




If your stack is a museum of unlabeled data artifacts, you're in good company.
Most enterprises have their own version of the Louvre. Minus the labels, the curators, or the €6 audio guide that explains what the heck you're looking at.
If you want to tell the difference between customers_cleaned_final and customers_cleaned_final_FINAL, you need a metadata management platform.
This guide reviews five of the best metadata management tools for 2026: what they deliver, who they best fit, and how they'll help you hang labels in your own data Louvre.
How Metadata Management Works
Metadata management is the process of collecting, organizing, and maintaining metadata; the informative connective tissue that turns fields and tables into data people can find, understand, and trust.
The concept is simple, even if the mechanics aren't.
The symptoms appear long before anyone says, "We need metadata management."
- Analysts and BI teams spend hours searching for and vetting the data they need.
- Departments report conflicting numbers for the same metric because each draws from different datasets.
- Documentation lives in scattered spreadsheets, email, and word of mouth.
These are complex problems to resolve by hand. The stack changes too quickly. And frankly, no one ever finds the time despite their good intentions.
That's why metadata management tools, particularly data catalogs, have become all but standard practice.
Metadata Management 101
Good tools remove friction. Great tools automate the entire process.
For metadata management, it looks something like this:
- Metadata Collection
Everything begins with extraction. Tools connect to your databases, warehouses, lakes, pipelines, and BI systems and pull in the raw technical and operational metadata.
- Curation
Once gathered, the catalog brings order to the metadata. It groups related assets, maps their connections, records who owns them, and anchors everything to the proper business domain.
- Enrichment
Next, the tool adds rich context. Glossary terms, classifications, tags, and AI-generated descriptions translate technical detail into language people can use.
- Governance
After enrichment, the tool applies control. Policies define who owns a dataset, who can access it, how quality is measured, and what approval workflows apply.
- Utilization
