




What defines data trust?
On the surface, data trust is confidence that the information your enterprise uses is accurate, complete, timely, and fit for purpose.
When trust is strong, the data platform becomes infrastructure. Analysts build without hesitation. Executives make decisions without second-guessing the numbers.
When trust breaks down, everyone pays the price. Data teams firefight instead of building. Analysts create shadow processes to clean their data. Executives delay decisions while people verify what should already be reliable.
Data observability is the solution. A platform that shines a light on what’s happening accross the data platform.
But here's what many may not realize: observability tools don't take a universal approach to trust.
Data observability platforms establish their approach to reliability and trust, and each one shapes your operations and outcomes.
Technical Indicators As Trust
"The signals are clear."
The premise is simple: trust begins to erode the moment a data issue becomes someone else's problem. A broken dashboard in a board meeting. A stale table that stops an analyst cold.
In this approach, technical signals (freshness, volume, schema changes, distribution shifts) underpin data reliability. Trust is built by detecting anomalies in those signals and resolving them before the business notices.
The goal is speed and containment. Catch the break in the technical signals, understand the blast radius, and resolve it fast.
Platforms like Monte Carlo watch for those exact breakpoints.
When an alert fires, it surfaces what's affected downstream and who's likely to care. Someone gets paged at 6 AM. They trace the issue to a failed dbt job, restart the pipeline, verify the refresh, and close the ticket. MTTR: 24 minutes.
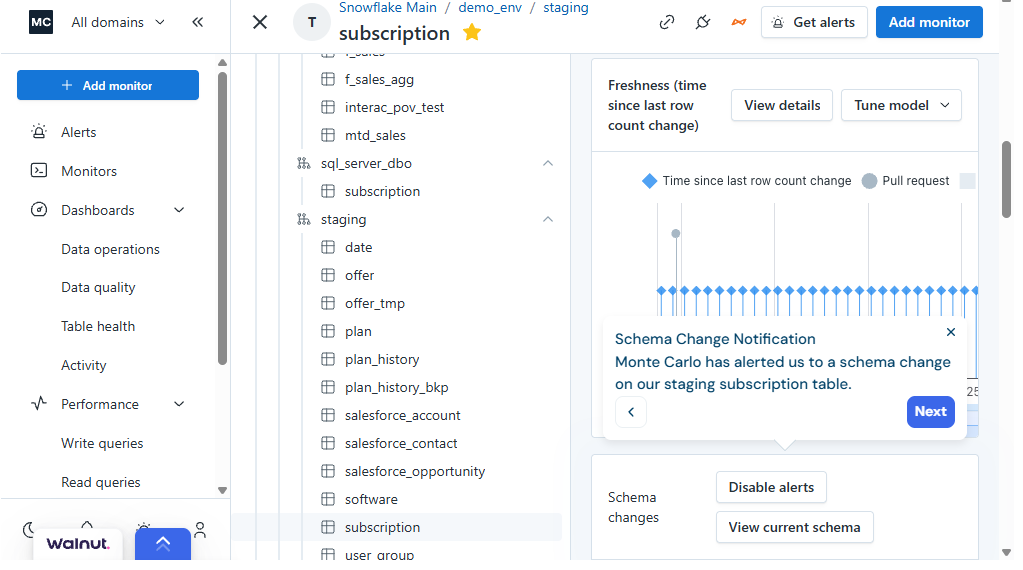
This approach creates operational muscle. Data teams organize around alert queues, and standups become incident reviews. Trust is measured in MTTR.
For the enterprise, the language of accountability shifts: if it didn't fire an alert, it didn't matter. The business learns it can count on the data team to catch problems before they cascade.
This brings us to the fundamental limitation of the technical indicator model: it can't address a lack of context.
It works perfectly until trust shifts from technical outages to disputes over meaning.
- Manual validation: Analysts spend hours sanity-checking a dashboard before a meeting, even though no alerts fired. They're checking for logic, not just uptime.
- Silent semantic drift: A pipeline is technically healthy, but the way Gross Margin is calculated changed in an upstream tool. The data flows, but the number is wrong.
- Lack of knowledge: An executive asks a pointed question about a data point. The data team, seeing green lights in their monitors, still can't answer with 100% certainty because they lack visibility into the usage and lineage of that specific metric.
This is where the "Incident" and "Quality" POVs hit a wall. They treat data as a technical artifact to be monitored. But trust is a social contract to be defended.
Operational Reliability to Build Data Trust
"The System Runs Predictably"
Some platforms see data trust as an extension of SRE (Site Reliability Engineering).
In this worldview, trust is a byproduct of a predictable system. If the dashboards load on time, the compute costs are optimized, and the pipes never clog, the data is considered reliable.
The premise is that catching incidents isn't enough; you have to outrun them. This approach treats trust as an engineering discipline centered on infrastructure health and closed-loop remediation.
