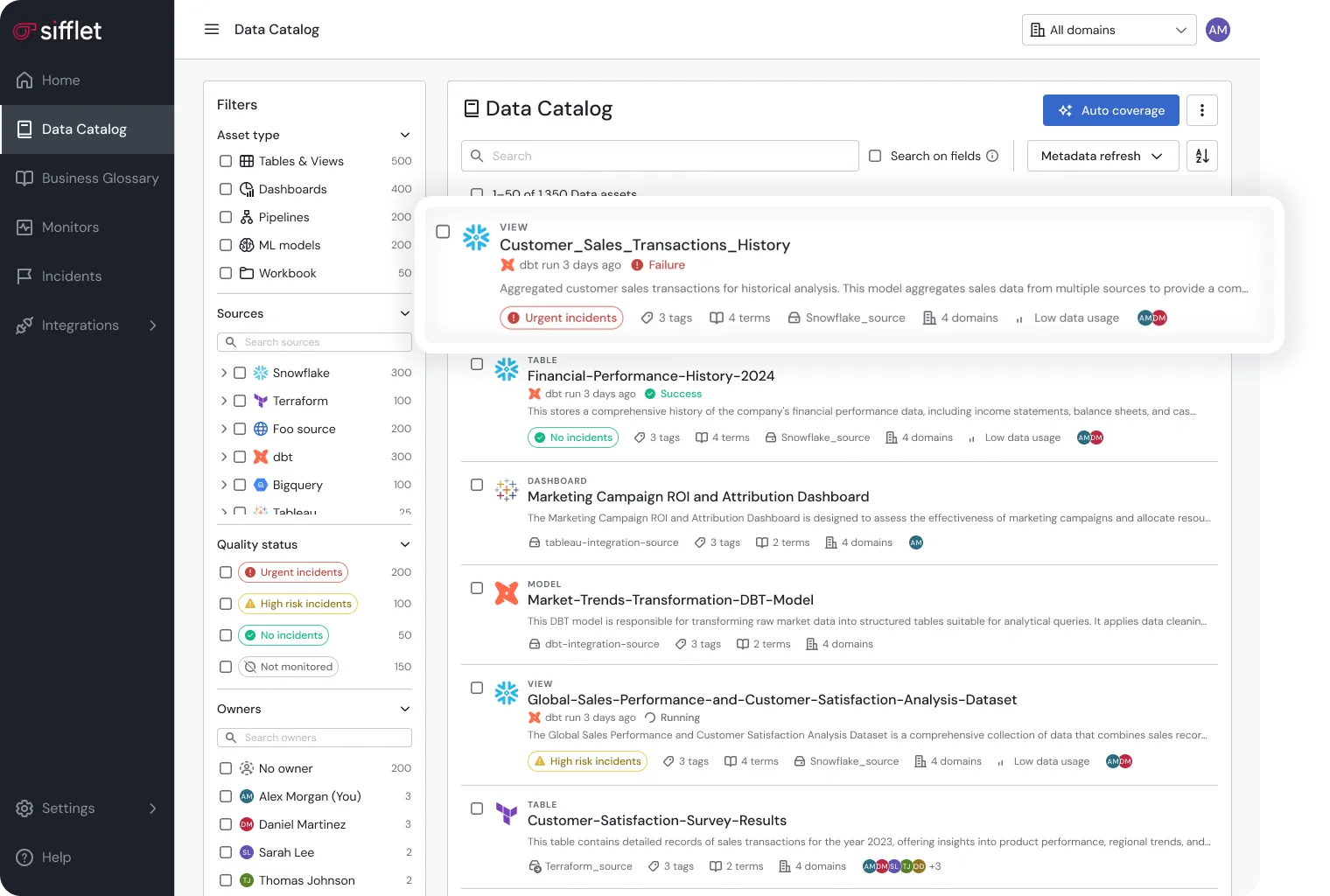
The catalog also serves as the connection point for everything else in your data ecosystem.
- Governance platforms use it to validate compliance.
- Observability systems feed it live quality metrics.
- BI tools pull from it to show lineage and ownership directly in reports.
In short, the data catalog turns metadata management into an operational process; one that evolves in real time with the data itself.
That's where metadata management becomes real.
And it's precisely where Sifflet begins, keeping that system active, accurate, and intelligent at scale.
Sifflet: Metadata Management in Motion
The problems outlined earlier (mismatched data, broken dashboards, regulatory exposure) stem from one root cause: metadata that’s scattered, outdated, or invisible.
Sifflet solves this by making metadata the operational core of your data infrastructure.
Sifflet’s data catalog unifies technical metadata, business definitions, operational performance, and usage patterns in a single live workspace. It’s where datasets, definitions, lineage paths, and quality metrics converge, all updated automatically as systems evolve.
But the catalog isn't just an inventory.
