




Without an architect, no building would go up successfully.
The same thing happens with your data platform.
Without an effective data architecture in place, you would be handling a bunch of different software that may or may not be working well together.
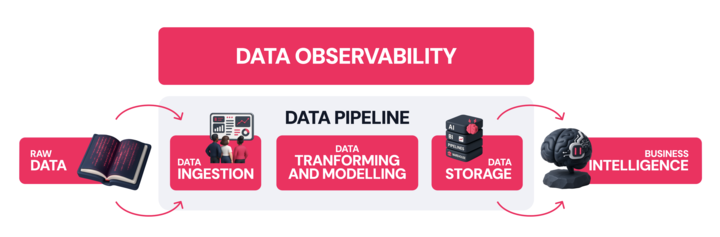
What is Data Architecture?
Data architecture is the structural logic used to connect operational systems, analytics platforms, and AI workloads into a consistent, governed environment.
It includes the standards, models, and policies that shape how data behaves as it moves and is used throughout an organization.
When designed intentionally, data architecture makes data available, consistent, secure, and trustworthy, even as systems, teams, tools, and use cases change.
On a practical level, data architecture answers 4 essential questions:
- How should data move from source to analytics, applications, and models?
- How should data be structured for both people and machines?
- Who can access which data, under what conditions, and with what controls?
- Which standards determine whether data is complete, accurate, and fit for use?
These critical questions ultimately determine whether an organization's data ecosystem functions smoothly and whether its data assets can be fully leveraged to achieve its objectives.
Data Architecture and the Data Platform
Data architecture and data platforms serve different roles but one cannot exist without the other.
The architecture defines the logic. It sets the rules for data's structure, movement, and governance.
A data platform provides the execution layer. It includes the technologies that store, process, and deliver data, such as data warehouses, data lakes, orchestration tools, and analytics engines.
When architecture and platform are aligned, data flows efficiently from ingestion to insight.
When they aren’t, the platform stops behaving as a system and starts behaving as a collection of exceptions and workarounds.
What Data Architecture Delivers
A skillfully designed data architecture streamlines everyday work even as systems become more and more complex.
In analytics, architecture provides a stable foundation for reporting. Shared data models and definitions allow teams to compare results across domains, track performance, and answer questions without reinterpreting metrics each time they're used.
For AI and machine learning, architecture creates the conditions to allow the same datasets, definitions, and preparation logic to support multiple models. AI models train on inputs with known structure and lineage, making iteration and monitoring easier as their requirements change.
Operational reporting benefits from the same clarity. Architectural paths from source systems to reports support predictable refresh cycles and reduce the need for manual intervention. Teams can rely on operational data without second-guessing its timeliness or scope.
Architecture also plays a central role in data governance and security. Defined ownership, access rules, and lineage make it possible to apply controls consistently across systems, even as new data sources and use cases are added.
Cost and performance management improve as well. When data assets are visible and structured for reuse, teams build on existing work instead of constantly recreating it. Storage and compute grow with demand, not with duplication.
These outcomes don't stem from individual tools or one-off decisions. They're the product of a data architecture that's designed with scale in mind.
Centralized vs. Decentralized Data Architecture
As data environments grow, most companies end up facing the same question: should data be managed centrally, or by the teams that use it?
There's no universal right answer.
The choice depends on the scale, complexity, and level of autonomy your business can realistically support. What matters more is understanding the trade-offs involved and designing for them intentionally.
- Centralized data architecture
In a centralized architecture, data is managed through a single, shared platform. Pipelines, storage, and governance are owned by a central data or IT team.
This model emphasizes consistency and control. The architecture standardizes data, tightly manages access, and enforces a clear change process.
Centralization works well when:
→ Domains are fewer in number and closely related
→ Reporting needs are mostly consistent across domains
→ A single team can realistically support ingestion, modeling, and access
The downside appears as the scale increases and the central team becomes an unintended bottleneck.
Domain-specific needs take longer to address, and business units wait in line for changes that feel urgent locally but less so at the enterprise level.