Steps in the operating model:
- Monitor system performance.
- Detect the bottleneck.
- Diagnose the resource conflict.
- Automate the fix.
- Prevent the recurrence.
Acceldata exemplifies this approach by shifting the focus from what the data says to how the data moves.
When a pipeline delay triggers an alert, the platform identifies the specific Spark job or compute bottleneck, suggests a resource adjustment, and queues the fix.

The data engineer reviews and approves the change, and the system applies it. The next time that pattern appears, the loop closes faster, often without human intervention.
This model transforms data engineers into Data Reliability Engineers (DREs). They stop chasing individual null values and start writing runbooks. They build automation, track SLAs, and optimize for predictability.
Standups shift from "what broke yesterday" to "what patterns are we automating this week." Success is measured in self-healing infrastructure and tighter execution windows.
Sometimes reliability isn’t enough
But here's where reliability and trustworthiness diverge. A system can be perfectly operational and still produce numbers the business can't defend.
The pipeline executes on schedule. The schema is stable. The dashboard updates like clockwork.
The revenue number is still incorrect.
System reliability optimizes for predictable infrastructure, but it often stops at the water's edge of data logic. A flawlessly running engine can simply be driving in the wrong direction.
Quality Validation Establishes Data Trust
"This Data Passed Validation"
Data quality standards (distribution patterns, null rates, schema conformance) establish the basis for reliability. Trust is built by validating data against those standards before promoting it to production.
Silent degradation is the real enemy.
Bad data that doesn't trip alarms but quietly poisons every downstream analysis. Reliability is treated as a gate enforced by statistical validation. Data doesn't move forward until it's been proven fit for use. Profile the data. Run quality checks. Detect distribution shifts and pattern breaks before anyone makes a decision based on corrupt inputs.
Anomalo operates on this foundation.
A quality check flags duplicate records in a customer revenue table. The platform halts data flow. A data engineer investigates, finds the deduplication logic broke in last week's deploy, fixes it, and reruns validation. Green light. Only then does the data get promoted to production.
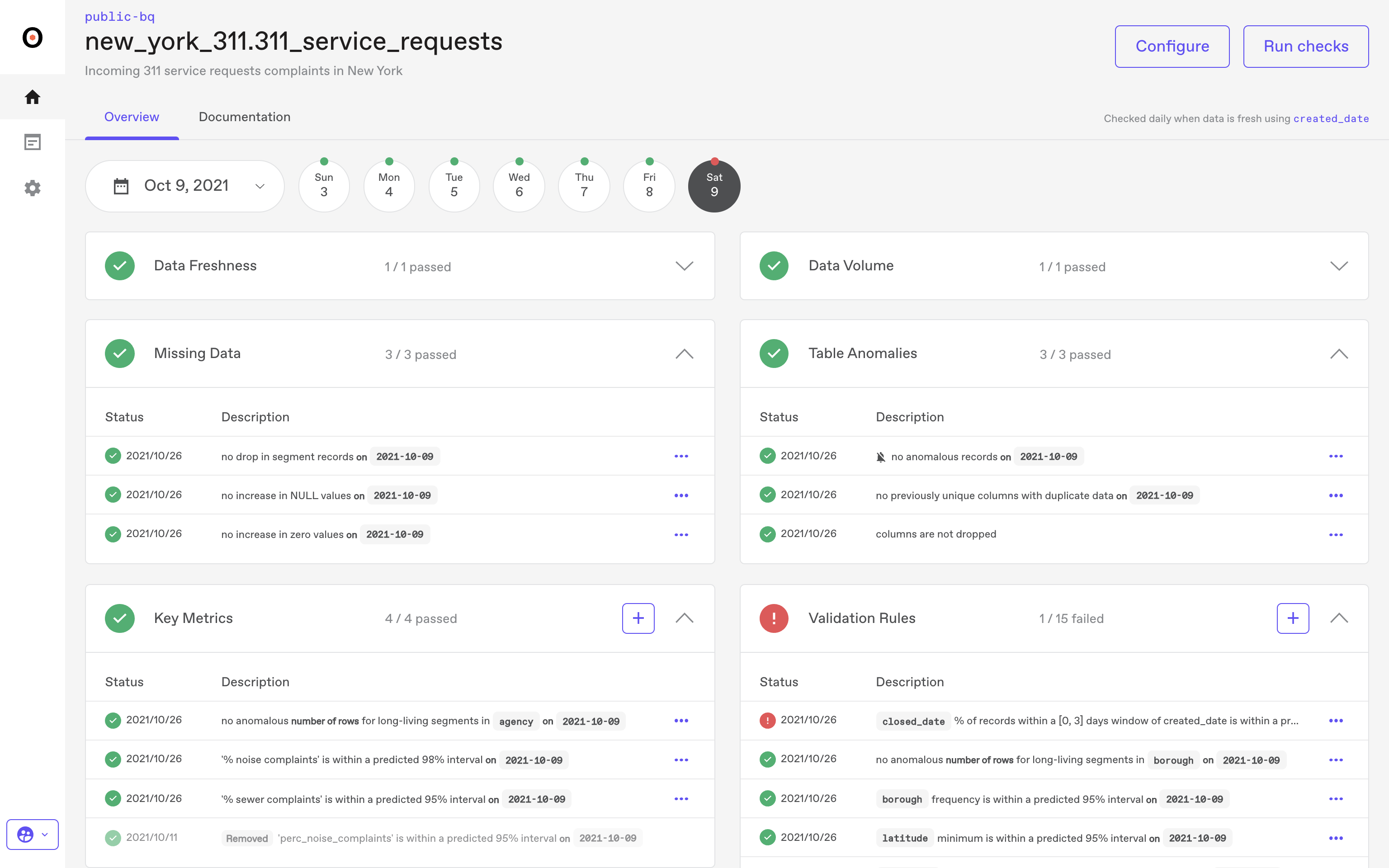
This creates a different organizational rhythm. Data teams build certification gates. Datasets don't reach BI until they pass validation.
