



.png)
If you’re evaluating Bigeye for data observability, start here.
We’ll explore how the platform works, who gets the most value from it, and where more flexible, business-ready options like Sifflet may serve you better.
What Is Bigeye?
Bigeye positions itself as: "Powerful lineage-enabled data observability for complex enterprise environments."
It's a compelling pitch, especially for technical teams that value visibility and control.
The platform tracks the core signals engineers rely on: freshness, volume, schema, and distribution. It flags anomalies using thresholds that evolve alongside the data itself.
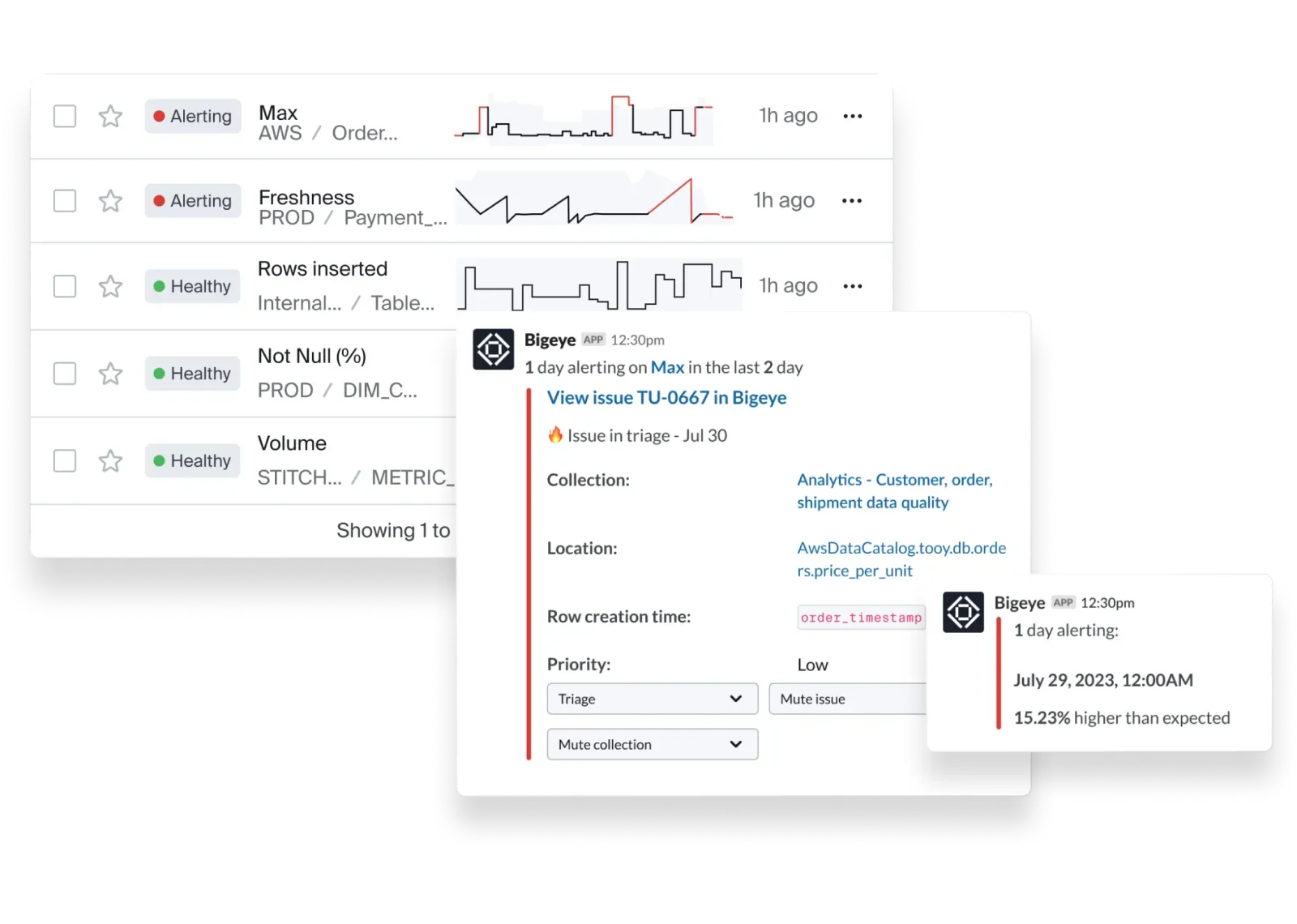
That proactive stance is baked into how the platform works. Bigeye continuously scans for change, flags problems early, and, in supported systems, maps upstream dependencies to show where those issues start and how far they spread.