When everything flows through a single group, speed becomes the constraint.
- Decentralized data architecture
A decentralized architecture spreads ownership across domains. Teams closer to the data manage their own pipelines, models, and data products and are directly accountable for the results.
Decentralization increases speed and data’s relevance.
Domain teams understand their data best and can respond more quickly as business needs change. This model is common in large enterprises with diverse data sources, products, and analytics needs.
Decentralization works well when:
→ Data domains are complex and highly specialized
→ Teams have the skills and discipline to manage data responsibly
→ The enterprise values autonomy over uniformity
The risk in this model is fragmentation. Due to the lack of shared standards and close coordination, command and control may suffer. Governance, security, and compliance become difficult to enforce, posing a particular risk to sensitive and regulated data.
Without close coordination, decentralized architectures collapse into silos and sprawl.
- The hybrid approach
Realistically, most data platforms land somewhere in between.
Hybrid architectures centralize core infrastructure and standards while decentralizing data ownership. Shared, centralized platforms handle storage, security, and governance, while individual domains might own their data models, pipelines, and analytics.
These blended models seek to balance control with flexibility. Hybrid architectures work well when standards are enforced, ownership is explicit, and visibility across domains is high. When not, it risks degrading into bottlenecks, silos, and disorder.
The architecture you choose doesn't just shape data flows; it also shapes how teams work, how decisions are made, and how quickly the business can adapt.
To manage all this is the work of the data architect.
The Role of the Data Architect
The data architect is responsible for translating business intent into structural decisions. Their role sits at the intersection of strategy and execution.
A data architect establishes the rules and standards that determine how data behaves across systems, how teams interact with it, and how the platform evolves over time. That includes data models, naming conventions, ownership boundaries, access controls, and governance patterns.
The data architect also plays a coordinating role.
In centralized environments, that means balancing enterprise-wide consistency with competing domain needs. In decentralized or hybrid environments, it means enabling autonomy without allowing fragmentation. The work is as much about alignment as it is about design.
As data platforms expand to support analytics, operational use cases, and AI, the architect’s responsibility grows. They must anticipate how new tools, domains, and data products will fit into the existing structure and where standards need to evolve. Their goal is not to freeze the system in place, but to make change manageable.
When this role is absent or underpowered, architecture tends to emerge implicitly. Decisions are made locally, standards drift, and complexity accumulates.
Over time, the platform becomes harder to understand and more expensive to maintain.
A data architect injects continuity. They create a shared framework that teams can build on with confidence, even as technologies and priorities shift. In doing so, they help turn data architecture from a one-time design exercise into an ongoing capability.
The Components of Data Architecture
Modern data architecture is made up of distinct functional components that work together to move, store, govern, and activate data. While the tools may change over time, these core components remain consistent across most enterprise data environments.
Rather than treating them as isolated systems, effective architectures organize these components by function and define how they interact.
Flow and Integration
Flow and integration components determine how data enters the platform and moves between systems.
They define the paths data follows from source systems to downstream consumers and influence latency, reliability, and flexibility as new sources or use cases are introduced.
Key components include:
- APIs and connectors, which enable systems to exchange data directly and support event-driven or near-real-time integrations
- Data pipelines, which handle ingestion, transformation, and movement of data
Storage and Persistence
Storage components determine where data lives, how long it’s retained, and how it can be accessed over time.
Different storage systems serve different purposes, balancing performance, cost, structure, and governance requirements.
Common storage components include:
- Databases, which support transactional systems and operational workloads
- Data warehouses, optimized for structured analytics and reporting
- Data marts, tailored subsets of warehouse data designed for specific domains or teams
- Data lakes, which store large volumes of raw or semi-structured data
- Data lakehouses, which combine elements of lakes and warehouses to support multiple workloads on shared data
Modern data architectures increasingly favor zero-copy or virtualized access patterns.
Rather than physically duplicating large datasets across multiple systems, storage layers are designed to allow different engines (analytics, finance, AI) to read the same data in place.
