




Traditional observability: "Here are your logs, metrics, and alerts. Good luck!"
Agentic observability: "I discovered what broke, why it broke, what it affects, and here's what I've done about it."
That's the difference between old-school observability and agentic observability.
Traditional monitoring and observability models report conditions without understanding them, forcing engineers to piece together root cause, context, and remediation. They simply can't keep pace with this level of complexity.
Fortunately, enterprises have started to respond.
With agentic observability.
What Is Agentic Observability?
Agentic observability uses automated AI agents or assistants to monitor systems, interpret signals, and guide next steps for problem resolution. These agents evaluate metadata, lineage, and usage patterns to detect issues, connect related symptoms, and surface likely root causes.
When something breaks, an AI agent observability model produces a clear narrative of what failed, why it happened, what it affects, and the best next steps toward resolution.
Agentic observability exists to detect and understand data failures, and help remediation teams recover faster by shifting the heavy, context-building work from humans to AI agents.
How do AI Agents Manage Complexity
As data issues proliferate and alert volumes grow, the time spent investigating them has become untenable. Engineers lose 20-40% of their available time to technical debt, rework, and tool friction.
Engineers are spending hours tracing issues across environments that are expanding faster than they can map them.
Yet, agentic observability offers more than time savings.
It's bolstering data reliability.
Bear in mind, that inaccurate data isn’t just annoying or time consuming. It’s expensive. Poor data quality costs the average enterprise $15 million per year. Downtime only compounds that loss, with a single hour often exceeding $300,000 in lost revenue.
Agents can identify early signs of instability before they escalate to full-blown incidents.
They uncover dependency risks that go unnoticed in large, sprawling multi-cloud systems. And they preserve institutional knowledge of investigations and successful resolutions that are often lost to turnover.
Those advantages explain why demand for AI agent observability is rising fast.
How AI Agents Perform in Agentic Observability
Agentic observability places AI agents at the centre of monitoring and incident management.
Most platforms follow a simple process: agents scan the environment, learn what's normal and what's broken, and then act by guiding or executing remediation.
Step 1: Scan
AI agents read the signals like an experienced engineer would.
They examine metadata to understand structure, lineage for data flow, usage patterns to understand what and how data is used, and investigate changes that often signal impending issues.
AI Agents study operational metrics and data quality indicators to gain situational awareness with which to spot anomalies and other data issues.
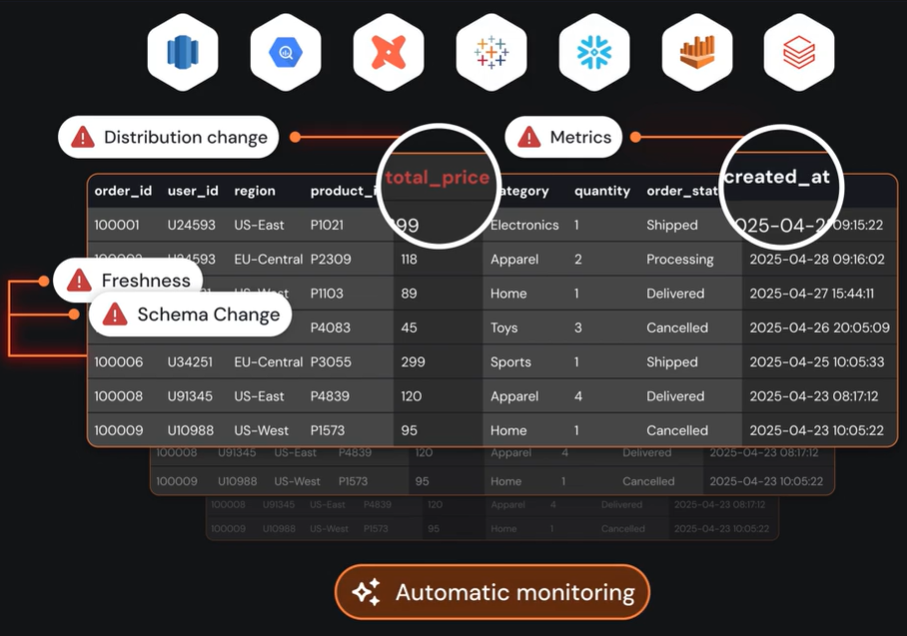
Step 2: Learn
Agents build a baseline for each dataset and pipeline. They track row counts, distributions, and other quality signals across days, seasons, and load patterns.
