




Monte Carlo Data is shifting their focus and moving toward agentic observability.
In this Monte Carlo Data review we will help you figure out if it’s still the right for you as we take a look at its features and user reviews.
What Is Monte Carlo in Data Observability?
Monte Carlo, a major player in the data observability space, focuses on solving one main pain point: data downtime.
Using machine learning to monitor data, pipelines, and AI systems, Monte Carlo scans for unintended changes in the data's structure and quality.
The platform operates through read-only connectors that extract metadata, usage logs, and behavioral signals from data storage platforms and BI tools. Raw data and PII remain untouched.
Using that telemetry, ML establishes behavioral baselines, flags deviations, and traces the source of variations, mapping their downstream dependencies. The tool supports root cause analysis through remediation workflows assembled for alert routing, escalation, and remediation.
Monte Carlo is available as either a fully managed SaaS or through a hybrid model using on-prem hosted collectors.
What Can Monte Carlo Data Observability Platform Do?
Monte Carlo delivers visibility into data health by linking signals across systems and feeding these to teams using a unified interface. Each team leverages the product to its own ends.
As an automated sentry for data engineers, the product scans upstream workflows, ingestion jobs, and transformations for unexpected behavior or failures.
Downstream, analysts rely on the tool to confirm data's integrity before errors corrupt dashboards and insight generation.
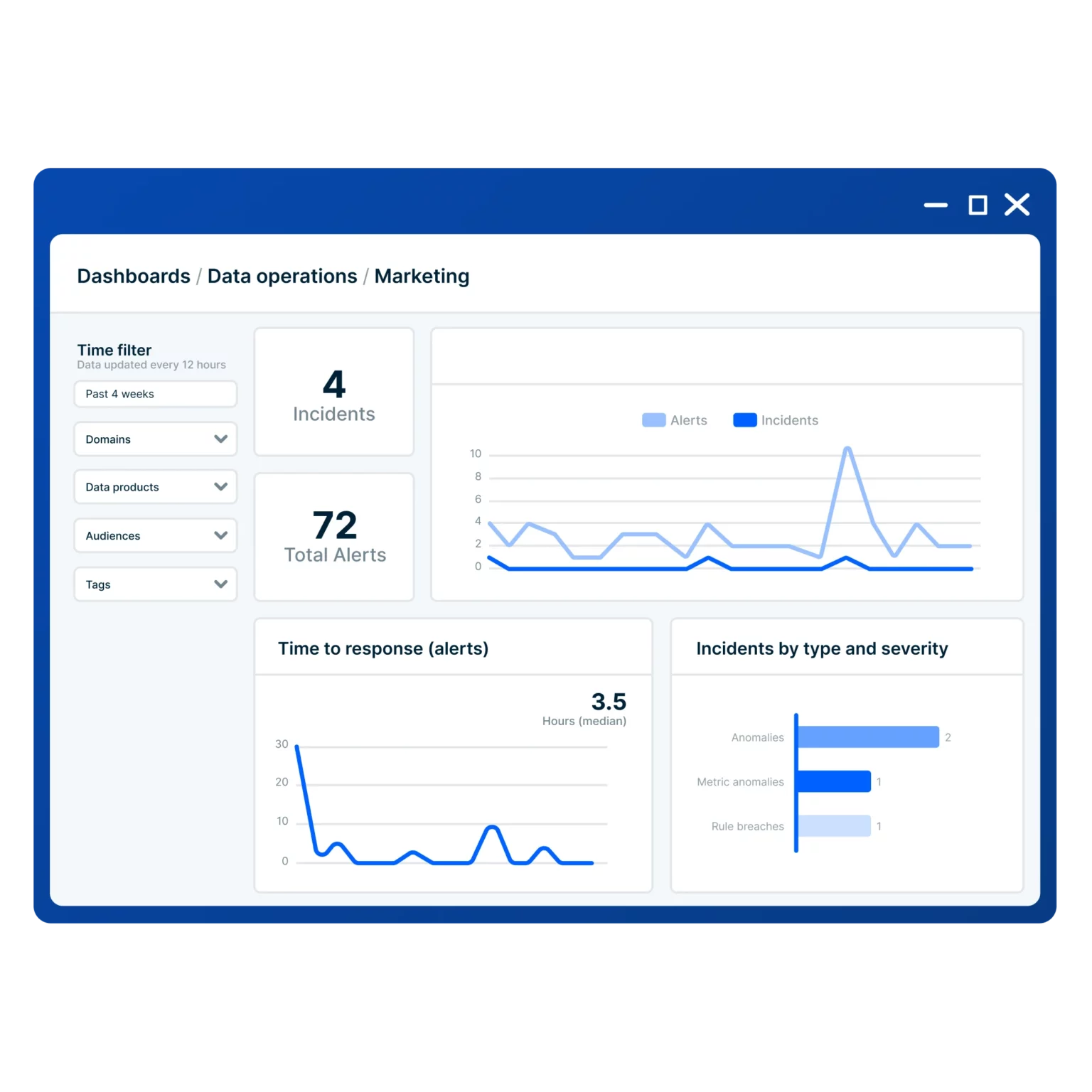
Data scientists employ the platform's AI observability tools to track the stability of model inputs and outputs. Changes in either are flagged and alerted, giving notice to otherwise unseen degradation in their performance.
