




In 2026 your metadata is your new primary point of failure.
The "brain" of the data warehouse used to be a proprietary secret, locked deep inside a vendor's black box. It managed everything from file layouts to schema enforcement to transaction logs.
But it did so out of sight and out of reach.
In the Open Data Stack, the brain has moved.
It now lives in an open metadata layer where the catalog acts as the definitive map, pointing multiple engines to the specific snapshot that represents the current state of truth.
If you aren't observing the specific metadata structures that define your tables, you aren't just "decoupled," you’re flying blind.
Metadata As The New Control Plane for Data Lakehouses
In a traditional warehouse configuration, the system manages everything: file layouts, schema enforcement. It's all there under the hood.
But in an open lakehouse, the Open Table Format acts as the logical management layer, using metadata artifacts to track and enforce state:
- Apache Iceberg uses a hierarchical tree of manifest lists and metadata files to track immutable snapshots and enable hidden partitioning.
- Delta Lake relies on a centralized, ordered transaction log to maintain strict ACID compliance across concurrent writers.
- Apache Hudi utilizes a timeline of 'instants' and file-group properties to manage the complexities of upserts and incremental processing.
Separating storage from compute de facto crowns metadata as the new source of truth, but it cuts both ways.
Metadata also becomes the critical fault line where engine misconfigurations, connector incompatibility, and catalog drift quietly disrupt your entire stack.
Metadata Complexity in an Open Data Architecture
Flexibility opens the door to this complexity. In an open lakehouse, you replace vendor control with "best-of-breed" flexibility, but that same flexibility requires you to become the system administrator for the data itself.
Open Table Formats aren't fragile, but they still require active management. As multiple engines read and write to the same table, several metadata-driven challenges emerge:
1. Multi-Engine Schema Incompatibility
Open Table Formats like Iceberg allow you to change table structures on the fly. Yet, in this new world of Open Data Architecture, Open doesn't necessarily mean Universal.
A Spark job might successfully update a table, but if your BI tool uses an older connector, it might not recognize the change. This creates a metadata interpretation problem: the data is fine, but your tools are speaking two different versions of the same language.
2. Maintenance and Metadata Bloat
Open formats still require digital housekeeping.
If Snapshot history isn't cleaned up, the metadata files will bloat. This forces query engines to spend more money reading the map than actually visiting the destination.
The result is a regression to the same old problems the Lakehouse was meant to solve: slow performance and skyrocketing cloud costs.
3. Catalog–Table State Drift
In most enterprise stacks, table formats rely on a catalog such as AWS Glue, Unity Catalog, or Polaris, to act as the official registry.
If the handshake between the physical metadata files in S3 and the catalog's logical pointer fails, catalog drift sets in. It creates 'ghost data' where new records are physically present in storage but invisible to the engine. Or, tables are filtered out entirely due to stale governance and permission manifests.
What does this look like in practice?
Cross-Engine Interpretation
An engineering team uses Spark to add data to an Apache Iceberg table. On their end, everything looks perfect: the data is written to S3, the job finishes, and the pipeline reports "Success."
However, an executive’s Trino-powered BI dashboard fails. While Spark successfully updated the table's instruction manual and metadata, the Trino engine is using an older dictionary and no longer understands how to read the updated table.
Traditional observability tools miss this because they only check if the "writer" (Spark) finished its job. They’re looking at the process, not the state.
A metadata-driven platform immediately spots this interpretation drift. It recognizes that the table has moved to a version that its downstream readers can't yet support. It flags the conflict at the management layer, long before the CEO encounters a cryptic "column not found" error.
Why Observability Must Become Metadata-First
To stabilize an Open Data Architecture, observability can’t be a passive post-script at the end of a pipeline. It must become an active metadata control plane.
It must serve as the system's source of truth for state, continuously reconciling the actual table metadata in storage against the intended schemas and governance contracts in the catalog.
By monitoring atomic commits in real time across all engines, 'best-of-breed' flexibility doesn’t end in fragmentation.