Through this, they establish what "normal" looks like for each asset, enabling them to distinguish between routine fluctuations and real problems.
When an anomaly does surface, an agent shifts from observation to investigation. It traces lineage and examines recent operational changes to identify where and why the issue arose.
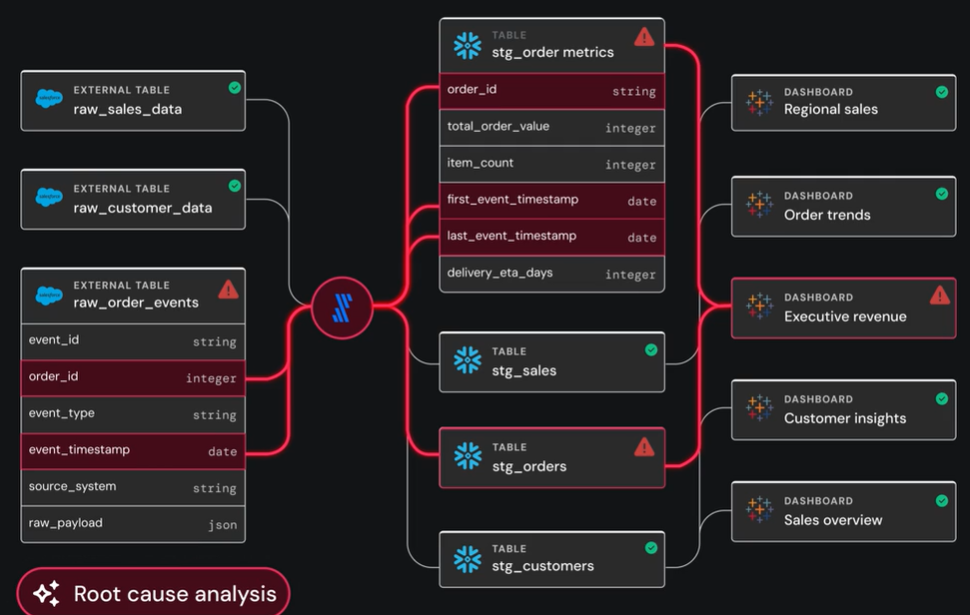
Likewise, agents can determine which issues and alerts are related, bundling them into a cohesive diagnosis.
That creates a more accurate signal layer, reducing false positives and focusing effort where it is needed most.
Step 3: Act
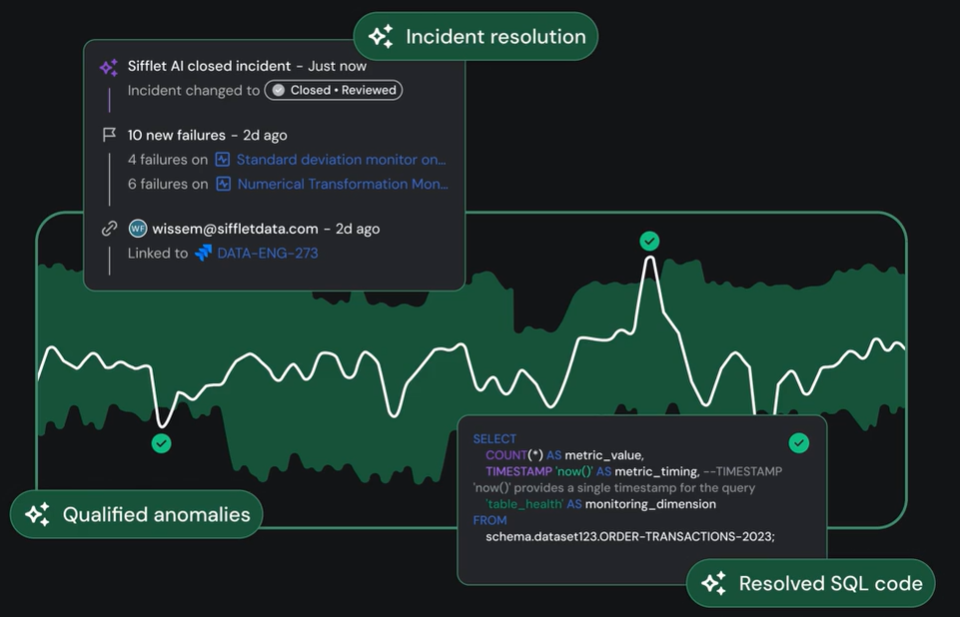
Agents recommend next steps for issue resolution.