Finally, the tool activates the metadata. It collects usage signals and operational patterns, then uses this information to drive lineage, impact analysis, quality checks, and automation.
Taken together, these steps form modern metadata management. And metadata is having its moment.
As a result, a wave of newer metadata management tools has emerged, offering automation and AI capabilities that are completely changing the game.
Must-Have Features in Metadata Management Tools
The best metadata platforms share a common set of capabilities. These are the ones that matter most:
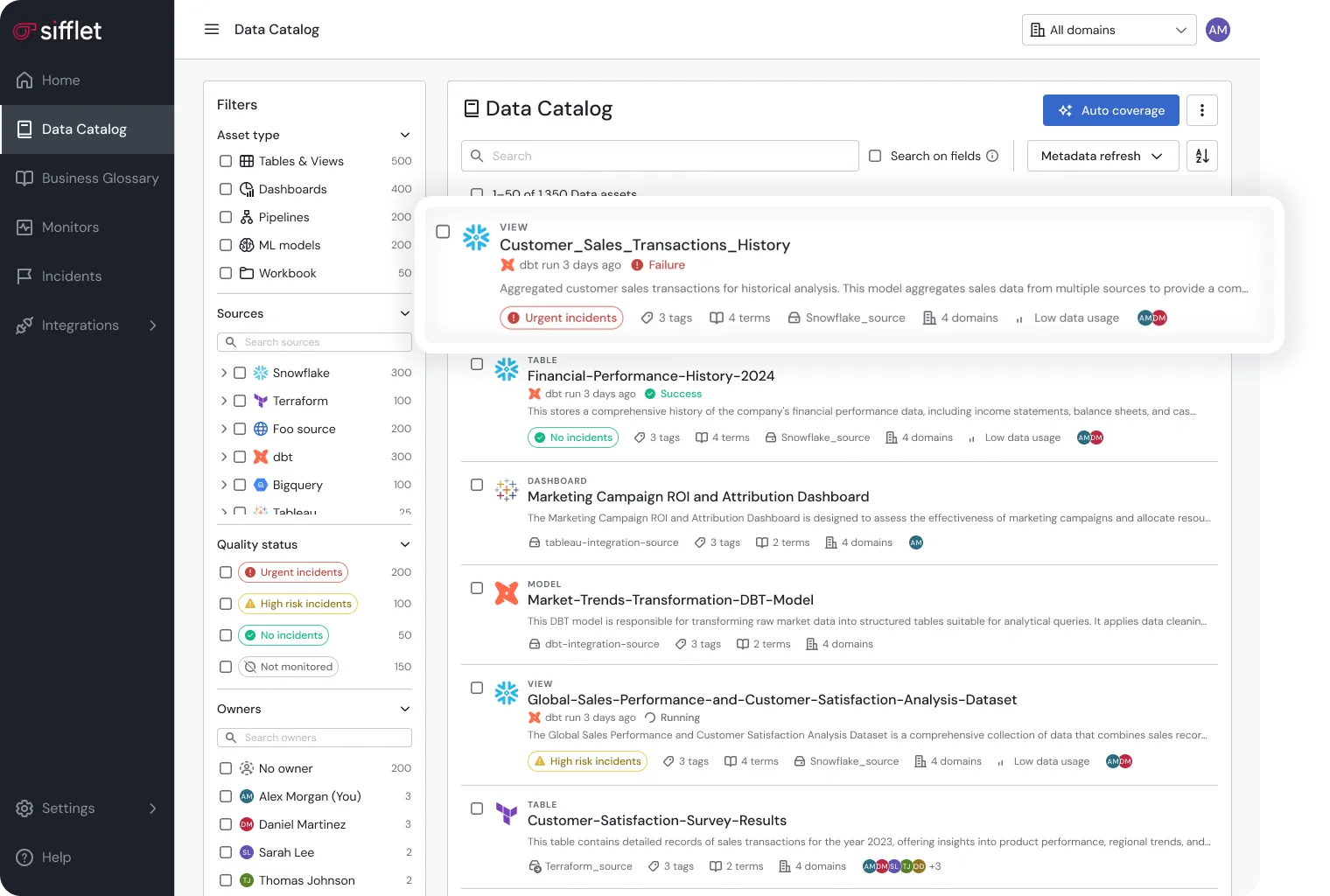
1. Data Catalog (the metadata workspace)
The data catalog is the workspace where people explore and make sense of data. It organizes assets, connects them to business meaning, maps relationships, and highlights profiling results.
With definitions, ownership, and documentation displayed in context, users can immediately judge whether a dataset meets their needs.
2. Metadata Ingestion and Translation
A metadata platform needs a strong engine to power the catalog. It must pull metadata in from every connected system and shape it into something people can actually use.
Ingestion collects raw technical metadata from warehouses, lakes, pipelines, BI tools, and applications. It standardizes schemas, normalizes formats, and keeps the catalog up to date in a constantly changing environment.
Translation turns that raw system output into usable context.
The platform expands cryptic field names, suggests classifications, generates descriptions, and links assets to glossary terms so users can interpret what they find.
3. Broad Connector Coverage
A metadata platform has to reach into every part of the data ecosystem.
Enterprises expect their catalogs to integrate with dozens of sources across cloud, on-premises, and hybrid environments. That is accomplished via native connectors and open APIs.
The wider the connector coverage, the more complete and reliable the catalog becomes.
4. Business Glossary
A glossary defines terms, metrics, and concepts with clear ownership and links those definitions directly to the data assets they describe.
The best glossaries include approval workflows, version history, and audit trails.
And paired with the catalog, the glossary is the authoritative source of approved terminology for both technical and business teams.