Platform leads and data executives use the tool's incident reporting, SLA metrics, and coverage analytics to follow data quality trends, system reliability, and to evaluate operational risk.
Overall, Monte Carlo delivers on providing visibility into data reliability through anomaly detection and alerting.
However, each team must invest time in tuning and configuration to meet its individual goals.
Is Monte Carlo the Right Data Observability Platform for You?
Monte Carlo best serves enterprises with complex pipelines, fast-changing codebases, and material risk tied to data errors, whether regulatory, operational, or AI-related.
Its sweet spot includes organizations managing dozens or hundreds of pipelines across storage and orchestration layers and varied BI tools. For highly-regulated industries, Monte Carlo's lineage, audit history, and incident tracking adequately suit both governance and compliance needs.
The platform also offers value for AI-driven operations. For those enterprises running ML and/or generative agents in production, Monte Carlo detects drift and input failures that upstream systems may miss.
The tool is less suitable for mid-sized and smaller companies with less expansive infrastructure or those with minimal external compliance pressure.
While designed to manage complexity, Monte Carlo regrettably introduces it into its pricing and setup.
Top Use Cases for Monte Carlo Data Observability
Anomaly detection engine is the centerpiece of Monte Carlo's observability strategy, scanning metadata for deviations without complex threshold-setting or writing validation rules. This baseline-driven approach is its most reliable strength.
Incident response is another strength. Its combination of anomaly correlation and field-level lineage traces disruptions back to the job, table, or schema change that triggered them. It reduces triage time considerably.
Monte Carlo is a pre-check layer for business intelligence workflows, preventing flawed data from reaching dashboards and decision-making. That said, reliability here depends on coverage. Spot checks or custom monitors will be necessary wherever connectors lack full functionality, particularly for less-common BI tools or custom pipelines typical in legacy systems.
Monte Carlo's AI observability features show promise, particularly for monitoring model input drift and flagging shifts in feature distributions. These mechanisms work well for traditional ML. The newer LLM output scoring adds potential but requires thoughtful configuration to produce actionable alerts without excess noise.
For compliance-minded teams, Monte Carlo's reporting capabilities are functional out of the box. Lineage, SLA tracking, and audit logs streamline routine governance tasks. However, adapting them to special requirements or formal regulatory standards can mean extensive customization will be required.
Monte Carlo Data Observability Features Reviewed
Monte Carlo’s core platform is anchored in its detection-first philosophy: capture anomalies early, surface their impact quickly, and accelerate resolution through metadata and lineage.
Below, we review how each capability performs and how well it supports users in identifying, diagnosing, and resolving reliability issues at scale.
Agentic Observability Layer
Monte Carlo’s newest addition, an agentic observability layer, marks a shift in how the platform approaches incident response.
Its autonomous agents don’t replace human decision-making but attempt to bridge the long-standing gap between detection and resolution with assistance for the incident response process.
Each agent runs continuously, monitoring telemetry, anomalies, and lineage updates.
When incidents occur, agents surface enriched context: affected assets, blast radius, past occurrences, and probable upstream sources. These insights now appear directly within incident pages, alongside lineage views and anomaly timelines, to offer a more actionable package of information.
The agents also recommend response actions. These include notifying owners, escalating to other systems, or investigating related incidents with similar patterns.
