



.jpg)
Enterprises didn’t lose trust in their data because of bad pipelines. They lost it because metadata was never built to scale.
When ownership, lineage, and quality signals are scattered, confidence collapses.
A metadata lakehouse turns metadata into a first-class system of record.
What Is a Metadata Lakehouse?
A metadata lakehouse is the queryable metadata layer in an Open Data Lakehouse architecture.
It integrates technical, business, operational, quality, and usage metadata to serve as the single system of record and control plane for open-format architectures.
Lakehouse principles, such as open formats and versioned states, make metadata portable, persistent, and entirely independent of any single tool or engine. The concept emerged as enterprises sought to separate compute from storage and free their operational intelligence from a vendor's proprietary environment.
To better understand this, let's examine the metadata lakehouse architecture more closely.
Architecture of a Metadata Lakehouse
In an open data lakehouse, the metadata layer sits above storage and compute, serving as the platform's control plane. While data remains in cloud object storage (S3/ADLS), metadata governs how that data is understood, trusted, and used across the entire stack.
Open table formats like Apache Iceberg, separate storage from compute. And because no single engine owns the table state, metadata becomes the sole mechanism that enables the entire system to function consistently.
Specifically, metadata defines the valid and trusted state of a table by tracking:
- Integrity: Which specific files and snapshots belong to the current, correct version
- Evolution: Which schema is valid at any given point in time
- Lineage: The provenance and flow of data from source to consumption
With these properties managed at the metadata layer, every tool in the stack remains in sync, sharing a single source of truth across the entire environment.
The Architectural Pillars of the Metadata Lakehouse
The metadata layer in Open Lakehouse consists of four pillars.
These are the structural elements that deliver on the core promise of Open Lakehouse architecture: metadata sovereignty and portability.
- The open storage layer
Physically stores metadata in the enterprise's own cloud environment using open table formats like Apache Iceberg.
This shift breaks the previous lock-in to a vendor's proprietary database, ensuring metadata remains a sovereign corporate asset.
- The unified metadata schema
Merges technical, business, operational, quality, and usage signals into a single, queryable layer.
This replaces fragmented, vendor-specific APIs with a unified relational structure that turns metadata from a passive audit log into an active, programmable map of the entire data ecosystem.
- The multi-engine compute layer
Allows various compute engines to interact directly with the metadata layer without a proprietary middleman. Every tool in the stack now operates on the same live state.
- The access and governance interface
Separates the application layer from metadata storage. It permits adoption of specialized tools for discovery and governance while maintaining a persistent, tool-agnostic system of record.
The Implementation Framework
Once the architectural foundation is in place, a set of functional elements work together to move metadata from across the stack into the lakehouse and transform it into a living system of record.
These components ensure that metadata is not only collected, but continuously refreshed, contextualized, and made actionable.
Ingestion controllers play a central role by automating the harvesting of technical logs, state information, and system signals from every tool in the data stack. This automation creates a continuous, near–real-time record of the data environment, allowing all teams in an enterprise to understand how systems behave as they evolve rather than relying on periodic snapshots or manual documentation.
Configuration and control tables then provide the logic layer that governs how data is handled.
By storing rules for masking, routing, and processing centrally, these tables enable a metadata-driven operating model in which pipelines can self-configure based on shared governance principles instead of brittle, hard-coded scripts. This approach increases consistency while reducing operational overhead as policies change.
Auditing and logging capabilities add a critical layer of trust and accountability.
By saving an immutable record of access requests, schema changes, and system actions, organizations establish a permanent trail that supports security reviews, forensic analysis, and regulatory compliance. This foundation simplifies audits while reinforcing confidence in the integrity of the data platform.
Notification engines close the loop between the metadata layer and the people responsible for the platform.
By distributing real-time alerts and status updates through tools such as Slack or PagerDuty, they ensure that the right stakeholders are informed at the right moment. This tight feedback loop allows teams to respond quickly to issues and align operational action with metadata-driven insights.
Building this infrastructure is only the first step. The real value emerges when raw metadata is organized and enriched through a purposeful tagging strategy, transforming technical signals into structured intelligence that the business can trust and act upon.
How to Implement a Metadata Lakehouse
The highest-value metadata lakehouse implementations succeed by balancing architectural rigor with clear business outcomes.
Rather than treating metadata as a purely technical concern, leading organizations adopt an execution strategy that aligns governance, platform intelligence, and operational relevance from the outset.