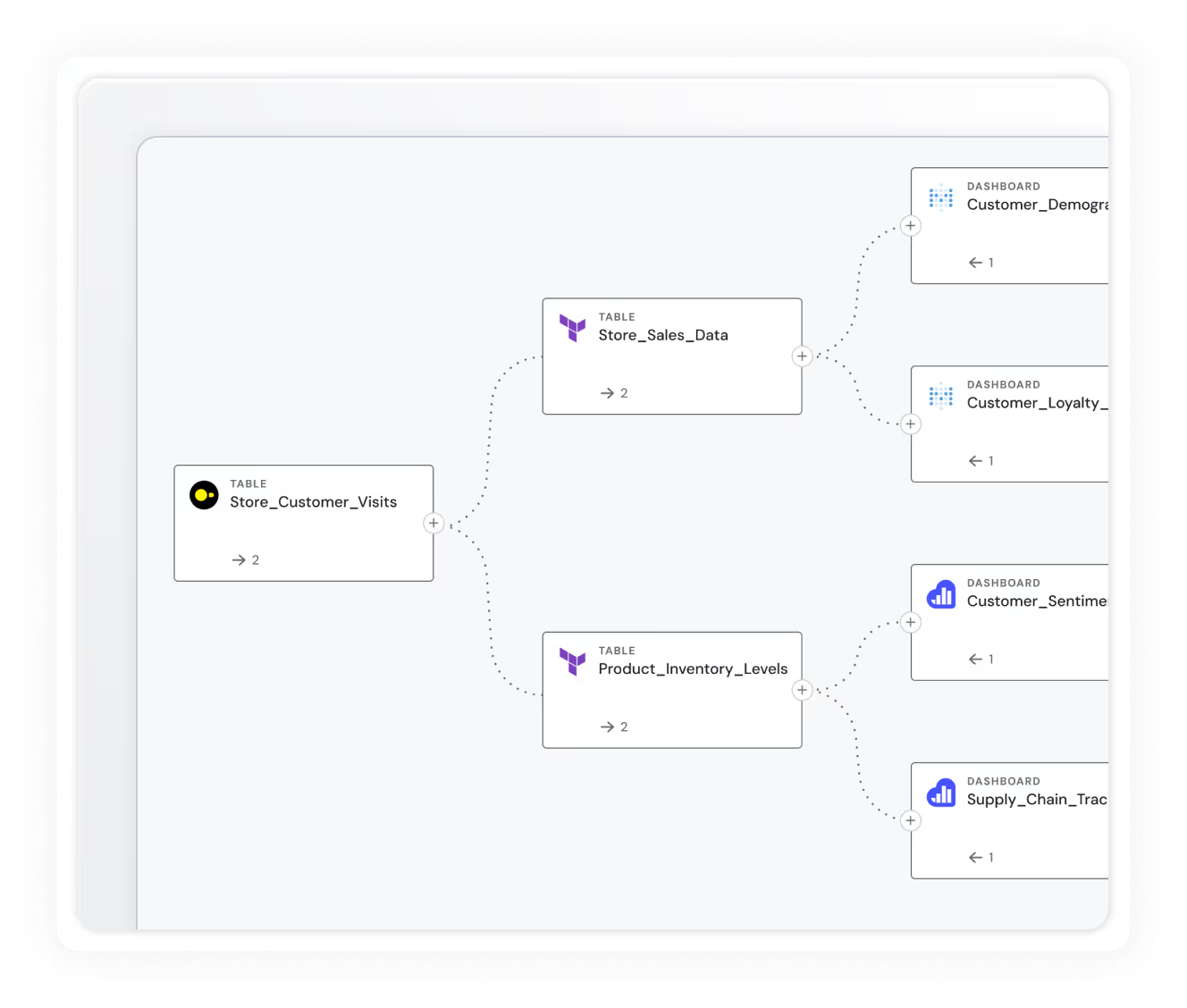
5. Data Lineage
Lineage shows how data moves from source to report.
Modern tools capture transformations and dependencies at both table and column levels.
Visual lineage diagrams map these flows, aiding in tracing issues, evaluating downstream impact, and understanding how changes propagate across pipelines and dashboards.
6. Data Profiling
Profiling evaluates data structure and quality by examining distributions, patterns, anomalies, and completeness. With results flowing directly into the catalog, consumers can gauge data quality at a glance.