But to be clear: Monte Carlo doesn’t execute these actions. It suggests them. Users still drive remediation and resolution.
For many, this structured handoff is an improvement over the open-ended alert streams typical of detection-first platforms. But the autonomy is limited. There’s no true policy framework, embedded remediation logic, or learning loop that refines its responses over time. The agents are helpful, but they’re not yet strategic.
While these agentic agents bring Monte Carlo closer to operational intelligence, they still lack deep business context, such as prioritizing incidents based on real business impact or SLA alignment.
Monte Carlo’s agentic observability is a credible first step toward more operational intelligence. However, whether it closes the post-detection gap will depend on how much Monte Carlo evolves beyond recommendations into orchestration.
Data Quality Monitoring
Monte Carlo’s quality monitors ingest telemetry from connected sources and score deviations using ML baselines. Custom monitors and exclusions are available and often essential in high-volume environments. The defaults spot major quality issues quickly, but precision requires additional effort to avoid alert fatigue.
Sensitivity controls help focus detection efforts, but fine-tuning remains a shared task, especially when data quality impacts business-critical reporting or SLA commitments.
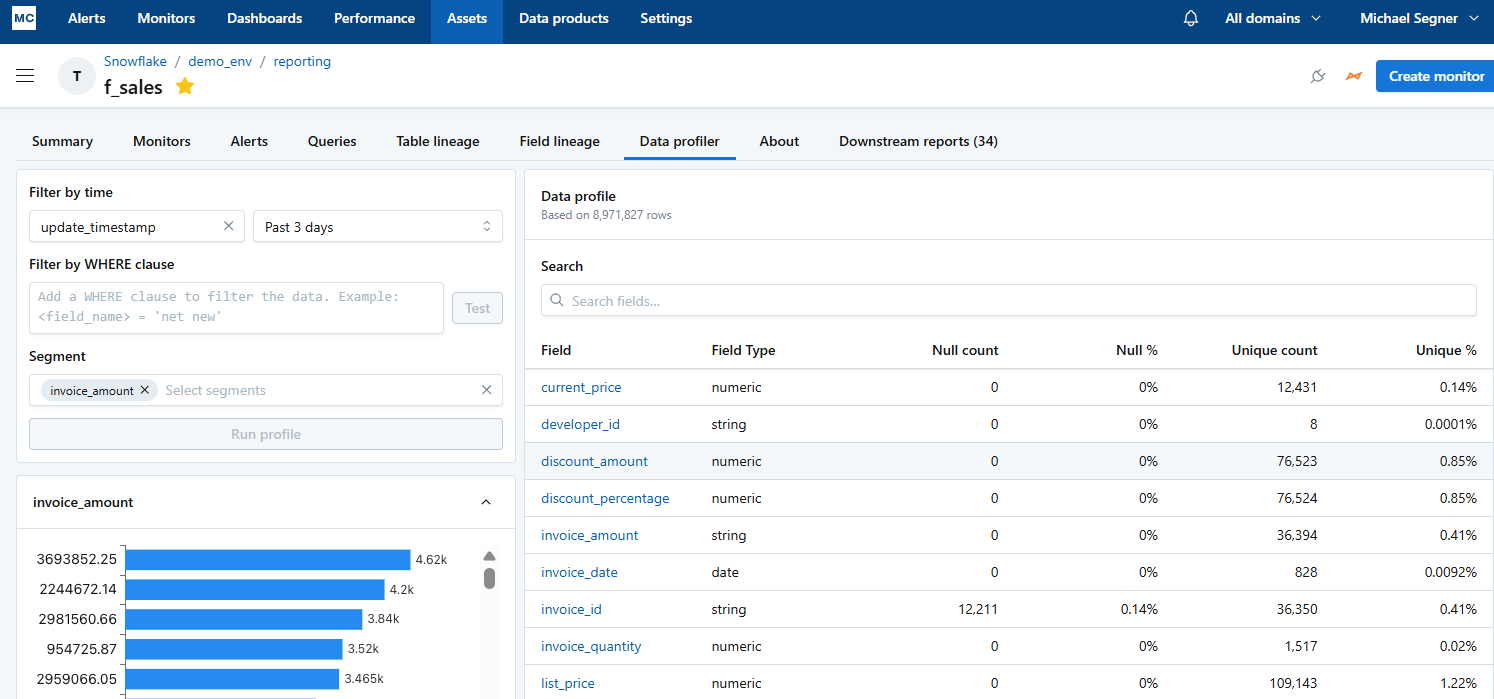
Root Cause Analysis
The platform uses metadata, lineage, and query history to connect anomalies to their likely upstream source. The platform visualizes dependency paths and flags probable breakpoints, helping narrow the scope of investigations. Analysts can quickly trace incidents from broken dashboards to specific pipeline jobs or tables.