This approach reduces redundant processing and minimizes the risk of multiple versions of the same data drifting out of alignment.
By relying on shared storage and open table formats, architectures support reuse without sacrificing performance or governance. Data remains centralized at rest, while access remains flexible at runtime.
Access and Consumption
Access and consumption components define how people and systems interact with data. They translate stored data into insights, metrics, and signals that support decision-making across the organization.
These components include:
- Dashboards and analytics tools, used for reporting and exploratory analysis
- Query and compute engines, which process data at scale using SQL or programmatic workloads
- Embedded data products, where data is delivered directly within business applications rather than through standalone tools
AI and Advanced Analytics
As AI becomes a core consumer of enterprise data, architectures increasingly include components dedicated to model development and deployment.
These components support the preparation, training, and evaluation of models that rely on large volumes of well-structured data.
We refer to:
- AI and machine learning training systems, which consume curated datasets to build predictive models and generative applications
Governance and Intelligence
Governance components provide visibility, control, and context across the entire data architecture. They don’t sit outside the system. They operate alongside other components to make data understandable, auditable, and trustworthy as it moves and changes.
Core governance components include:
- Metadata management, which captures definitions, ownership, and usage context
- Lineage and observability, which track how data flows through the system and how changes affect downstream consumers
- Data catalogs, which help users discover, understand, and assess available data assets
Together, these components form the structural backbone of a data architecture.
How they’re selected, combined, and governed determines whether a data platform remains coherent as it scales, or gradually becomes harder to operate and evolve.
How to Plan Your Data Architecture
Planning a data architecture is less about selecting technologies and more about making a small number of foundational decisions first. Those decisions shape how flexible, reliable, and sustainable the system will be over time.
The goal at this stage isn’t completeness; it’s coherence. A thoughtfully planned architecture sets clear priorities and definite constraints so that future choices won’t conflict with past decisions.
- Clarify the purpose of the architecture
Every data architecture exists to serve a distinct set of business outcomes. Planning begins by identifying what the architecture needs to support today and what it must remain capable of supporting tomorrow.
Some environments prioritize reporting consistency and financial controls. Others emphasize rapid experimentation, real-time decisions, or AI-driven products. Most need to balance several of these at once.
Being explicit about primary use cases helps avoid overbuilding in one area while underinvesting in another.
- Decide where speed matters
Different use cases place different demands on latency.
Some workflows benefit from near-real-time data movement, such as operational monitoring or automated decisioning. Others are better served by batch processing, where cost efficiency and historical depth matter more than immediacy.
Planning the architecture means deciding where real-time capabilities are required, where they are optional, and where they add unnecessary complexity.
- Define ownership and accountability
Architecture decisions should reflect how accountability is distributed across the organization.
In centralized models, a small group controls most data decisions. In decentralized or hybrid models, responsibility is shared across domains. Planning requires clarity on who owns which data assets, who defines standards, and who resolves conflicts when priorities inevitably collide.
Without explicit ownership, architectural rules tend to weaken over time, even if they’re well-designed initially.
- Establish structural standards early
Standards are easier to establish early than to retrofit later.
This includes decisions around data modeling conventions, naming patterns, access controls, and lifecycle expectations. These standards don’t need to be exhaustive, but they do need to be enforceable.
The objective is not to unnecessarily restrict teams, but to provide a shared framework that supports reuse and consistency as the system grows.
- Plan for change, not stability
Finally, planning should assume change as the default condition.
New data sources will appear. Tools will be replaced. Teams will reorganize. A resilient architecture anticipates this by favoring loose coupling, clear interfaces, and shared definitions over tightly bound implementations.
An architecture that plans for evolution is easier to extend, easier to govern, and less likely to accumulate friction over time.
How to Implement Your Data Architecture
Implementing a data architecture is a sequence of decisions applied in the right order. When the sequence is wrong, teams end up compensating later with rework, patches, and exceptions.
The most effective implementations move from logic to execution, not the other way around.
Step 1: Establish Shared Definitions and Semantics
Implementation begins with agreement on meaning.