It's also a highly configurable platform.
You can write custom SQL checks, monitor virtual tables, and set up auto-deployment of data monitors driven by metadata patterns, table tags, or reusable YAML templates. Every part of Bigeye is built for customized control.
That makes Bigeye most effective in highly structured environments. We're talking Snowflake, Terraform, and Git-based deployments where pipelines are stable and workflows are already code-first.
But all of this precision comes at a cost. Bigeye only works when you work like Bigeye. It assumes deep engineering maturity: version-controlled workflows, strong CI/CD habits, and a highly technical team ready and available to own configuration.
Bigeye doesn't hide its complexity. It wears it like a badge of honor.
Who Is Bigeye For?
Bigeye is for technical teams that want to monitor data quality the same way they monitor infrastructure: rigorously, programmatically, and decidedly hands-on.
It can be used by data engineers, data governance teams, data architects, leaders, analysts, and executives.
It works best in environments where pipelines are already codified and SLAs aren't optional.
Bigeye delivers the most value when:
- Your team writes its own SQL checks and deploys via Git or Terraform
- You manage complex DAGs or model inputs in Snowflake
- You operate under data contracts that require continuous enforcement
- You configure observability through code; declarative, repeatable, and version-controlled
This is a tool for engineering-forward teams. For them, Bigeye offers precision, automation, and control where it matters most.
But that same precision can be limiting elsewhere.
If you're looking for:
- No-code rule creation
- Visual rule builders
- Business-user dashboards
- Simple, cross-functional workflows
…Bigeye may be, well, too big.
Reviews consistently mention friction with the UI, over-reliance on SQL, and alerting that takes time to tune.
That means enterprises without the DevOps maturity or the bandwidth to own configuration will end up chasing observability instead of benefiting from it.
Bigeye’s best features
Let's break down the platform's core features and where they shine or strain.
Data Monitoring
Bigeye monitors the core dimensions of data health: freshness, volume, schema changes, and distribution shifts. Checks can be configured manually or auto-generated using autometrics, which recommend coverage based on usage patterns and downstream dependencies.
Custom metrics and autometrics are supported through SQL and virtual tables. For teams that prefer to work declaratively, all configurations can be managed in code using Bigconfig.
The result is broad, configurable coverage, if you're set up to manage it.
Bigeye gives you the knobs and levers, but it won't guide your hand. That makes it powerful for engineers, but more complex to operationalize for teams without the technical depth or time to drive it.
Anomaly Detection
Anomaly detection is one of Bigeye's most developed features.
It uses a multi-stage ML pipeline to learn baselines, flag deviations, and adjust thresholds as data patterns shift. Interestingly, users can rate these alerts to reinforce their accuracy and reduce false positives over time.
In theory, Bigeye's anomaly detection engine gets smarter the more you use it.
In practice, however, it depends on how quickly and accurately your team can provide feedback.
The engine works, but it requires training. It becomes a reliable signal layer for those willing and able to invest in that loop. For everyone else, it's just more work and a longer runway to value.