In practice, that speeds up the diagnostic phase, but resolution remains manual. The platform doesn’t prescribe fixes, trigger automated runbooks, or close the loop with guided remediation. It points to what’s broken and where, but not what to do next, making root cause analysis faster, but still operationally incomplete.

Field-Level Lineage
Automated data lineage maps column-level dependencies across supported platforms, producing clear lineage graphs that help assess downstream impact. Visualizations are rich and complete for standard connectors and common transformations.
Its coverage has limits, though. Complex SQL logic, dynamic code, or custom pipeline behaviors may escape full mapping. In these cases, users often rely on manual validation to fill in the gaps.
For typical workloads, Monte Carlo’s lineage is reliable and useful. For edge cases, it’s a solid foundation, but rarely complete on its own.
Metadata Profiling
Monte Carlo’s Metadata profiling produces summary statistics directly from all connected assets. These signals fuel automated coverage maps, ownership tagging, and visibility reports that help to spot neglected tables or blind spots in observability.
Profiling is fast and functional, but intentionally shallow. It’s built for monitoring, not investigation. Technical users handling advanced analytics, schema evolution, or audit scenarios will likely need supplemental tooling.
Monte Carlo’s profiling adds operational value, but it’s not the last stop for deeper analysis.
Overall, Monte Carlo's features align well with its detection-first philosophy of broad coverage, fast insight, and minimal friction.
Monte Carlo Review: Pros and Cons
Monte Carlo has gained recognition as a category leader.
However, its effectiveness depends largely on the structure and maturity of the data infrastructure it intends to serve.
Given its focus on detection, it covers broad ground with minimal setup, offers credible root cause analysis, and surfaces reliability gaps faster than manual approaches. The tradeoff, however, is control: managing noise, monitoring priorities, and managing complexity often falls back on the user.
Pros
- Fast setup, smart defaults
Asset discovery and baseline monitors work well out of the box, especially in mature cloud-native stacks.
- Cross-system anomaly correlation
Anomaly timelines and lineage overlays assist teams in connecting symptom to cause without jumping between multiple tools.
- Usable lineage
Monte Carlo automatically infers lineage from the field level across supported systems. It's accurate enough to trust in impact assessments and fast enough to support real-time triage, but could offer more toward resolution.
- AI observability
Model inputs and LLM outputs can be monitored without separate tooling, although they are recent additions, non-native, and still early-stage.
- SaaS-first, hybrid-capable
Deployment is flexible, with SaaS and optional hybrid versions available.
Cons
- Pricing concerns
Event-based billing can surprise mid-sized teams with high activity and limited budgets.
- Limited control for custom checks
The platform favors automation over configurability; if you need complex validations, you may feel constrained.
- Coverage gaps for edge systems
Less-common tools or custom pipelines may require extra lift or go unmonitored entirely by the platform.
- Advanced features learning curve
LLM scoring, custom monitors, and incident tuning require deeper familiarity and technical skill to operate effectively.
What Users Say About Monte Carlo
Monte Carlo earns strong marks from users for its time-to-value. Reviewers on G2 and other review platforms frequently report detecting data issues within days of completing deployment. Comments also highlight the reliability of field-level lineage, describing it as both accurate and practical for resolving incidents.
Alerting workflows receive credit, too.
The delivery of centralized views, anomaly timelines, and root cause overlays speeds triage efforts. Reviews credit Monte Carlo's correlation of upstream anomalies with likely triggers in cutting time spent on investigation.
Ongoing product development is another positive theme across reviews, with users pointing to regular updates and improvements in the product's UI, integration, and support for AI observability.
Monte Carlo Limitations According to Users
That said, users also cite pain points.