It's a quality control system. Every dataset carries quality context: freshness signals, schema history, data lineage, and trust scores. This context flows everywhere people work with data, from BI tools and dashboards to governance workflows. Quality becomes visible at the point of use.
The catalog anchors everything else in your data stack.
Governance systems validate compliance through it. Quality monitors feed it live metrics. BI tools draw from it to display lineage and ownership directly in reports. It’s the layer that keeps metadata accurate, connected, and accessible wherever people work with data.
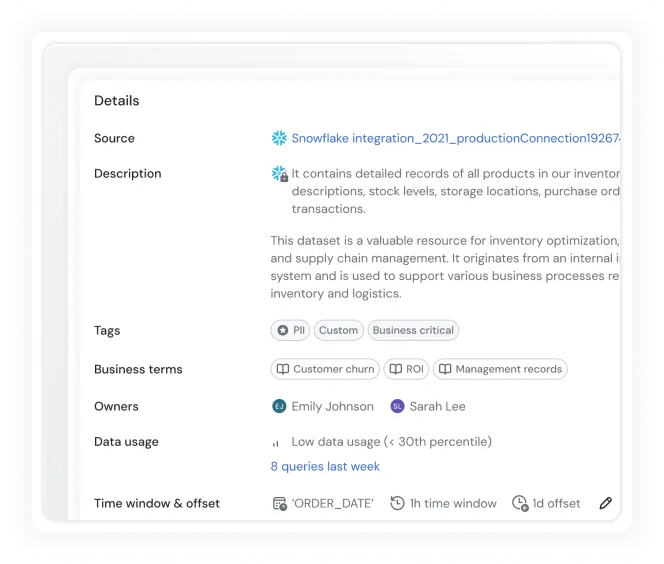
Sifflet collects and maintains metadata across warehouses, lakes, and pipelines. It links technical lineage to business meaning and operational performance, creating a live picture of how data moves and how people use it.
Sentinel, one of Sifflet’s three AI agents, monitors data pipelines in real time for schema changes and other anomalies.
When issues occur, Sentinel automatically updates metadata and points to their impact in the business context, keeping governance workflows, quality dashboards, and BI reports in sync without manual intervention.
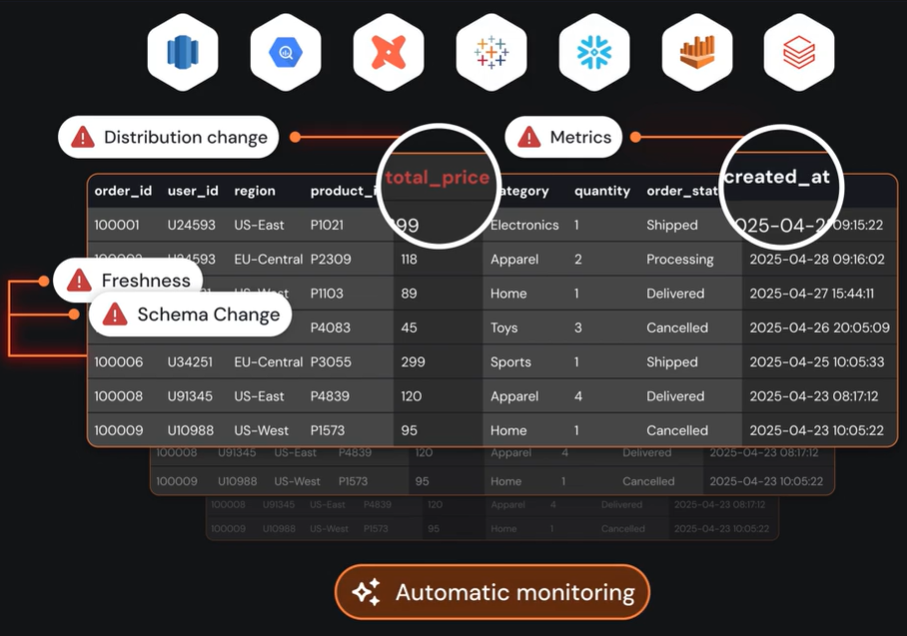
With metadata management and Sifflet in place, the previous scenarios don’t occur:
The analyst searching for “repeat customer” finds a clear definition in the catalog, with ownership and freshness metadata visible. She builds her analysis in minutes, not weeks.
Sensitive customer data is no longer shared accidentally in reports. The catalog flags restricted data with clear classifications and access policies. Analysts and business users can see which fields contain PII before adding them to dashboards or exports.
And regulatory audits no longer expose gaps in lineage. Every dataset shows its origin, transformations, and operational state.
Smarter Metadata Management Starts Here
You don't need another Slack thread to find the right dataset or definition.
With proper metadata management, the right answer is already waiting.
The time for metadata management is now.
Sifflet turns metadata into intelligence that drives governance, strengthens quality, and builds trust at scale.
Experience how Sifflet makes metadata the engine of trusted, governed data. Book a demo to see it in action.
















-p-500.png)