This starts with clearly defining scope and ownership.
Teams focus first on the domains where fragmented or unreliable metadata creates the greatest risk, such as financial reporting, regulatory compliance, or AI readiness. By anchoring early efforts in these high-impact areas, organizations ensure that metadata initiatives are driven by tangible business needs rather than abstract platform goals.
A critical architectural principle is anchoring metadata in open formats.
Standardizing metadata storage on open table formats such as Delta Lake and Apache Hudi ensures that platform intelligence remains a sovereign asset, independent of any single vendor. This approach preserves flexibility over time and enables metadata to flow freely across tools, engines, and teams as the ecosystem evolves.
Establishing end-to-end lineage further strengthens this foundation.
By mapping data flows from source systems through transformation layers to downstream consumption, organizations enable impact analysis and foster trust in analytics and AI outputs. Lineage also acts as the connective tissue that allows metadata to move seamlessly across the stack, rather than becoming siloed within individual platforms.
To make metadata operationally meaningful, high-performing teams adopt an active tagging strategy.
Attributes such as sensitivity, criticality, or regulatory relevance transform metadata into functional signals that can be automatically applied as data moves and changes. When combined with operational signals, such as freshness, volume, and anomaly detection, metadata becomes a real-time indicator of both technical health and business risk.
Finally, successful programs are operationalized incrementally. Instead of attempting a risky “big bang” rollout, organizations deploy metadata-driven governance workflows domain by domain. This incremental approach builds organizational momentum, delivers early wins, and allows teams to refine practices over time.
Successful metadata lakehouse implementations move beyond basic architecture to adopt a production-first mindset.
There are three core principles that guarantee that the system remains scalable and trusted:
- Design for openness
- Treat metadata as production data
- Prioritize automation
Define a Metadata Tagging Strategy
To correctly design a successful metadata lakehouse it is also important to define a metadata tagging strategy.
- Criticality mapping:
Identifying data sensitivity (PII), business value, and ownership to manage data assets according to their individual risk profiles and organizational importance.
- Automated assignment
Capitalizing on system-generated signals and AI inference to assign tags automatically, and to limit manual assignment to only the most nuanced datasets.
- Operational enforcement
Linking tags directly to platform behavior, i.e., access masking, to further metadata as an active enforcement layer.
For detailed, step-by-step instructions, read our guide to metadata tagging.
Sifflet and Apache Iceberg in a Metadata Lakehouse