Out-of-the-box monitors are described as noisy, particularly in environments with high pipeline volume. Tuning thresholds and managing alert fatigue are noted as necessary early steps. Pricing concerns are frequently raised as a prime consideration, with some users commenting that spend via the usage-based model can escalate quickly.
Advanced features like LLM output scoring and domain-based trust scoring are generally seen as promising, but not always intuitive.
Users say these capabilities often require deeper product knowledge or onboarding support to implement successfully. Others report coverage gaps when working with legacy systems or custom-built tools.
In short, users express that Monte Carlo performs well on its core promise of early detection, while post-detection processes remain underwhelming.
Moreover, scaling the product's benefits often depends on the organization's technical depth and available resources, which should give pause to those seeking relief from manual processes and additional heavy lifts.
Sifflet as an Alternative to Monte Carlo
While Monte Carlo leads with broad detection coverage, its model is too focused on detection and lacks support for resolution, accountability, and intuitive use.
There are better alternatives.
Sifflet sees data observability as more than anomaly detection and alerts. Sifflet unifies cataloging, monitoring, and lineage into a single observability layer, making it easier for teams to track, trust, and act on data.
Embedding business context into alerts and insights helps technical and non-technical users collaborate on reliability without relying on tribal knowledge or manual triage.
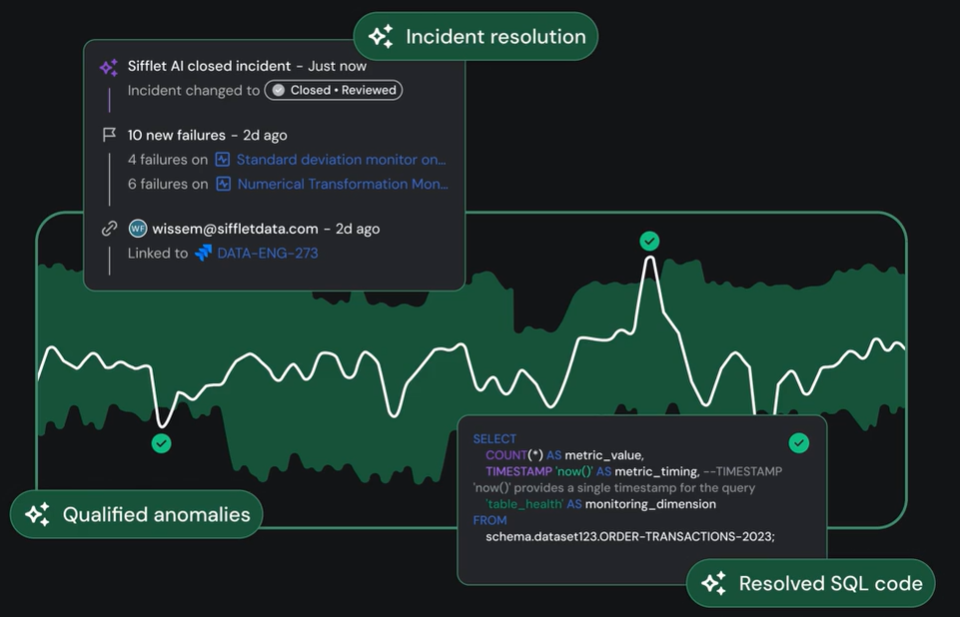
Sifflet incorporates AI into every stage of the incident lifecycle, moving data quality and anomaly issues from detection to resolution with less friction and more confidence.
Sifflet's AI-Native Platform
Unlike platforms where AI features exist as add-ons, Sifflet is AI-Native. Its agents operate in tandem through detection, diagnosis, and remediation.
They are connected components, not separate workflows, that construct a highly interactive and guided experience. Remediation follows a single-threaded guided path from detection to root to resolution.
Trust is not only foundational, but measurable. Sifflet quantifies reliability through dynamic Trust Scores that align with SLA commitments and governance policies. These scores roll up by business unit or data owner, supporting accountability and confidence in data across the enterprise.
Setup is lightweight, with complex environments requiring weeks, not months, unlike other solutions.
From Detection to Resolution: Sifflet's Advantage
Move beyond detection. Sifflet delivers a modern, AI-Native observability experience that allows enterprises to track, trust, and act on their data.
Book your demo today.















-p-500.png)