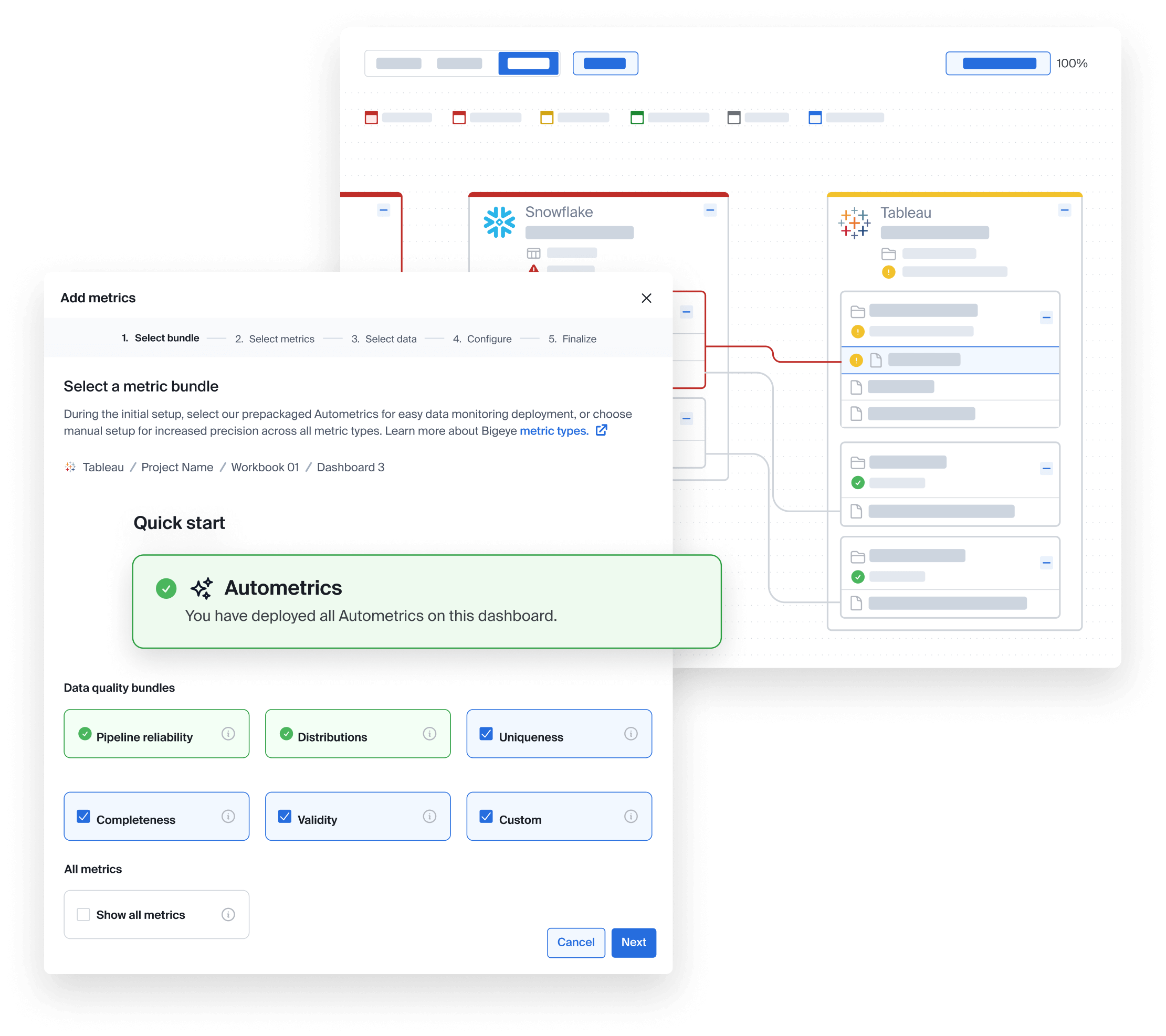
bigAI
BigAI is Bigeye's automation layer. It scans your data warehouse, evaluates how tables are used, and recommends monitors based on risk and downstream dependencies.
The goal: faster coverage with less manual effort, especially during onboarding or at scale.
This feature is a time-saver, not a set-it-and-forget-it system.
bigAI lowers the setup burden, but users still have to validate what will be monitored and fine-tune the thresholds. It's automation that's not entirely automatic.

AI Trust Platform
Bigeye has started positioning itself for AI observability with its AI Trust Platform.
The promise: monitor model inputs and enforce data quality policies before unreliable inputs reach production models. Lineage-aware impact analysis is also part of the pitch.
On paper, it's a smart evolution.
But user feedback suggests that confidence in this late addition AI-feature is limited, with scant evidence of adoption in the wild. It's a compelling direction, but for now, it's more ambition than advantage.
The Metric Store
Bigeye includes a centralized metric store that helps engineering teams track data quality KPIs tied to SLAs. You can define custom metrics, monitor performance over time, and trigger alerts when thresholds are breached, all with historical baselines built in.
But this is a tool for engineers, not business stakeholders. It's configured entirely in code and optimized for operational signals, not executive dashboards. That means metrics stay buried in pipelines and unavailable for cross-functional visibility or strategic decision-making.