Before pipelines are built or platforms are configured, the enterprise needs a shared understanding of core concepts such as customers, products, transactions, and events. These definitions form the semantic foundation on which everything else depends.
Skip this step, and technical progress will look fast while structural consistency quietly erodes.
Step 2: Define the Core Data Structures
Once definitions are clear, those concepts need to be reflected in data models.
This step involves deciding how data will be structured, how granular it should be, and how different domains relate to one another. The goal is not to model everything up front, but to establish patterns that new datasets can follow as they’re introduced.
Clear structural patterns reduce friction as the platform grows.
Step 3: Design Data Flows and Interfaces
With structure in place, attention shifts to movement.
This step defines how data enters the system, how it’s transformed, and how it’s made available downstream. Interfaces between systems should be explicit and stable, even if the underlying tools change over time.
Well-defined data flows make the system easier to reason about and easier to adapt.
Step 4: Integrate Governance into the Architecture
Governance works best when it’s embedded into the system rather than layered on later.
At this stage, ownership rules, access controls, and lifecycle expectations are connected directly to data assets and flows. These controls should align with how
people actually work, not as policies written in isolation.
When governance is integrated early, it scales more naturally as usage expands.
Step 5: Enable Access and Ongoing Evolution
The final step focuses on use and change.
Data must be accessible to the people and systems that rely on it, with enough context to support correct interpretation. At the same time, the architecture must remain flexible as new requirements emerge.
Implementation doesn’t end here, however. This step also inserts the feedback loop that allows the architecture to evolve without losing coherence.
Data Observability and Your Data Architecture
Data architecture isn’t static or inert. As new data sources are added, pipelines change, and usage grows, architectural intent can drift.
Observability is what keeps that intent visible and enforceable over time.
Data observability provides continuous insight into how data is behaving across the architecture. It monitors quality, freshness, volume, and structure as data moves through systems, and it surfaces issues in context rather than in isolation.
Instead of reacting to broken dashboards or downstream complaints, teams can see problems as they emerge and understand their impact.
Observability acts as a feedback loop. It shows where data flows as expected, where assumptions no longer hold, and where standards may need to be adjusted. This visibility helps architects and platform teams refine models, update rules, and adapt governance without waiting for things to break first.
Observability also strengthens accountability. By tying data issues back to specific pipelines, datasets, and owners, it becomes easier to coordinate fixes and prevent recurring problems. Architectural decisions stop being theoretical and start being measurable.
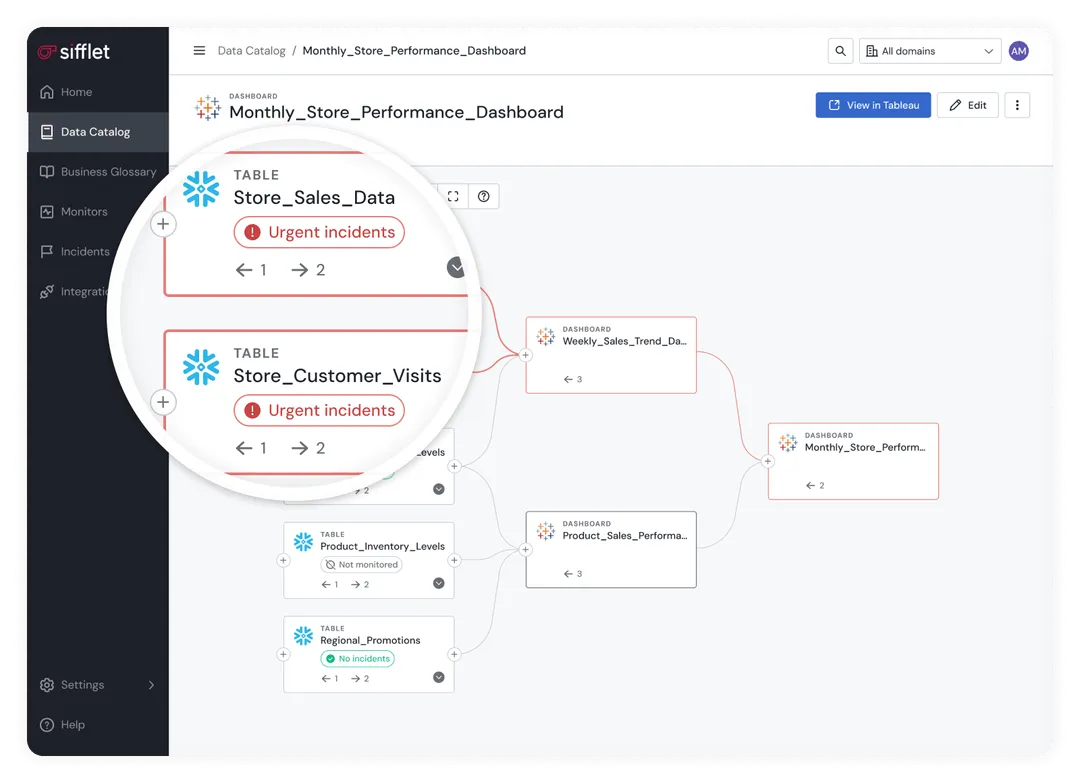
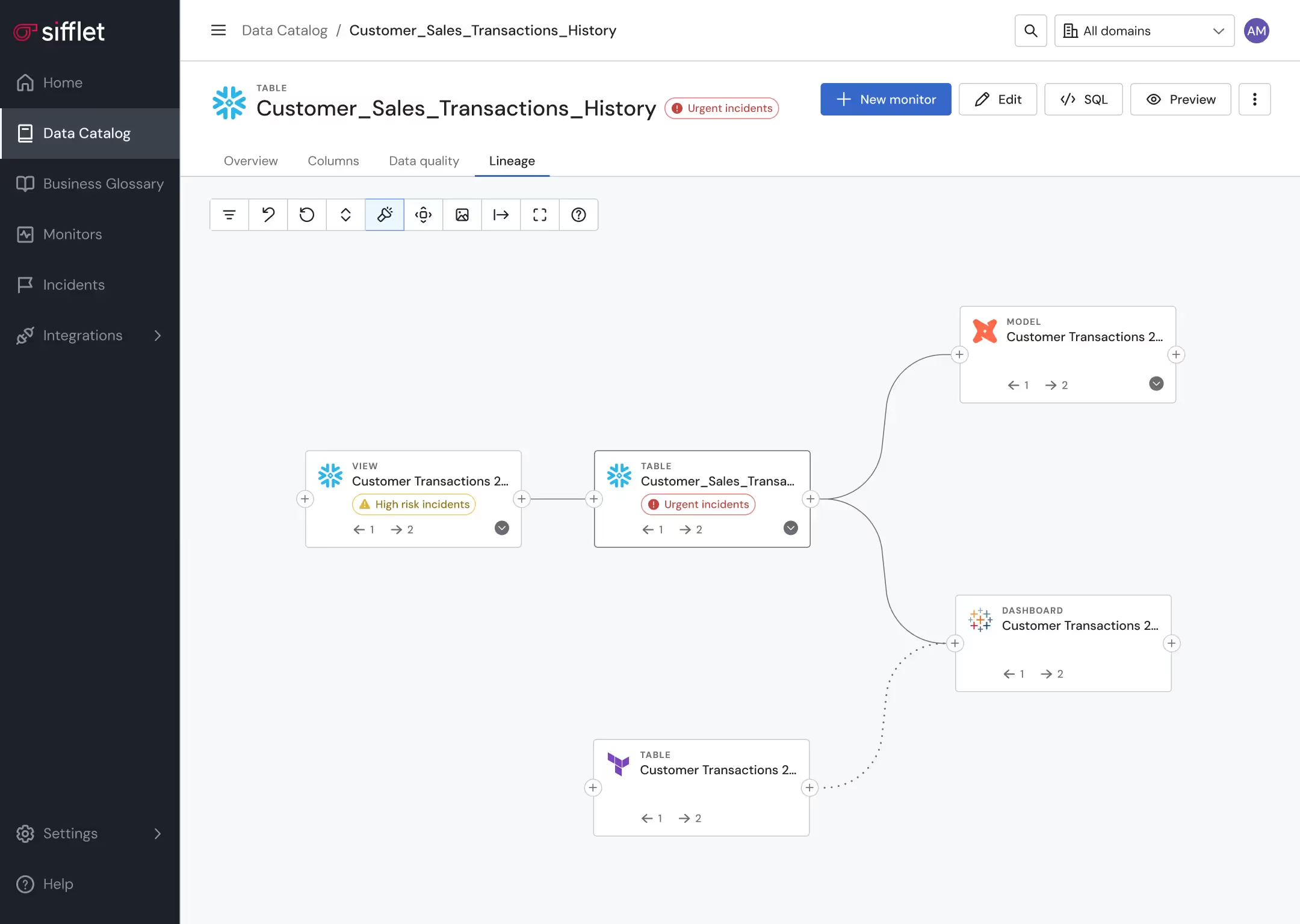
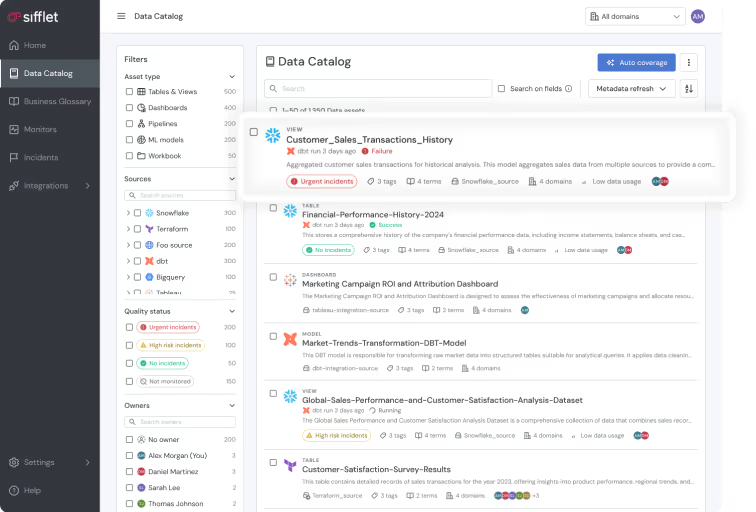
Platforms like Sifflet’s Data Observability play a strong role in support of healthy systems.