Each of these capabilities keeps metadata fresh and functional, but they don't solve the question of data reliability itself. For that, you need observability.
Sifflet: A Must-Have With Any Data Catalog
A data catalog helps you find assets. But knowing where data lives is only half the story.
Is the data reliable? Accurate? Or ready for business?
That's the trust gap Sifflet data observability fills with these 3 factors:
Sifflet monitors live data for drift, stale records, freshness gaps, and anomalies.
With Sifflet, every dataset in the catalog carries a visible trust score based on live monitoring, giving analysts and business users confidence in the data they rely on.
Sifflet's AI-native platform turns lineage, usage statistics, ownership, and quality signals into clear operational insight.
That converts static documentation into a living record that reflects how data behaves, transforms, and is consumed across your environment.
3. Embedded Intelligence
Sifflet delivers quality, ownership, and lineage context directly in the tools teams already use: BI tools, dashboards, and browser extensions. That eliminates context-switching by embedding data trust at the point of decision.
Pairing Sifflet with your data catalog delivers discoverability and reliability. Your data becomes searchable, trustworthy, auditable, and AI-ready any time you need it.
With reliability solved, the choice of catalog becomes the next critical mission.
Top Metadata Management Tools
Several platforms stand out in 2026 for their maturity, integration coverage, and fit across different data environments.
The summaries below highlight what each vendor does best and where they're most effective.
IBM Watson Knowledge Catalog
Rating: ⭐⭐⭐⭐
Gartner 4.5/5
Overview
IBM Watson Knowledge Catalog treats governance as a core discipline. It brings
structure to large, mixed environments where metadata must be reliable, enforceable, and audit-ready.
Automated discovery, AI-assisted classification, and foundation-model enrichment standardize metadata at scale.
The platform flags sensitive fields early, applies policies with precision, and routes stewardship tasks through workflows that make ownership clear.
Few tools match IBM's strength in policy enforcement or AI-driven classification. For organizations that need governance to work predictably at scale, Watson Knowledge Catalog provides a disciplined, durable foundation.
The tradeoff is effort.
Onboarding takes time, and teams outside the IBM ecosystem often need an adjustment period. Once established, the platform delivers dependable structure and stable metadata across complex estates.

Pros
- Mature governance and compliance controls
- Strong automated classification and enrichment from IBM's AI models
- Ideal for teams already invested in IBM's data stack
- Broad coverage across technical, business, and operational metadata
Cons
- High cost and heavy infrastructure footprint
- Steep learning curve
- Best results inside the IBM ecosystem
- Some users report delays tied to authorization and access workflows
Atlan
Rating: ⭐⭐⭐⭐
G2 4.5/5 | Capterra 4.5/5
Overview
Atlan takes a true active metadata approach. It continuously harvests, enriches, and synchronizes metadata from cloud warehouses, transformation frameworks, and BI platforms.
Deep technical lineage sits alongside workflow-driven collaboration, giving teams context exactly where decisions happen. The result is a metadata layer that stays current as pipelines shift and assets evolve.
Atlan is easy to adopt. The interface feels natural for both technical staff and business partners, and near-real-time updates keep lineage and asset context accurate without manual cleanup.
Collaboration features capture knowledge in the flow of work, reducing the drift that typically appears in fast-growing environments.
Larger organizations may need to tune permissions, and mastering the full automation stack takes time, but everyday use remains smooth even as the footprint expands.
A polished UI, strong integrations across the modern data stack, and mature active-metadata capabilities give Atlan a clear identity.
It fits fast-moving teams that want automation, context, and collaboration in one place. It also suits cloud-native environments where shared understanding and high adoption matter as much as technical depth.
Atlan delivers a unified experience that balances scale with usability.