It may direct attention to a specific table, transformation, or deployment. Some platforms flag downstream dependencies to help protect production and analysis processes from compromised data.
Agentic observability provides data quality and anomaly detection, root cause analysis, and detailed guidance for remediation of data issues at a pace and scale beyond traditional observability or human capability.
How to Use AI Agents in Observability with Sifflet
Agentic observability brings AI intelligence to monitoring and incident workflows.
Here's what that looks like in practice using Sifflet's platform with its AI agents: Sentinel, Sage, and Forge, as an example.
1) Connect Sifflet to your warehouses, transformation layer, orchestration, and BI tools.
Sifflet's AI agent Sentinel:
- Reads metadata, lineage, freshness patterns, schema drift, and usage to understand data flows and critical assets.
- Recommends a monitoring strategy for tables, pipelines, and dashboards based on risk and business importance.
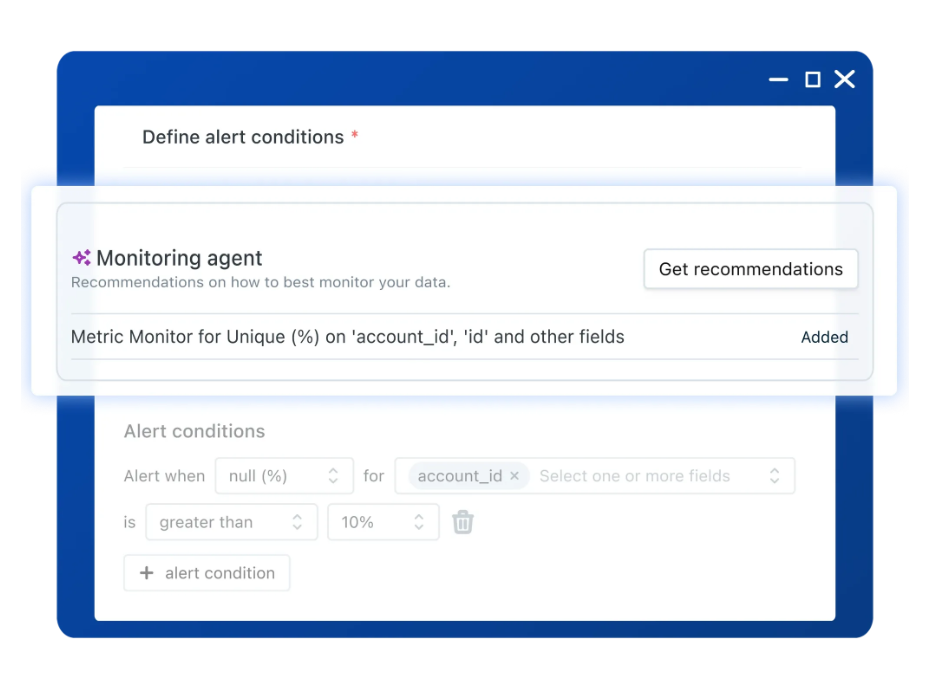
2) Approve and adjust Sentinel's recommendations where necessary.
Sentinel recommends monitors and flagging patterns that have historically led to incidents.