Sifflet integrates directly into the data architecture to provide real-time visibility across data pipelines, storage systems, and consumption layers. Its metadata-driven approach connects observability signals to business context, making it easier to understand not just what broke, but why it matters.
Because Sifflet operates on metadata collected directly from warehouses, lakes, and pipelines, observability becomes a simplifying layer rather than another system to manage.
Sifflet’s three dedicated AI agents further support system health and data reliability as:
- Sentinel detects anomalies across freshness, schema, volume, and values
- Sage analyzes root causes and traces downstream impact
- Forge guides remediation by suggesting corrective actions and workflow steps
Together, these capabilities help teams maintain architectural integrity as systems scale. Observability becomes part of how the architecture operates, not an afterthought added once problems appear.
A strong data architecture sets the structure. Observability keeps that structure honest as the environment changes. When the two work together, data remains usable, trustworthy, and aligned with how the business actually operates.
Building a Data Architecture With Observability
Data architecture isn’t about chasing the right tools or locking in a perfect design. It’s about creating a structure that can adapt to growth without breaking down.
When architecture is intentional, teams move faster without losing control. Data stays understandable as it spreads across systems. New use cases build on what already exists instead of starting from scratch.
That’s the real test of a data architecture.
If you’re evaluating how well your current architecture is holding up, data observability is the place to start.
See how Sifflet helps teams maintain trust, visibility, and control across modern data platforms, especially as they scale.














-p-500.png)