Metadata must be both open and actionable in a metadata lakehouse. Sifflet and open formats like Apache Iceberg work together to provide a sovereign, automated control plane.
For example, while Iceberg provides the storage standard for metadata persistence, Sifflet provides the observability and automation required to act on that data.
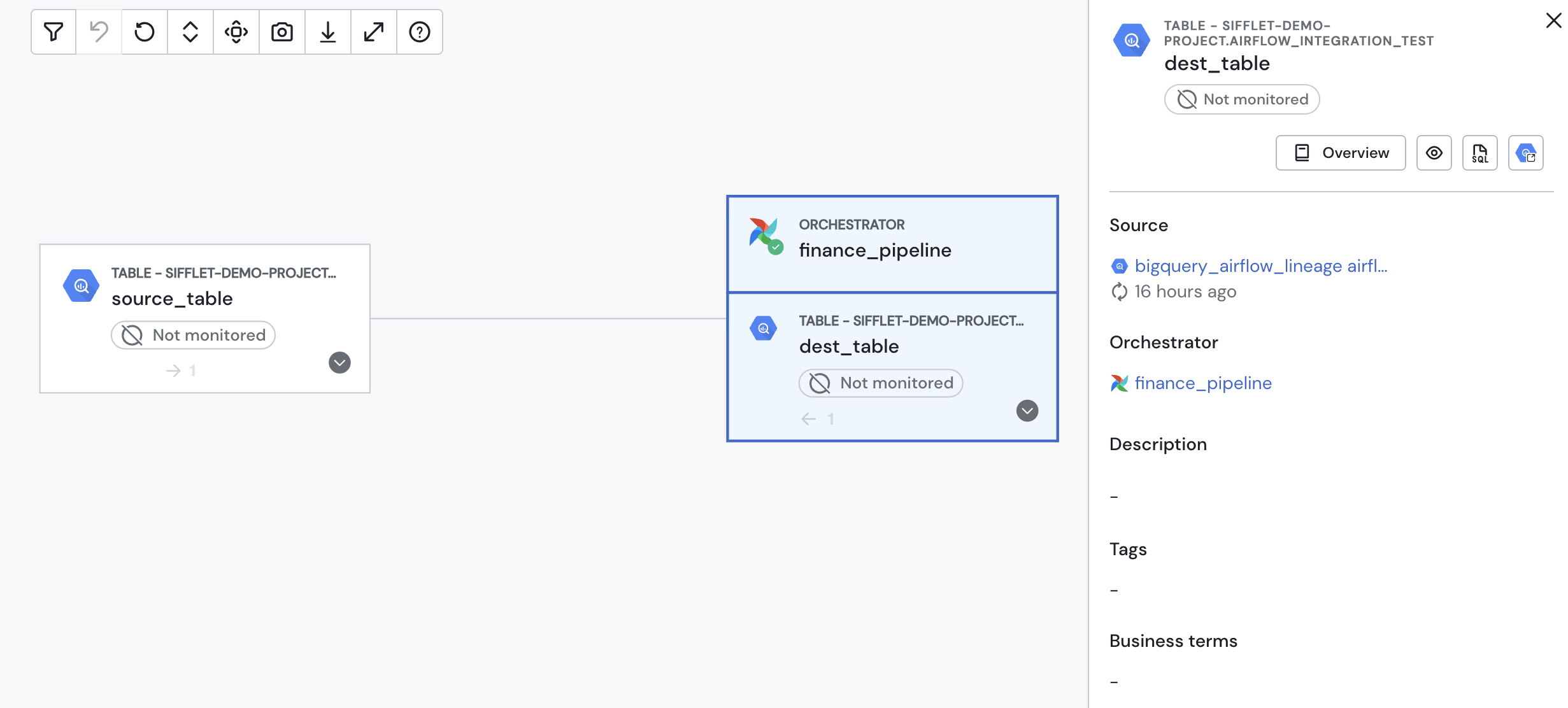
Apache Iceberg tracks every snapshot, partition, and schema change within your cloud storage. Because these metadata files are open and queryable, they serve as the authoritative system of record for table state across the entire stack.
Meanwhile, Sifflet ingests Iceberg metadata to reconcile table state across all compute engines, tools, and processes. Sifflet identifies cross-engine inconsistencies before they impact the business.
How Sifflet Uses Metadata
Sifflet uses metadata as a continuous input to drive high-value governance and incident response workflows, both in metadata lakehouse architectures and traditional designs.
1. Ingesting Technical Metadata at the Source
Sifflet harvests physical metadata (schemas, partitions, and commit histories) directly from Iceberg's manifest files. Observability into these open storage logs provides insight into data health by showing how tables actually behave.
2. Automated Classification and AI-Driven PII Detection
Using Sage's AI agent, Sifflet analyzes metadata and data samples to identify sensitive fields and regulatory risks. This automated classification keeps PII and sensitive tags up to date even as schemas evolve.
3. Data Quality Scoring and Trust Signals
Quality signals, such as freshness, volume shifts, and schema changes, are calculated and continuously joined with business metadata. Sifflet produces a dynamic Trust Score for each data asset, rating its reliability against predefined thresholds.
4. Lineage-Driven Impact Analysis
By mapping end-to-end field-level lineage, Sifflet understands every downstream dashboard, dbt model, and AI application affected by a data issue. This helps prioritize business-critical issues over routine matters.
5. Active Alerting and Incident Triage
Sifflet uses three specialized AI agents to group related anomalies, aid remediation efforts with suggested fixes, and automate incident and solution record-keeping to support future issues.
From Metadata Lakehouse to Metadata Sovereignty
The data stack has undergone a fundamental shift: the Open Data Lakehouse movement has freed compute from storage. But while data has moved to open cloud buckets, the intelligence remains locked in a proprietary black box.
The emergence of the Metadata Lakehouse represents the final unboxing. We’ve finally achieved metadata sovereignty by moving intelligence into an open, queryable format.
But as the lakehouse provides the physical storage for metadata, Sifflet provides the intelligence to act on it.
- Ingesting open signals
- Automating trust
- Orchestrating governance
- Prioritizing business impact
Ready to unbox your metadata? Stop renting your intelligence from proprietary silos. Book your demo today to see how Sifflet transforms your open lakehouse into a self-governing ecosystem.















-p-500.png)
