




In traditional data warehouses, moving data made it instantly available.
Clean logs in Airflow or a successful Fivetran sync meant your business had its answers.
But Open Table Formats like Iceberg and Delta Lake have changed everything.
Data Movement = tools shipping files to storage (S3, GCS, etc.).
Data Availability = users actually seeing/querying that data in dashboards.
In OTFs, these are now distinct operations. Files land first, but remain invisible until a separate metadata commit publishes them to the table. But either step can fail independently.
Result: Perfect pipeline runs. Flawless logs. Empty dashboards.
The Metadata Gap
Traditional tools monitor the plumbing: servers, memory, and logs.
But in Iceberg-centric architectures, the plumbing is rarely the problem. The failure happens at the handshake, the moment the system is supposed to acknowledge new data.
To understand why, think of an Iceberg table not as a folder of files, but as a constantly updating master list. It's the authoritative record that tells the system which files are real and which to ignore.
This is metadata.
If a system fails to update the metadata, the new data never officially exists. Terabytes of data can be successfully stored, yet your users see nothing. The data is physically present, intact, and complete, but because the metadata hasn't been updated, it's functionally invisible.
The Integrated Blind Spot
The proposed merger of Fivetran and dbt Labs signals a broader move toward more integrated data platforms in OTF environments. In these models, ingestion and transformation appear as a single, managed workflow.
But for all the appeal of a single pane of glass, no application-level merger can solve a fundamental technical reality: Integrated workflows don't equate to observable storage.
Even though these tools share tracking information, they're essentially management layers. They're reporting on the instructions they gave, ' sync this data' or 'run this model', but they aren’t validating that storage + catalog + engine are aligned.
This is a transparency crisis. When your tools report success but your dashboards are empty, you lose the most expensive asset in your stack: Data Trust.
Why Integrated Data is Not Observable Data
In OTF stacks, integrated platforms only see their own efforts. They report on the tasks they controlled, but they don't see the metadata. Without a neutral auditor to compare what the tools intended to do with what the storage actually contains, two dangerous blind spots remain.
The Ingestion Blind Spot
An ingestion tool only knows that the files were delivered to your storage. It has no way to verify if those files were actually recorded.
If that update fails, the data is just ghost inventory. It exists in your storage but is invisible to all dashboards and query engines across the company. The pipeline reports success, but for the business, nothing has changed.
The Transformation Blind Spot
The second blind spot is in the transformation layer. A tool can confirm that its code ran successfully, but it can't see the "mess" that code might have left behind.
A single successful transformation can accidentally create massive complexity, technical debt in the form of fragmented files or bloated records. It might not crash the system immediately, but it can seriously degrade its performance. Yet, because the tool only cares that the job finished, it won't recognize this performance decay as a failure.
Closing these gaps requires moving beyond monitoring "what ran" to validating "what exists." As integrated stacks begin to automate complex tasks such as schema changes and table optimization, the risk profile shifts.
The Governance Gap
The dbt/Fivetran merger promises a more automated, managed approach to handling data changes as they flow from source to warehouse. But in an environment where multiple tools must share the same data, this automation introduces a structural risk.
Think of it as an automated upgrade. If the system changes your data format to improve efficiency, it will report success, indicating the upgrade succeeded.
Yet, it has no way of knowing whether your downstream reporting tools are still compatible with that new format.
The integrated system won't alert you, either; it only monitors its own internal logic.
The Silent Failures Legacy Monitoring Misses
Traditional monitoring tools and integrated vendor logs look for crashes, but in
Open Table Formats, the most damaging failures are the silent ones.
1. The Atomic Commit Conflict
When two tools try to update the same table at the same time, a 'commit conflict' occurs, with only one update being accepted and the others left orphaned and unreferenced.
Failure lies in the fact that although the loser's log reports success, its data is actually in the trash.
For a deep dive into the mechanics of why these conflicts occur, Jack Vanlightly's analysis of Iceberg's consistency model is the definitive resource.
2. The Small File Performance Trap
Legacy monitoring focuses on infrastructure metrics like CPU and memory. When a query slows down, the default diagnosis is often resource saturation and cluster sizing.
In a metadata-first architecture, the problem is more often metadata bloat. This creates a 'metadata tax.' Your query engine spends 90% of its time reading the table's instructions instead of the data itself. To you, it looks like you need a bigger, more expensive cluster. In reality, you have a table that's become unmanageable.
3. Cross-Engine Schema Drift
One of the core promises of OTFs is that multiple engines (such as Snowflake, Trino, and Spark) can concurrently read the same tables. But a change that is perfectly valid in one tool can be unreadable in another. You see a successful run in dbt, and the data is physically there. But because your reporting engine doesn't "speak" that specific version of the data, the whole dashboard crashes.