Models don't train on data that hasn't been profiled. Reliability becomes a checklist: null rates, distribution stats, schema conformance, and relationship integrity.
People ask, "Has this been validated?" before using data. The business learns that data quality is measurable, that reliability isn't just about uptime or system performance, it's about correctness you can prove with statistical checks.
Validation without impact
But here's where statistical validation hits its ceiling. A check can confirm the data is technically correct without telling you whether it matters.
For instance, a staging table fails validation every Monday morning due to quirks in weekend batch processing. The data team spends two hours each week investigating only to discover it's a table that feeds a dashboard no one has looked at in six months. The validation was correct. The effort was wasted.
This is where validation without business context becomes a compliance exercise. You're measuring data quality without necessarily building trust in the decisions made.
The data passes the test. The business still can't move with confidence.
Business Context and End-to-End Observability is Data Trust
"Operational Certainty is the New Standard"
Business and technical context (impact mapping, ownership, end-to-end visibility) establishes the basis for reliability.
Trust is delivered by mapping technical signals to business outcomes across the entire data stack, showing what changed, what it affected, who owns it, and how to prevent recurrence.
Trust isn't just technical; it's cross-functional. It doesn't live in one isolated layer of the infrastructure.
The fundamental question shifts from whether a pipeline succeeded to whether it has provided the certainty required for the business to move forward. It's the difference between a data team that reports on the past and one that fuels the present.
Sifflet Data Observability built its platform on this foundation.
Where other platforms stop at technical signals, system metrics, or statistical validation, Sifflet connects the entire data lifecycle to business impact.
The platform treats metadata as authoritative across the full stack, from source to consumption, and uses it to answer the questions that matter most to decision-makers.
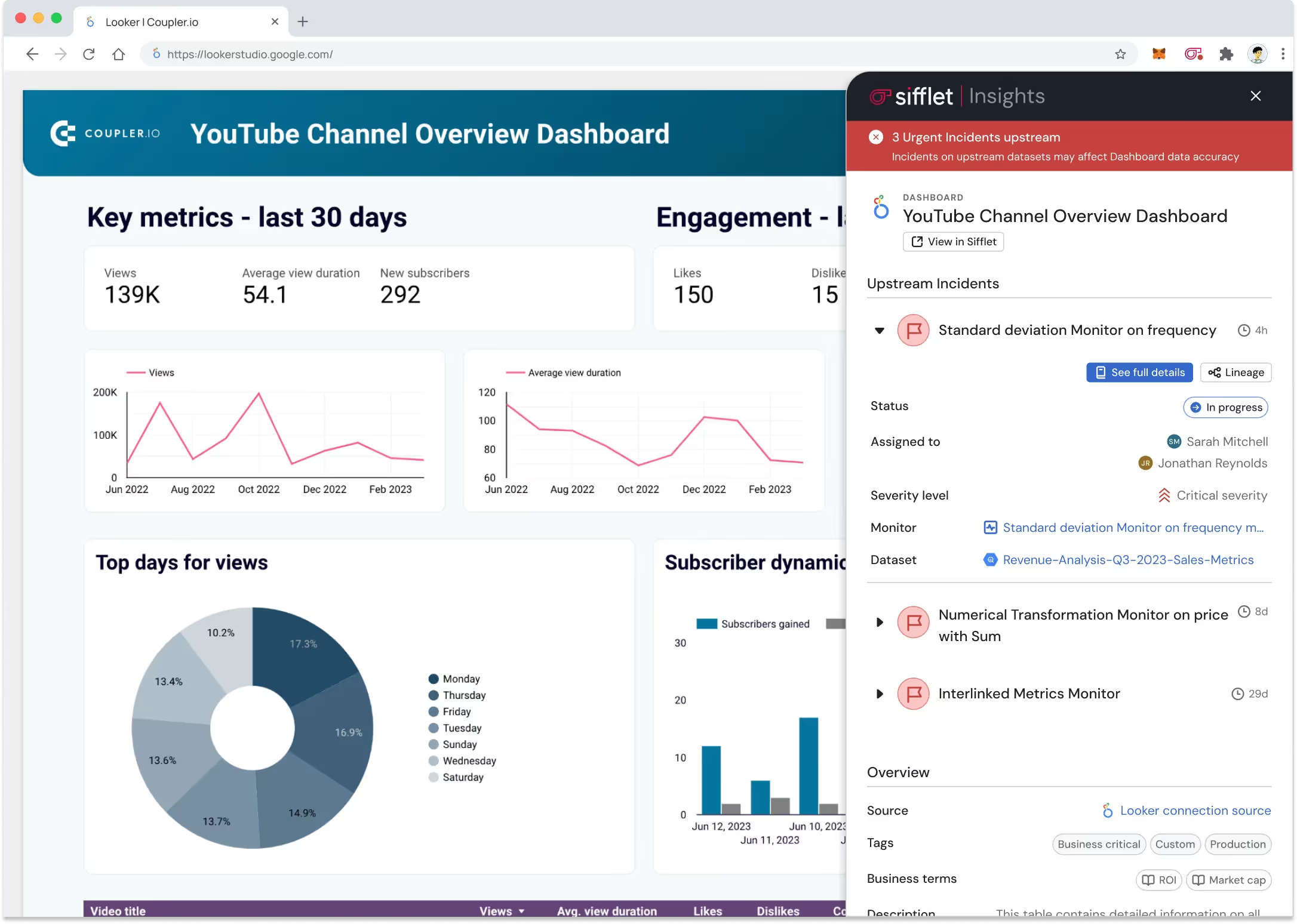
When a revenue metric drops 15% overnight, Sifflet doesn't just flag the anomaly.
It traces the shift through the complete data lifecycle to a schema change in an upstream staging table, identifies the three specific sales dashboards affected, maps the impact to the teams relying on those dashboards, surfaces the exact pipeline owner, and provides the context needed to decide whether to rollback, patch, or accept the change.
Injecting Confidence into Every Operation
This approach fundamentally changes what's possible.