Pros
- Standout user experience that drives adoption
- Strong native integrations
- High-quality column-level lineage that's easy to navigate and operationalize
- Fast release cadence supported by responsive customer teams
- Open, API-first architecture that plays well with engineering workflows
Cons
- Permissioning can be complex in larger, multi-domain environments
- Pricing may be out of reach for smaller or early-stage teams
- The breadth of features introduces a learning curve for new users
- Rapid releases occasionally introduce minor stability issues
- Some non-native systems require additional configuration or tuning
Dataedo
Rating: ⭐⭐⭐⭐⭐
G2 5/5 | Capterra 4.7/5
Overview
Dataedo targets a documentation-first approach to metadata.
Pulling structures and definitions directly from databases and warehouses, it distributes them into glossaries, ER diagrams, and documentation that people will actually use.
The platform feels approachable from the start.
Engineers can document schemas quickly, and business users can follow the logic without extra explanation. It fits SQL-heavy environments where teams want fast wins and a dependable way to keep knowledge from drifting.
Dataedo isn't designed for advanced automation or large-scale governance, and it doesn't try to be. It focuses on clarity, not complexity.
For smaller teams or departmental programs, the value shows up immediately.
Clean exports, understandable diagrams, and shared definitions help groups stay aligned as systems evolve.
If your priority is practical documentation and a common understanding of how your data is structured, Dataedo provides a focused, reliable option without the weight of an enterprise metadata suite.

Pros
- Easy for both technical and business users to pick up
- Produces clean, professional documentation with strong HTML exports
- Solid lineage and modeling for relational databases
- Responsive support with steady product improvements
- Far more affordable than heavyweight enterprise cataloging suites
Cons
- Limited coverage for cloud-native and niche modern sources
- Fewer customization options for documentation outputs
- Can slow down when working with very large schemas
- Not built for advanced governance or large, distributed data environments
Informatica Enterprise Data Catalog
Rating: ⭐⭐⭐⭐
G2 4.3/5 | Capterra 4.3/5
Overview
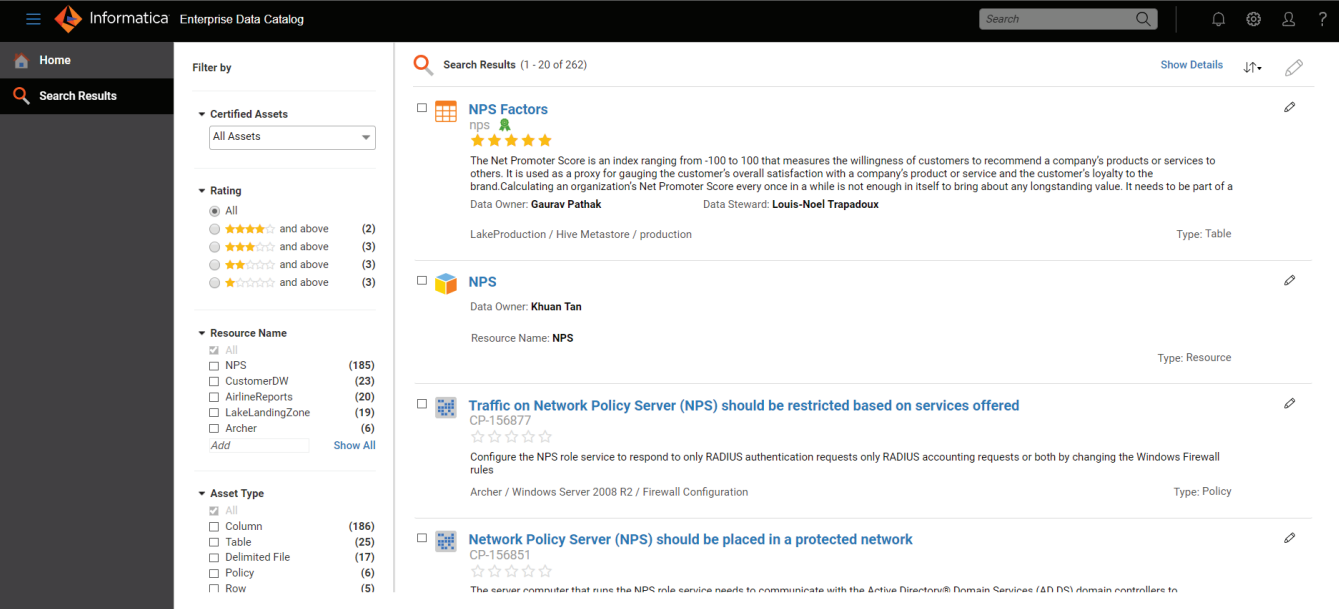
Informatica EDC takes an integration-first, technically rich approach to metadata. AI-driven scanners, a graph-based metadata core, and automated lineage work together to map information across cloud, hybrid, and on-premises systems.