These failures share a common root: they happen in the gaps between tools. When you decouple your stack, and you're looking for the truth, you have to look where the query engine looks: the metadata.
Sifflet: Metadata-driven Observability
Sifflet and the truth both start at the same place: the table state.
While legacy observability tools still work backward from execution signals, Sifflet operates within the metadata layer itself:
- Integrity reconciliation: Sifflet verifies that the intent of your pipeline, the files written to storage, is successfully reflected in the catalog. It identifies the gap between physical movement and logical availability.
- Operational health: Sifflet monitors the structural health of your tables, alerting you to metadata fragmentation and bloat before planning overhead degrades the end-user experience.
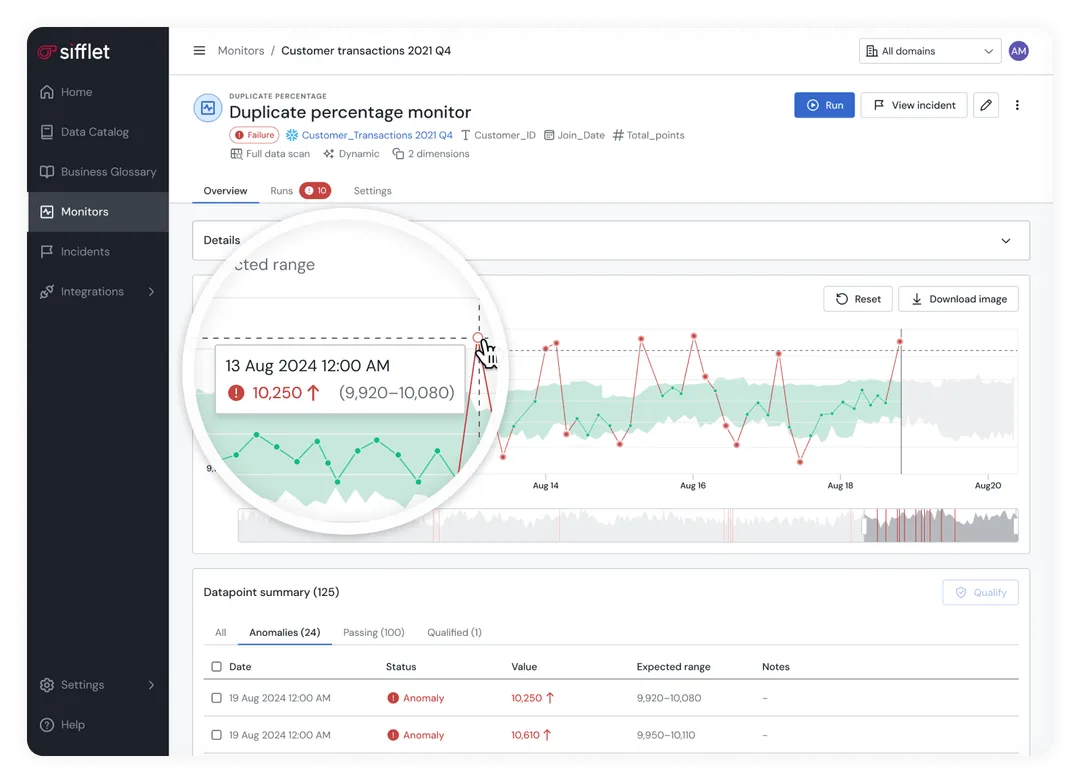
- Cross-engine compatibility: Sifflet evaluates schema evolution across the entire data stack, reducing the risk that a valid change in your transformation layer becomes a silent failure in your query engine.
Validating Reality, Not Just Activity
To deliver this protection, Sifflet integrates directly into your architecture through three core pillars:
- End-to-end lineage: Maps every data point from source to dashboard, so you can see exactly where the "Master List" failed to update.
- Metadata rofiling: Automatically audits table health to stop the Metadata Tax before it hits your cloud bill.
- Data contracts: Sets the rules for how data should look and behave, ensuring automated upgrades don't break downstream tools.
Move from Monitoring to Validation
The single pane of glass promised by integrated platforms is just a view of their own internal logs in an Open Data Architecture. It tells you what they tried to do, not what actually happened.
Sifflet eliminates the Phantom Success inherent in these systems. It provides the independent, metadata-driven confirmation required to move from monitoring activity to validating data reality.
Data trust in OTF is established through metadata. Sifflet is here to help you preserve that trust.
Book a demo with Sifflet today.















-p-500.png)