Bigeye's feature set reflects its philosophy: give engineers the tools to build precision into every layer of data quality. But that power depends on how well you can wield it.
Nowhere is that more evident than in Bigconfig, its monitoring-as-code framework.
Bigconfig: Monitoring as Code
Bigconfig is Bigeye's configuration-as-code layer. It allows teams to define custom monitoring logic (rules, thresholds, schedules, metadata) using YAML or JSON, and deploy those definitions via Git. That makes observability version-controlled, auditable, and reproducible across environments.
For DevOps-driven teams, this is a clear strength. Bigconfig fits cleanly into CI/CD workflows and mirrors how infrastructure is managed elsewhere in the stack. Changes can be rolled out through pull requests, managed state, and reviewed diffs like any other config file.
The payoff is real: version history, rollback safety, and tight alignment between staging and production. Observability becomes part of the software development lifecycle, not something bolted on after.
But with all that power comes a steep learning curve. Bigconfig can overwhelm less technical users. It assumes infrastructure-as-code maturity and teams with the bandwidth to maintain it. Without that foundation, the lift is overly heavy.
As with much of Bigeye, the value is absolutely there if you're able to extract it.
Let's look at what actual users report after deploying Bigeye in their enterprise.
What Real Bigeye Users Say
⭐⭐⭐⭐ G2 4.1/5 | Gartner 4.4/5
Bigeye earns high marks from engineering teams that share its philosophy.
Users consistently praise its real-time anomaly detection, flexible rule logic, and proactive alerting. Once tuned, the platform is seen as fast, reliable, and well-suited for monitoring mission-critical pipelines, especially in Snowflake-heavy environments.
For technical teams, Bigeye's value is clear. It integrates cleanly with Git-based workflows, supports metric versioning, and gives engineers complete control over what gets monitored and how.
Bigeye's support team also draws praise for being hands-on and responsive, especially when helping users fine-tune complex setups.
But reviews also highlight recurring friction, particularly around integrations, alert management, and time-to-value. The learning curve can be steep.
Several users note that the platform assumes a mature setup and an engineering team ready to engage deeply.
"It's powerful once it's set up, but the setup took longer than expected. And we had to do a lot of tuning to make alerts useful. It's not something you just switch on."
Head of Data, Series C SaaS Company
There's little doubt Bigeye can deliver on its mountain of promises. The question is whether your team is ready to make the climb.
Is Bigeye the Right Fit for You?
Bigeye delivers best when your team shares its mindset. If you operate with infrastructure-as-code, push observability through Git, and manage SLAs as part of your data pipeline, the platform fits right in. You'll get control, visibility, and a tool that can be shaped to your exact needs.
That alignment matters. Because when Bigeye works, it works well. It reduces manual QA, flags issues before they reach business users, and avoids pipeline failures. Engineering-heavy teams with time to configure and tune will find it a valuable layer in their stack.
But Bigeye doesn't adapt easily. It expects you to adapt to it. Teams that lack dedicated data engineering resources or need cross-functional access, faster onboarding, or policy-based guardrails may spend more time tuning than trusting.
Ask yourself:
- Do we deploy infrastructure as code?
- Can we manage observability through Git?
- Are our pipelines mature enough to support config-first tools?
In the end, Bigeye is a precise tool with clear strengths. However, accessing that strength requires Big-time code, configuration, and commitment.
Where Sifflet Stands Apart
Bigeye is built for engineers.
Sifflet is designed with your entire enterprise in mind.
That means observability for everyone who depends on data: analysts, operators, compliance teams, and yes, engineers too.
With no-code configuration, built-in policies, and role-based workflows, Sifflet lets each team own their part of the trust equation without writing a single line of YAML.
With Sifflet:
- Lineage is field-level, real-time, and always on.
- Alerts arrive with context: what failed, how far it spread, and who's affected.
- AI agents do the root cause analysis for you. No detective work required.
- Trust scores and policies make quality visible and enforceable across domains and departments.
Sifflet isn't another workflow to learn, master, and manage. It fits into the ones you already use.
The table below compares how Bigeye and Sifflet approach observability across these key dimensions:
Sifflet makes trust operational across every system, every stakeholder, and every decision.
Bigeye gives you plenty of knobs to turn. Sifflet delivers observability you can trust.















-p-500.png)