Anomalies aren't just technical flags, they're business risks surfaced with enough context to act immediately. Metrics aren't just monitored for uptime; they're connected to the decisions they inform and the people who make them.
Sifflet creates a culture where the confidence gap disappears:
- Marketing launches high-spend campaigns without double-checking their segmentation logic.
- Logistics authorizes million-dollar purchase orders because they know the inventory feeds are verified.
- Finance closes the books faster because they aren't manually reconciling data ghosts.
The Vocabulary of Outcomes
Success means every employee can act with conviction. Daily standups shift from reviewing what broke to discussing what mattered and who's handling it. The business learns to expect context rather than noise. The organization's vocabulary shifts from technical throughput to business outcomes.
Sifflet makes this possible by operating at a level other platforms don't reach: end-to-end visibility combined with business-aware observability.
It works when people need more than confirmation that a bug is fixed, they need to know that the foundation of their next decision is secure.
This is how Sifflet transforms observability from a burden on the data team into the engine that fuels every corner of the business.
The Signal That Defines Trust
Four approaches. Four foundations. Four versions of what data trust actually means.
One builds trust on technical indicators, catching anomalies before the business notices.
Another builds trust in system reliability by keeping infrastructure predictable through automation.
A third builds trust in data quality standards by validating correctness before promotion.
The fourth builds trust on business and technical context, connecting problems to impact across the entire data stack.
None of these approaches is wrong. But they're not interchangeable.
The tool you choose decides what your enterprise relies on to build trust. It shapes what your data team optimizes for. It determines how people ask questions. It defines what is celebrated as success and what is flagged as failure.
Trust Your Data with Sifflet
If your trust problem isn't just about catching incidents, running reliable pipelines, or validating schemas (if it's about enabling confident decisions across the business), Sifflet is built on business and technical context with end-to-end observability.
We treat metadata as authoritative across the entire data platform.
We connect technical signals to business impact. We don't just tell you what broke. We tell you what it affected, why it happened, who owns it, and how to prevent it from happening again.
We bridge data teams and business stakeholders with the context that turns observability into decision confidence.
Because trust is an organizational capability. The platform you choose today will decide how your company makes decisions tomorrow. Choose the foundation that turns observability into your most defensible strategic advantage.















-p-500.png)