Sifflet: The Intelligent Control Plane for the Open Data Architecture
Sifflet provides the active metadata layer needed to manage the complexity of Iceberg, Delta, and Hudi. It’s the central point of reconciliation for the modern lakehouse:
- Cross-engine lineage and impact analysis
Sifflet’s data lineage tracks how data flows through your engines, whether Snowflake, Databricks, or Trino interacting with your Open Table Formats.
It lets you see exactly which dashboards, KPIs, or AI models depend on a changing table before a breakage occurs.
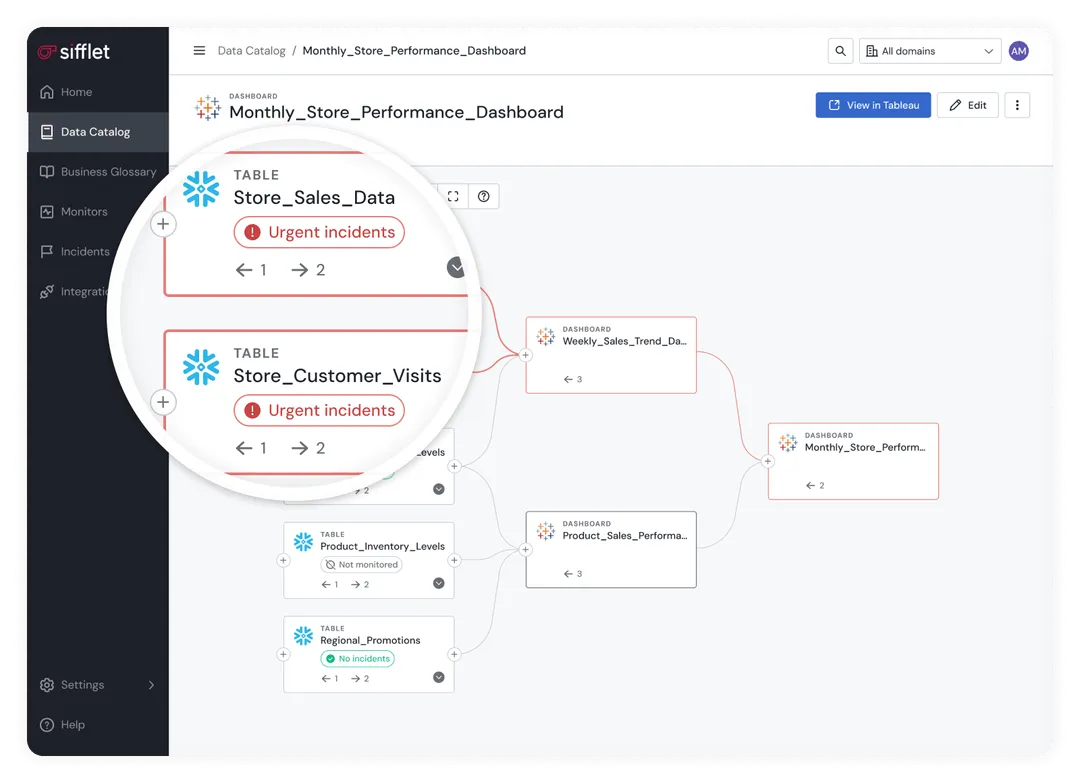
- Continuous metadata harvesting
Sifflet monitors the health of your table formats, detecting schema drift and freshness issues at the metadata level, before they bleed into critical business metrics and decision-making.
- Operational health monitoring
Sifflet also supplies visibility into the maintenance side of the open stack. It alerts to missed compactions and dangerous retention changes that threaten both performance and governance.