3) Choose alerting thresholds and channels: email, Slack, PagerDuty, etc..
Sage bundles related alerts into a single narrative and routes them to affected data owners via their preferred channel.
4) Review Sage's incident view: probable root cause, impacted assets, affected SLAs, and owners.
Sage prioritizes the most business-critical issues first: those impacting executive dashboards, revenue models, and regulatory reports.
5) Review and approve changes before they hit production.
Forge provides suggested fixes based on its assessment and on what worked in previous incidents. Remediation teams receive a vetted, context-laden recommendation they can accept, modify, or reject.
6) Implement the agreed fix and close the incident.
Sentinel refines its understanding of "normal" for affected assets and updates monitoring recommendations accordingly.
Sage enriches its incident archive by linking this fix to similar patterns for future root-cause analysis.
Forge improves its remediation suggestions based on which drafts were accepted or adjusted.
Each incident adds to the platform's understanding of your systems. New alerts become more precise, explanations more detailed, and suggested fixes pave the way to faster resolution.
With AI Agents managing data incidents from detection to solution, people are free to focus on higher-level work rather than tedious manual investigation.
Best AI Observability Tools
Several leading AI observability tools now offer agentic features worth comparing.
Below is a quick look at a few of those solutions.
Sifflet Data Observability
Sifflet takes a native-AI approach to observability. The platform runs on a trio of agents, Sentinel, Sage, and Forge, that behave more like an engineering team than background automation. Although each handles a distinct part of the incident cycle, they work cooperatively to provide a comprehensive account of system performance and data quality.
Sentinel is the scout. It brings critical signals to the surface and filters out noise.
When an issue requires attention, Sage steps in and pulls all the details together; one vetted story instead of a pile of scattered alerts. Forge proposes concrete fixes based on the incident's relevant information and the history of what's worked before.
Sifflet delivers a true multi-agent model. The platform interprets issues, constructs incident stories, and drafts fixes based on what has worked before. This is agentic observability by design, not by feature.

Monte Carlo Data Observability
Monte Carlo leans into agentic thinking. The platform focuses on preventing data failures and unstable AI outputs from reaching production.
Its Circuit Breaker feature stops pipelines when key quality rules fail. In high-stakes reporting or compliance work, this is a practical bulwark against corrupted data seeping into dashboards, models, or downstream systems.
Monte Carlo carries the same attitude into AI workloads. Its AI monitoring tracks prompts, inputs, output anomalies, and even the unusual behaviors that emerge when a model begins to drift.
Monte Carlo takes a guardrail-first approach to agentic observability. Instead of building multiple cooperating agents, it focuses on enforcing strong, automated controls to prevent bad data from reaching production.
Bigeye
Bigeye takes a practical approach to agentic observability. Instead of building a complete multi-agent system, it layers intelligent behavior into two key areas: keeping monitoring calibrated to reality, and helping resolution teams make better sense of incidents.
Bigeye's Autothresholds feature handles one of the most tedious parts of observability: setting and tuning detection logic. It studies historical behavior and adjusts thresholds to keep alerts relevant as data changes.
Another of the platform's AI features, bigAI, serves as Bigeye's incident assistant. When something breaks, it gathers the surrounding context to piece together a likely explanation.
Bigeye provides agent-like behavior for monitoring and diagnosis, but doesn't operate as a coordinated multi-agent system. It enhances existing workflows rather than owning them, and teams must still drive strategy, remediation, and long-term improvements.
Do You Need Agentic Observability?
Yes, you do.
Enterprises are adopting agentic AI observability to manage the scale and speed of today's distributed stacks.
Far too complex for traditional monitoring, and with more data incidents than manual investigation can reasonably handle, agentic observability has become the new standard for quality in data monitoring.
More incidents, deeper dependencies, and shrinking human resources are making it clear that agentic observability is the answer to this crisis of complexity.
Ready to see what Native-AI observability looks like in practice?
Get a closer look at Sifflet. Book a demo today and put agentic workflows to work in your own stack.















-p-500.png)