This is perfect for organizations with long, complex data histories and a mandate to govern them.
Coverage is a core strength. CLAIRE AI classifies assets across sprawling environments, decoding relationships that large enterprises struggle to identify.
The learning curve is meaningful, and setup requires committed data teams, but the payoff is stable governance and dependable visibility across systems that rarely align neatly. Mature programs tend to benefit most.
EDC stands out for its scalability, depth of technical metadata, and ability to stitch lineage across both legacy and modern platforms.
It fits enterprises with hybrid or highly distributed architectures where long-term stewardship matters and governance needs to be predictable. It rewards teams willing to invest in upfront structure and ongoing ownership.
Pros
- Broadest integration footprint among enterprise catalogs across cloud, on-prem, legacy, and hybrid systems
- Mature AI capabilities for discovery, classification, relationship inference, and PII detection
- Proven ability to scale to millions of assets without losing depth
- Robust governance with strong lineage, glossary workflows, and policy management
- Deep technical metadata coverage, including stored procedures, ETL logic, and complex enterprise platforms
Cons
- High total cost of ownership and staffing requirements
- Configuration and stewardship models create a steep learning curve
- UI and navigation feel dated compared to newer cloud-native tools
- Performance and lineage depth depend heavily on upstream metadata quality
DataGalaxy
Rating: ⭐⭐⭐⭐⭐
G2 4.8/5 | Gartner 4.9/5
OVerview
DataGalaxy automates discovery, but its real strength is accessibility. Designed around people and how they actually want to work, campaign-driven governance, and a unified business glossary seat technical and business teams at the same table.
Automation supports the work, but clarity remains the priority.
The experience feels easy from the start. Onboarding is fast, the interface is clean, and real-time editing replaces scattered notes and "tribal knowledge" with crisp documentation. Campaign cleanups give organizations a structured way to improve metadata quality without slowing down day-to-day operations.
Some connectors are still maturing, but the platform's adoption and collaboration strengths more than make up the difference.
DataGalaxy shines for its focus on business alignment. Campaign-based governance, an approachable glossary, and in-workflow context, including a slick Chrome extension, make it a strong fit for mid-market companies that want collaborative ownership over their data.
It works best for organizations that value clarity and participation over heavy enterprise complexity, offering a clear path to data literacy and collaboration.

Pros
- Strong user experience that works well for non-technical roles
- Clear, intuitive business cataloging and glossary capabilities
- Fast deployment with a shorter onboarding curve than heavier enterprise platforms
- Frequent product updates and responsive support
- Collaboration features that promote shared stewardship
- Helpful browser extension that brings context directly into analysis workflows
Cons
- Some features are still maturing as the platform evolves
- Limited native data quality functionality
- Connector depth varies for some systems
- Rights management and access controls continue to develop
Choose the Best Tool to Manage Your Active Metadata
A catalog helps people find and understand data.
But it can’t tell you if the data you’re using is reliable.
That's why the best metadata management platforms pair best with Sifflet's data observability. Sifflet catches issues early, keeps pipelines healthy, and connects real system behavior to the active metadata your teams rely on.
Your catalog is accurate, your documentation is relevant, and your data reflects what's true—right now.
Activate your metadata with Sifflet. Book a demo and see how observability strengthens every asset in your data catalog.















-p-500.png)