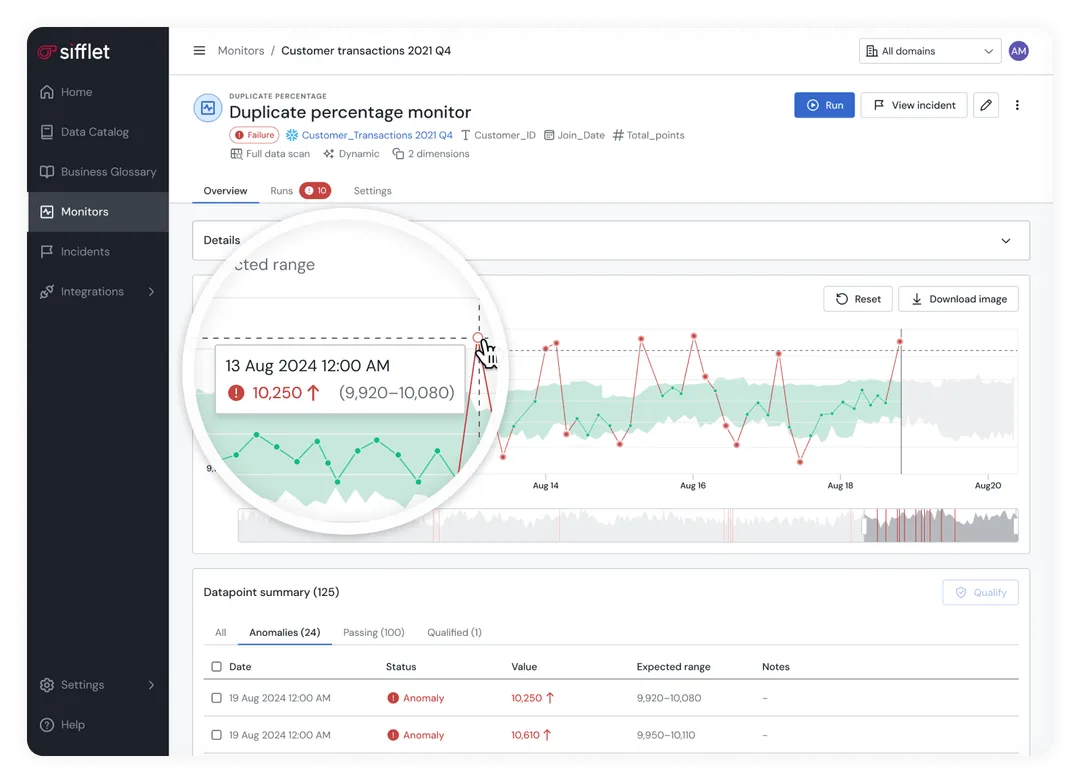
- AI-driven root cause analysis
Sifflet acts as an agentic control plane, applying ML to behavioral signals across the metadata layer. It cuts through the noise of complex lakehouse environments to provide precise, actionable root cause analysis through its three specialized AI Agents.
Sifflet transforms data observability from a passive data health check into an active architectural guardrail. It centralizes the intelligence that used to be locked inside a warehouse provider’s black box, and preserves the flexibility of a decoupled stack without the chaos of unmanaged metadata.
Control the Open Data Stack With Metadata
The shift to an Open Data Stack is a welcome move toward sovereignty and flexibility. But as the logic of your data migrates into the metadata layer, your observability strategy must evolve with it.
Operating a reliable, multi-engine lakehouse will require more than an open window into your data files. It needs a metadata-first approach that treats state changes as primary operational signals.
The Open Data Stack promises a world without walls, but it can’t be a world without guardrails.
Sifflet acts as the intelligent control plane for the modern lakehouse, turning the complexity of open metadata into a transparent, actionable asset.
By reconciling the state of your tables across every engine and catalog in real-time, Sifflet guarantees that your "best-of-breed" flexibility never comes at the cost of data reliability.
Don't let your metadata become a silent liability. As you separate storage from compute, it's time to upgrade your observability with the new source of truth: active metadata.
Don’t fly blind. See how Sifflet provides cross-engine lineage, metadata harvesting, and operational health monitoring to help you master your Open Data Stack.
Book a demo with Sifflet today or learn more about Sifflet in our Resource Hub.
















-p-500.png)
